I have been lucky to have been involved in an interdisciplinary research project around the low impact runner: a music based bio-feedback system to reduce tibial shock in over-ground running. In the beginning of October 2022 the PhD defence of Rud Derie takes place so it is a good moment to look back to this collaboration between several branches of Ghent University: IPEM , movement and sports science and IDLab.
The idea behind the project was to first select runners with a high foot-fall impact. Then an intervention would slightly nudge these runner to a running style with lower impact. A lower repetitive impact is expected to reduce the chance on injuries common for runners. A system was invented in which musical bio-feedback was given on the measured impact. The schema to the right shows the concept.
I was involved in development of the first hardware prototypes which measured acceleration on the legs of the runner and the development of software to receive and handle these measurement on a tablet strapped to a backpack the runner was wearing. This software also logged measurements, had real-time visualisation capabilities and allowed remote control and monitoring over the network. Finally measurements were send to a Max/MSP sonification engine. These prototypes of software and hardware were replaced during a valorization project but some parts of the software ended up in the final Android application.
Video: the left screen shows the indoor positioning system via UWB (ultra-wide-band) and the right screen shows the music feedback system and the real time monitoring of impact of the runner. Video by Pieter Van den Berghe
Over time the first wired sensors were replaced with wireless Bluetooth versions. This made the sensors easy to use and also to visualize sensor values in the browser thanks to the Web Bluetooth API. I have experimented with this and made two demos: a low impact runner visualizer and one with the conceptual schema.
Vid: Visualizing the Bluetooth Low Impact Runner sensor in the browser.
The following three studies shows a part of the trajectory of the project. The first paper is a validation of the measurement system. Secondly a proof-of-concept study is done which finally greenlights a larger scale intervention study.
Van den Berghe, P., Six, J., Gerlo, J., Leman, M., & De Clercq, D. (2019). Validity and reliability of peak tibial accelerations as real-time measure of impact loading during over-ground rearfoot running at different speeds. Journal of Biomechanics, 86, 238-242.
Van den Berghe, P., Lorenzoni, V., Derie, R., Six, J., Gerlo, J., Leman, M., & De Clercq, D. (2021). Music-based biofeedback to reduce tibial shock in over-ground running: A proof-of-concept study. Scientific reports, 11(1), 1-12.
Van den Berghe, P., Derie, R., Bauwens, P., Gerlo, J., Segers, V., Leman, M., & De Clercq, D. (2022). Reducing the peak tibial acceleration of running by music‐based biofeedback: A quasi‐randomized controlled trial. Scandinavian Journal of Medicine & Science in Sports
There are quite a number of other papers but I was less involved in those. The project also resulted in two PhD’s:
Motor retraining by real-time sonic feedback: understanding strategies of low impact running (2021) by Pieter Van den Berghe
Running on good vibes: music induced running-style adaptations for lower impact running (2022) by Rud Derie
I am also recognized as co-inventor on the low impact runner system patent and there are concrete plans for a commercial spin-off. To be continued…
The article titled “Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment” by Joren Six and Marc Leman has been accepted for publication in the Journal on Multimodal User Interfaces. The article will be published later this year. It describes and tests a method to synchronize data-streams. Below you can find the abstract, pointers to the software under discussion and an author version of the article itself.
Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment An Application of Acoustic Fingerprinting to Facilitate Music Interaction Research
Abstract:Research on the interaction between movement and music often involves analysis of multi-track audio, video streams and sensor data. To facilitate such research a framework is presented here that allows synchronization of multimodal data. A low cost approach is proposed to synchronize streams by embedding ambient audio into each data-stream. This effectively reduces the synchronization problem to audio-to-audio alignment. As a part of the framework a robust, computationally efficient audio-to-audio alignment algorithm is presented for reliable synchronization of embedded audio streams of varying quality. The algorithm uses audio fingerprinting techniques to measure offsets. It also identifies drift and dropped samples, which makes it possible to find a synchronization solution under such circumstances as well. The framework is evaluated with synthetic signals and a case study, showing millisecond accurate synchronization.
The algorithm under discussion is included in Panako an audio fingerprinting system but is also available for download here. The SyncSink application has been packaged separately for ease of use.
