~ Robust Audio Fingerprinting with Tarsos and Pitch Class Histograms
» By Joren on Wednesday 09 November 2011The aim of acoustic fingerprinting is to generate a small representation of an audio signal that can be used to identify or recognize similar audio samples in a large audio set. A robust fingerprint generates similar fingerprints for perceptually similar audio signals. A piece of music with a bit of noise added should generate an almost identical fingerprint as the original. The use cases for audio fingerprinting or acoustic fingerprinting are myriad: detection of duplicates, identifying songs, recognizing copyrighted material,…
Using a pitch class histogram as a fingerprint seems like a good idea: it is unique for a song and it is reasonably robust to changes of the underlying audio (length, tempo, pitch, noise). The idea has probably been found a couple of times independently, but there is also a reference to it in the literature, by Tzanetakis, 2003: Pitch Histograms in Audio and Symbolic Music Information Retrieval:
Although mainly designed for genre classification it is possible that features derived from Pitch Histograms might also be applicable to the problem of content-based audio identification or audio fingerprinting (for an example of such a system see (Allamanche et al., 2001)). We are planning to explore this possibility in the future.
Unfortunately they never, as far as I know, did explore this possibility, and I also do not know if anybody else did. I found it worthwhile to implement a fingerprinting scheme on top of the Tarsos software foundation. Most elements are already available in the Tarsos API: a way to detect pitch, construct a pitch class histogram, correlate pitch class histograms with a pitch shift,… I created a GUI application which is presented here. It is, probably, the first open source acoustic / “audio fingerprinting system based on pitch class histograms”:[AudioFingerprinter.jar].
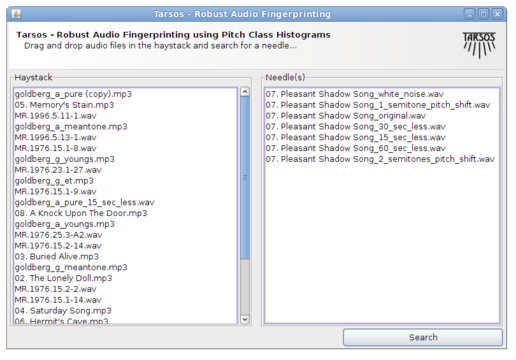
It works using drag and drop and the idea is to find a needle (an audio file) in a hay stack (a large amount of audio files). For every audio file in the haystack and for the needle pitch is detected using an optimized, for speed, Yin implementation. A pitch class histogram is created for each file, the histogram for the needle is compared with each histogram in the hay stack and, hopefully, the needle is found in the hay stack.
Unfortunately I do not have time for rigorous testing (by building a large acoustic fingerprinting data set, or an other decent test bench) but the idea seems to work. With the following modifications, done with audacity effects the needle was still found a hay stack of 836 files :
-
A 10% speedup
-
15 and 30 seconds removed form the needle (a song of 4 minutes 12 seconds)
-
White noise added
-
Reversed the audio (This is, I believe, a rather unique property of this fingerprinting technique)
-
GSM reencoded
The following modifications failed to identify the correct song:
-
A one semitone pitch shift
-
A two semitone pitch shift
-
60 seconds removed from the needle
The original was also found. No failure analysis was done. The hay stack consists of about 100 hours of western pop, the needle is also a western pop song. If somebody wants to pick up this work or has an acoustic fingerprinting data set or drop me a line at
.
The source code is available, as always, on the Tarsos GitHub page.
-

Audio Fingerprinting Results -

Audio Fingerprinting Query -

Large scale results