To use the application start it with double click the downloaded SyncSink JAR-file. Subsequently add various audio or video files using drag and drop. If the same audio is found in the various media files a time-box plot appears, as in the screenshot below. To add corresponding data-files click one of the boxes on the timeline and choose a data file that is synchronized with the audio. The data-file should be a CSV-file. The separator should be ‘,’ and the first column should contain a time-stamp in fractional seconds. After pressing Sync a new CSV-file is created with the first column containing correctly shifted time stamps. If this is done for multiple files, a synchronized sensor-stream is created. Also, ffmpeg commands to synchronize the media files themselves are printed to the command line.
This work was supported by funding by a Methusalem grant from the Flemish Government, Belgium. Special thanks goes to Ivan Schepers for building the balance boards used in the case study. If you want to cite the article, use the following BiBTeX:
@article{six2015multimodal,
author = {Joren Six and Marc Leman},
title = {{Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment}},
issn = {1783-7677},
volume = {9},
number = {3},
pages = {223-229},
doi = {10.1007/s12193-015-0196-1},
journal = {{Journal of Multimodal User Interfaces}},
publisher = {Springer Berlin Heidelberg},
year = 2015
}
A microcontroller fitted with an electret microphone and a microSD card slot. It can record audio in real-time together with sensor data.
Conceptual drawing used as a basis for the SyncSync application. A reference stream (blue) can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).
SyncSink Synchronize media files. A user-friendly interface to synchronize media and data files. First a reference media-file is added using drag-and-drop. The audio steam of the reference is extracted and plotted on a timeline as the topmost box. Subsequently other media-files are added. The offsets with respect to the reference are calculated and plotted. CSV-files with timestamps and data recorded in sync with a stream can be attached to a respective audio stream. Finally, after pressing Sync!, the data and media files are modified to be exactly in sync with the reference.
Multimodal recording system diagram. Each webcam has a microphone and is connected to the pc via USB. The dashed arrows represent analog signals. The balance board has four analog sensors but these are simplified to one connection in the schematic. The analog output of the microphones is also recorded through the DAQ. An analog accelerometer is connected with a microcontroller which also records audio.
Two streams of audio with fingerprints marked. Some fingerprints are present in both streams (green, O) while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.
Synchronized streams in Sonic Visualizer. Here you can see two channel audio synchronized with accelerometer data (top, green) and balanceboard data (bottom, purple).
The synchronized data from the two webcams, accelerometer and balanceboard in ELAN. From top to bottom the synchronized streams are two video-streams, balance-board data (red), accelerometer-data (green) and audio (black).
TarsosDSP is a real-time audio processing library written in Java. Since version 2.0 it is compatible with Android. Judging by the number of forks of the TarsosDSP GitHub repository Android compatibility increased the popularity of the library. Now the first Android application which uses TarsosDSP has found its way to the Google Play store. Download and play with SINGmaster to see an application of the pitch tracking capabilities within TarsosDSP. The SINGmaster description:
“SING master is a smart phone app that helps you to learn how to sing. SING master presents a collection of practical exercises (on the most important building blocks of melodies). Colours and sounds guide you in the exercise. After recording, SING master gives visual feedback : you can see and hear your voice. This is important so that you can identify where your mistakes are.”
Another application in the Play Store that uses TarsosDSP is CuePitcher.
TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbor search algorithm for high dimensional vectors that operates in sublinear time. The open source software package is authored by me and is available on GitHub: TarsosLSH on GitHub.
With TarsosLSH, Joseph Hwang and Nicholas Kwon from Rice University created an Image Mosaic web application. The application chops an uploaded photo into small blocks. For each block, a color histogram is created and compared with an index of color histograms of reference images. Subsequently each block is replaced with one of the top three nearest neighbors, creating a mosaic. Since high dimensional nearest neighbor search is needed, this is an ideal application for TarsosLSH. The application somewhat proves that TarsosLSH can be used in practical applications, which is comforting.
The Starry Night, by Van Ghogh in Mosaic as created by the mosaic webapplication.
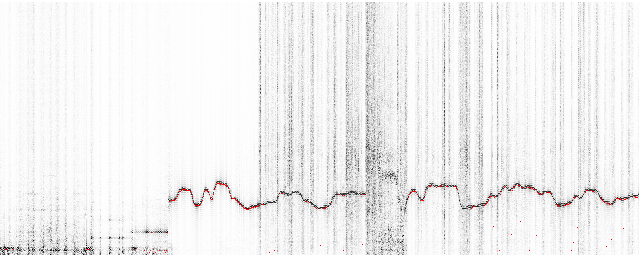
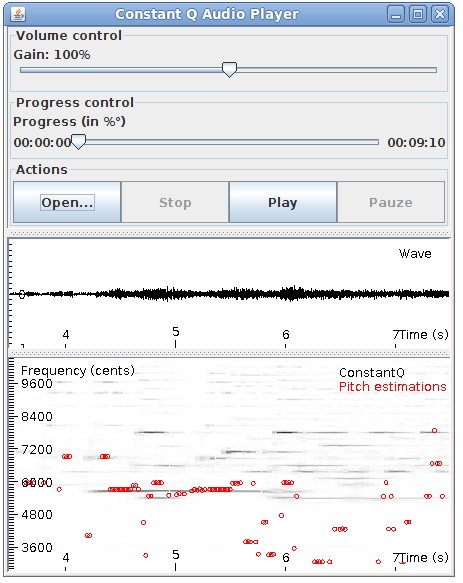
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a Constant-Q Transform (as of version 1.6). The Constant-Q transform does essentially the same thing as an FFT, but has the advantage that each octave has the same amount of bins. This makes the Constant-Q transform practical for applications processing music. If, for example, 12 bins per octave are chosen, these can correspond with the western musical scale.
Also included in the newest release (version 1.7) is a way to visualize the transform, or other musical features. The visualization implementation is done together with Thomas Stubbe.
The example application below shows the Constant-Q transform with an overlay of pitch estimations. The corresponding waveform is also shown.
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of the Journal of New Music Research (JNMR) on the 20th of august 2013. Below you can find the abstract for the article, and pointers to audio examples, the Tarsos software, and the author version of the article itself.
Abstract: This paper presents Tarsos, a modular software platform used to extract and analyze pitch organization in music. With Tarsos pitch estimations are generated from an audio signal and those estimations are processed in order to form musicologically meaningful representations. Tarsos aims to offer a flexible system for pitch analysis through the combination of an interactive user interface, several pitch estimation algorithms, filtering options, immediate auditory feedback and data output modalities for every step. To study the most frequently used pitches, a fine-grained histogram that allows up to 1200 values per octave is constructed. This allows Tarsos to analyze deviations in Western music, or to analyze specific tone scales that differ from the 12 tone equal temperament, common in many non-Western musics. Tarsos has a graphical user interface or can be launched using an API - as a batch script. Therefore, it is fit for both the analysis of individual songs and the analysis of large music corpora. The interface allows several visual representations, and can indicate the scale of the piece under analysis. The extracted scale can be used immediately to tune a MIDI keyboard that can be played in the discovered scale. These features make Tarsos an interesting tool that can be used for musicological analysis, teaching and even artistic productions.
Ladrang Kandamanyura (slendro pathet manyura), is the name of the piece used in the article throughout section 2. The album on which the piece can be found is available at wergo. Below a thirty second fragment is embedded. You can also “download”:[08._Ladrang_Kandamanyura_10s-20s_up.wav] the thirty second fragment to analyse it yourself.
Below the BibTex entry for the article is embedded.
```ruby\
\@article{six2013tarsos_jnmr,\
author = {Six, Joren and Cornelis, Olmo and Leman, Marc},\
title = {Tarsos, a Modular Platform for Precise Pitch Analysis\
of Western and Non-Western Music},\
journal = {Journal of New Music Research},\
volume = {42},\
number = {2},\
pages = {113-129},\
year = {2013},\
doi = {10.1080/09298215.2013.797999},\
URL = {http://www.tandfonline.com/doi/abs/10.1080/09298215.2013.797999}\
}\
```
In the extended abstract, also titled “Computer Assisted Transcription of Ethnic Music”:[FMA_2013.computer_assisted_transcription.pdf], it is described how the Tarsos software program now has features aiding transcription. Tarsos is especially practical for ethnic music of which the tone scale is not known beforehand. The proceedings of FMA 2013 are available as well.
"":\[A0-Poster.jpg\]
During the conference there also was an interesting panel on transcription. The following people participated: John Ashley Burgoyne, moderator (University of Amsterdam), Kofi Agawu (Princeton University), Dániel P. Biró (University of Victoria), Olmo Cornelis (University College Ghent, Belgium), Emilia Gómez (Universitat Pompeu Fabra, Barcelona), and Barbara Titus (Utrecht University). Some pictures can be found below.
TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbour search algorithm for multidimensional vectors that operates in sublinear time. It supports several Locality Sensitive Hashing (LSH) families: the Euclidean hash family (L2), city block hash family (L1) and cosine hash family. The library tries to hit the sweet spot between being capable enough to get real tasks done, and compact enough to serve as a demonstration on how LSH works. It relates to the Tarsos project because it is a practical way to search for and compare musical features.
<code>git clone https://JorenSix@github.com/JorenSix/TarsosLSH.git
cd TarsosLSH/build
ant #Builds the core TarsosLSH library
ant javadoc #build the API documentation
</code>
\
When everything runs correctly you should be able to run the command line application, and have the latest version of the TarsosLSH library for inclusion in your projects. Also, the Javadoc documentation for the API should be available in TarsosLSH/doc. Drop me a line if you use TarsosLSH in your project. Always nice to hear how this software is used.
The fastest way to get something on your screen is executing this on your command line: java - jar TarsosLSH.jar this lets LSH run on a random data set. The full reference of the command line application is included below:
Name
TarsosLSH: finds the nearest neighbours in a data set quickly, using LSH.
Synopsis
java - jar TarsosLSH.jar [options] dataset.txt queries.txt
Description
Tries to find nearest neighbours for each vector in the
query file, using Euclidean (L2) distance by default.
Both dataset.txt and queries.txt have a similar format:
an optional identifier for the vector and a list of N
coordinates (which should be doubles).
[Identifier] coord1 coord2 ... coordN
[Identifier] coord1 coord2 ... coordN
For an example data set with two elements and 4 dimensions:
Hans 12 24 18.5 -45.6
Jane 13 19 -12.0 49.8
Options are:
-f cos|l1|l2
Defines the hash family to use:
l1 City block hash family (L1)
l2 Euclidean hash family(L2)
cos Cosine distance hash family
-r radius
Defines the radius in which near neighbours should
be found. Should be a double. By default a reasonable
radius is determined automatically.
-h n_hashes
An integer that determines the number of hashes to
use. By default 4, 32 for the cosine hash family.
-t n_tables
An integer that determines the number of hash tables,
each with n_hashes, to use. By default 4.
-n n_neighbours
Number of neighbours in the neighbourhood, defaults to 3.
-b
Benchmark the settings.
--help
Prints this helpful message.
Examples
Search for nearest neighbours using the l2 hash family with a radius of 500
and utilizing 5 hash tables, each with 3 hashes.
java - jar TarsosLSH.jar -f l2 -r 500 -h 3 -t 5 dataset.txt queries.txt
Source Code Organization
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
Further Reading
This section includes a links to resources used to implement this library.
The LSH-page maintained by Alexandr Andoni contains pointers to good resources:
Locality-Sensitive Hashing Scheme Based on p-Stable Distributions a chapter by Alexandr Andoni, Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab Mirrokni which appeared in the book Nearest Neighbor Methods in Learning and Vision: Theory and Practice, by T. Darrell and P. Indyk and G. Shakhnarovich (eds.), MIT Press, 2006.
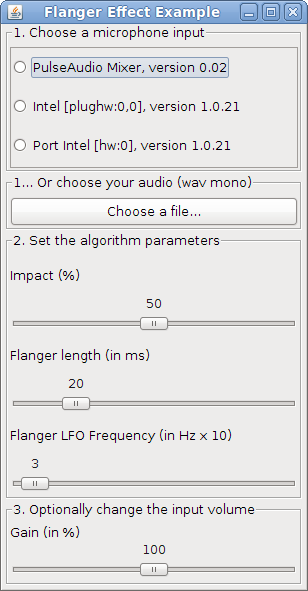
The DSP library for Taros, aptly named TarsosDSP, now includes an example demonstrating the flanging audio effect. Flanging, essentialy mixing the signal with a varying delay of itself, produces an interesting interference pattern.
The flanging example works on wav-files or on input from microphone. Try it yourself, download\
Flanging.jar, the executable jar file. Below you can check what flanging sounds like with various parameters.
The source code of the Java implementation can be found on the TarsosDSP github page.
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize cat sounds. The inspration came from this youtube video
To hear what exactly it does, listen to the following audio example.
There is also a command line interface, the following command does
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize pitch estimations. The goal of the example is to show which errors are made by different pitch detectors.
To test the application, download and execute the Resynthesizer.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To hear what exactly it does, compare the following two audio fragments:
There is also a command line interface, the following command does pitch tracking, and follows the envelope of in.wav and immediately plays it on the default audio device. If you want to save the audio, see the command line options. The “flute example”:[flute.wav] is provided for your convenience.
\
java -jar Resynthesizer-latest.jar in.wav\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP resynthesizer
----------------------------------------------------
Synopsis:
java -jar CommandLineResynthesizer.jar [--detector DETECTOR] [--output out.wav] [--combined combined.wav] input.wav
----------------------------------------------------
Description:
Extracts pitch and loudnes from audio and resynthesises the audio with that information.
The result is either played back our written in an output file.
There is als an option to combine source and synthezized material
in the left and right channels of a stereo audio file.
input.wav a readable wav file.
--output out.wav a writable file.
--combined combined.wav a writable output file. One channel original, other synthesized.
--detector DETECTOR defaults to FFT_YIN or one of these:
YIN
MPM
FFT_YIN
DYNAMIC_WAVELET
AMDF
The source code of the Java implementation of the synthesizer can be found on the TarsosDSP github page.
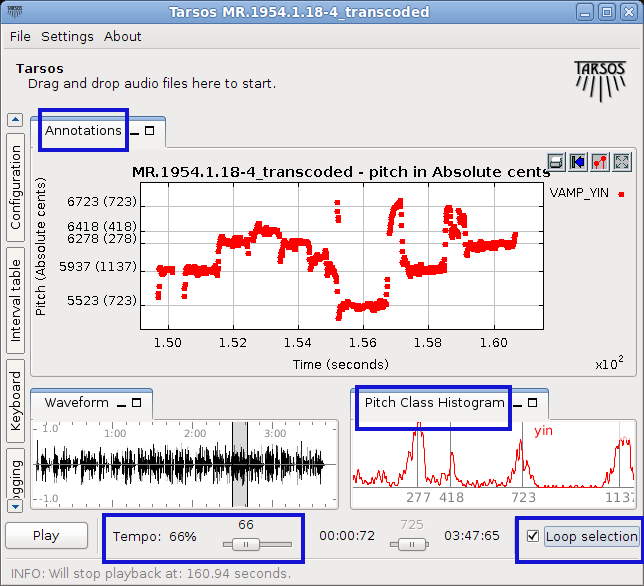
Today marks the reslease of Tarsos 1.0 . The new Tarsos release contains practical transcription features. As can be seen in the screenshot below, a time stretching feature makes it easy to loop a certain audio fragment while it is playing in a slow tempo. The next loop can be played with by pressing the n key, the one before by pressing b.
Since the pitch classes can be found in a song, and there is a feature that lets you play a MIDI keyboard in the tone scale of the song under analysis, transcription of ethnic music is made a lot easier.
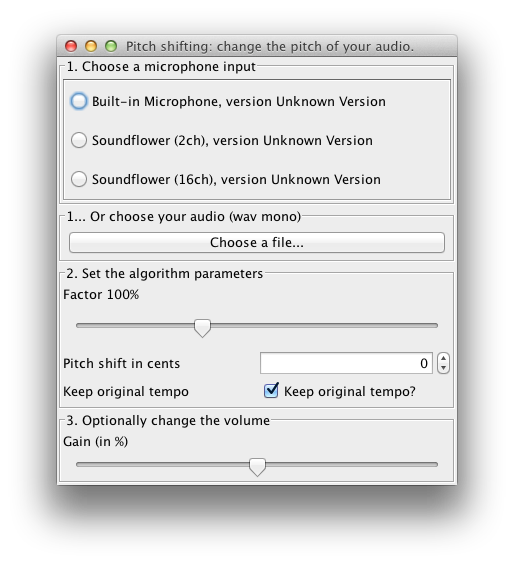
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4). The goal of pitch shifting is to change the pitch of a piece of audio without affecting the duration. The algorithm implemented is a combination of resampling and time stretching. Resampling changes the pitch of the audio, but affects the total duration. Consecutively, the duration of the audio is stretched to the original (without affecting pitch) with time stretching. The result is very similar to phase vocoding.
The example application below shows how to pitch shift input from the microphone in real-time, or pitch shift a recorded track with the TarsosDSP library.
To test the application, download and execute the PitchShift.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command lowers the pitch of in.wav by two semitones.
java -jar in.wav out.wav -200
----------------------------------------------------
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Pitch shifting utility.
----------------------------------------------------
Synopsis:
java -jar PitchShift.jar source.wav target.wav cents
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the pitch shifted file.
cents Pitch shifting in cents: 100 means one semitone up,
-100 one down, 0 is no change. 1200 is one octave up.
The resampling feature was implemented with libresample4j by Laszlo Systems. libresample4j is a Java port of Dominic Mazzoni’s libresample 0.1.3, which is in turn based on Julius Smith’s Resample 1.7 library.
At this years ICMC Conference, ICMC 2012 we presented a paper describing a way to experiment with tone scales and how to use Tarsos as a compositional tool. What follows are some pointers to the presentation, paper and to other interesting talks that were presented there.
ICMC 2012 was organized in Ljubljana from the 9 to 14 septembre and had a very dense program of talks, posters, presentations, demos and concerts.
Since 1974 the International Computer Music Conference has been the major international forum for the presentation of the full range of outcomes from technical and musical research, both musical and theoretical, related to the use of computers in music. This annual conference regularly travels the globe, with recent conferences in the Americas, Europe and Asia. This year we welcome the conference to Slovenia for the first time.
### Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition
Our contribution to the conference was a paper titled “Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition”:[icmc2012_submission_45.pdf].
If you want to cite our work, this BibTeX entry is included for your convenience:
```ruby\
\@inproceedings{cornelis2012sound_to_scale,\
author = {Olmo Cornelis and Joren Six},\
title = {{Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition}},\
booktitle = {{Proceedings of the 2012 International Computer Music Conference,\
(ICMC 2012)}},\
year = {2012},\
publisher = {The International Computer Music Association}\
}\
```
Program highlights
What follows are a number of pointers to my personal program highlights.
Verena Thomas presented two very well polished software tools. One to detect patterns in scores, called motifviewer and a tool to search in score databases in a multi-modal way. The Probado tool does score-to-audio alignment and much more.
Gibber is an impressive live-coding environment with an easy syntax. Since it is all done with javascript you can start playing with it immediately. Overtone Another live-coding environment, presented at the conference by Sam Aaron, was equally impressive. It is programmed using the Closure language.
At ICMC there were a number of tools to assist in composition. One of those is The Bach Project, by Andrea Agostini. Togheter with CatART by Diemo Swartz it forms a very expressive platform to work with sound, which was demonstrated by Aaron Einbond and Christopher Trapani in their paper titled Precise Pitch Control In Real Time Corpus-Based Concatenative Synthesis. Diemo Swartz presented work on Audio Mosaicing, it can be seen as a follow-up to AuidioGuild by Ben Hackbarth.
I also got to know the work by Thomas Grill, on his website a nice piece of software can be found a Python implementation of the Non Stationary Gabor Transform (NSGT). Another software system I got to know is the functional signal processing programming language FAUST
My personal highlights of the concert programme include the works by Johannes Kreidler, Aura Pon, Daniel Mayer, Alexander Schubert and the remarkable performance by Dexter Ford. The concept behind Soundlog by Johannes Kretz was also interesting.
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
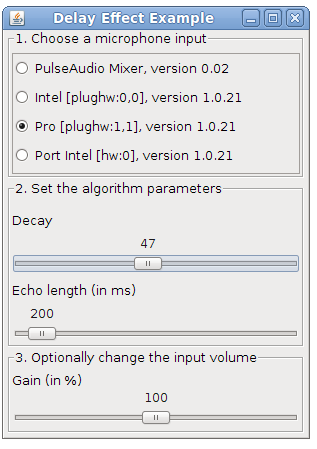
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of an audio echo effect. An echo effect is very simple to implement digitally and can serve as a good example of a DSP operation.
"":\[Delay.jar\]
The implementation of the effect can be seen below. As can be seen, to achieve an echo one simply needs to mix the current sample i with a delayed sample present in echoBuffer with a certain decay factor. The length of the buffer and the decay are the defining parameters for the sound of the echo. To fill the echo buffer the current sample is stored (line 4). Looping through the echo buffer is done by incrementing the position pointer and resetting it at the correct time (lines 6-9).
```java\
//output is the input added with the decayed echo\
audioFloatBuffer[i] = audioFloatBuffer[i] + echoBuffer[position] * decay;\
//store the sample in the buffer;\
echoBuffer[position] = audioFloatBuffer[i];\
//increment the echo buffer position\
position;\
//loop in the echo buffer\
if(position == echoBuffer.length)\
position = 0;\
```
To test the application, download and execute the “Delay.jar”:[Delay.jar] file and start singing in a microphone.
The source code of the Java implementation can be found on the TarsosDSP github page.
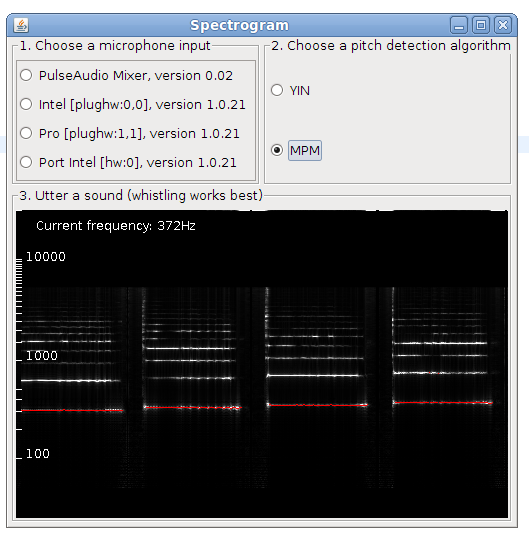
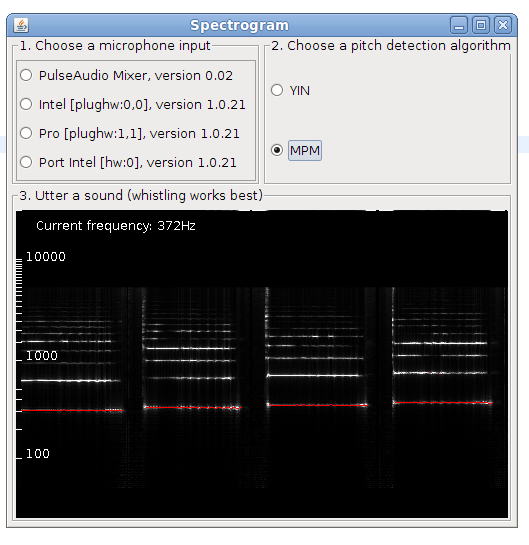
This is post presents a better version of the spectrogram implementation. Now it is included as an example in TarsosDSP, a small java audio processing library. The application show a live spectrogram, calculated using an FFT and the detected fundamental frequency (in red).
To test the application, download and execute the “Spectrogram.jar”:[Spectrogram.jar] file and start singing in a microphone.
There is also a command line interface, the following command shows the spectrum for in.wav:
\
java -jar Spectrogram.jar in.wav\
The source code of the Java implementation can be found on the TarsosDSP github page.
To test the application, download and execute the “WSOLA jar”:[TimeStretch.jar] file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command doubles the speed of in.wav:
\
java -jar TimeStretch.jar in.wav out.wav 2.0\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Time stretch utility.
----------------------------------------------------
Synopsis:
java -jar TimeStretch.jar source.wav target.wav factor
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the time stretched file.
factor Time stretching factor: 2.0 means double the length, 0.5 half. 1.0 is no change.
The source code of the Java implementation of WSOLA can be found on the TarsosDSP github page.
Tarsos contains a couple of useful command line applications. They can be used to execute common tasks on lots of files. Dowload Tarsos and call the applications using the following format:
The first part java -jar tarsos.jar tells the Java Runtime to start the correct application. The first argument for Tarsos defines the command line application to execute. Depending on the command, required arguments and options can follow.
To get a list of available commands, type java -jar tarsos.jar -h. If you want more information about a command type java -jar tarsos.jar command -h
Detect Pitch
Detects pitch for one or more input audio files using a pitch detector. If a directory is given it traverses the directory recursively. It writes CSV data to standard out with five columns. The first is the start of the analyzed window (seconds), the second the estimated pitch, the third the saillence of the pitch. The name of the algorithm follows and the last column shows the original filename.
The goal of the thesis was to develop an automatic transcription system for monophonic music. You can download the latest version of jAM - Java Automatic Music Transcription.
WORKSHOP - Muziek (ont)luisteren op de computer\
Is het mogelijk om piano te spelen op een tafel? Kan een computer luisteren naar muziek en er van genieten? Wat is muziek eigenlijk, en hoe werkt geluid? \
Tijdens deze workshop worden de voorgaande vragen beantwoord met enkele computerprogramma's!
Concreet worden enkele componenten van geluid (en bij uitbreiding, muziek) gedemonstreerd met computerprogrammaatjes gemaakt in het conservatorium:
“Geluidssterkte”:[SoundDetector.jar]: een decibel-meter met een bepaalde drempelwaarde. Probeer zo luid mogelijk te doen en zie hoe moeilijk het is om, eens een bepaald niveau bereikt is, in decibel te stijgen.
“Toonhoogte”:[UtterAsterisk.jar]: een klein spelletje om toonhoogte aan te tonen. Probeer zo juist mogelijk te zingen of te fluiten en vergelijk je score.
“Percussie”:[PercussionDetector.jar]: dit programma reageert op handgeklap. Hoe kan je het onderscheid maken tussen bijvoorbeeld een fluittoon en handgeklap?
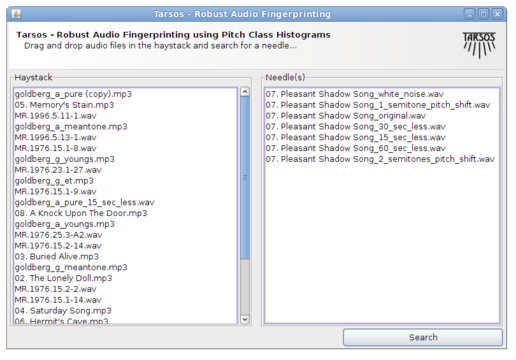
The aim of acoustic fingerprinting is to generate a small representation of an audio signal that can be used to identify or recognize similar audio samples in a large audio set. A robust fingerprint generates similar fingerprints for perceptually similar audio signals. A piece of music with a bit of noise added should generate an almost identical fingerprint as the original. The use cases for audio fingerprinting or acoustic fingerprinting are myriad: detection of duplicates, identifying songs, recognizing copyrighted material,…
Using a pitch class histogram as a fingerprint seems like a good idea: it is unique for a song and it is reasonably robust to changes of the underlying audio (length, tempo, pitch, noise). The idea has probably been found a couple of times independently, but there is also a reference to it in the literature, by Tzanetakis, 2003: Pitch Histograms in Audio and Symbolic Music Information Retrieval:
Although mainly designed for genre classification it is possible that features derived from Pitch Histograms might also be applicable to the problem of content-based audio identification or audio fingerprinting (for an example of such a system see (Allamanche et al., 2001)). We are planning to explore this possibility in the future.
Unfortunately they never, as far as I know, did explore this possibility, and I also do not know if anybody else did. I found it worthwhile to implement a fingerprinting scheme on top of the Tarsos software foundation. Most elements are already available in the Tarsos API: a way to detect pitch, construct a pitch class histogram, correlate pitch class histograms with a pitch shift,… I created a GUI application which is presented here. It is, probably, the first open source acoustic / “audio fingerprinting system based on pitch class histograms”:[AudioFingerprinter.jar].
It works using drag and drop and the idea is to find a needle (an audio file) in a hay stack (a large amount of audio files). For every audio file in the haystack and for the needle pitch is detected using an optimized, for speed, Yin implementation. A pitch class histogram is created for each file, the histogram for the needle is compared with each histogram in the hay stack and, hopefully, the needle is found in the hay stack.
Unfortunately I do not have time for rigorous testing (by building a large acoustic fingerprinting data set, or an other decent test bench) but the idea seems to work. With the following modifications, done with audacity effects the needle was still found a hay stack of 836 files :
A 10% speedup
15 and 30 seconds removed form the needle (a song of 4 minutes 12 seconds)
White noise added
Reversed the audio (This is, I believe, a rather unique property of this fingerprinting technique)
GSM reencoded
The following modifications failed to identify the correct song:
A one semitone pitch shift
A two semitone pitch shift
60 seconds removed from the needle
The original was also found. No failure analysis was done. The hay stack consists of about 100 hours of western pop, the needle is also a western pop song. If somebody wants to pick up this work or has an acoustic fingerprinting data set or drop me a line at
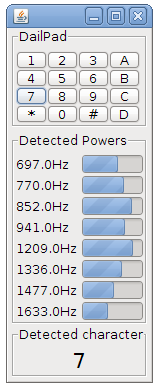
The DSP library of Tarsos, aptly named TarsosDSP, now contains an implementation of the Goertzel Algorithm. It is implemented using pure Java.
The Goertzel algorithm can be used to detect if one or more predefined frequencies are present in a signal and it does this very efficiently. One of the classic applications of the Goertzel algorithm is decoding the tones generated on by touch tone telephones. These use DTMF (Dual tone multi frequency)-signaling.
To make the algorithm visually appealing a Java Swing interface has been created(visible right). You can try this application by running the “Goertzel DTMF Jar-file”:[GoertzelDTMF.jar]. The souce code is included in the jar and is avaliable as a separate “zip file”:[GoertzelDTMF_src.zip]. The TarsosDSP github page also contains the source for the Goertzel algorithm Java implementation.
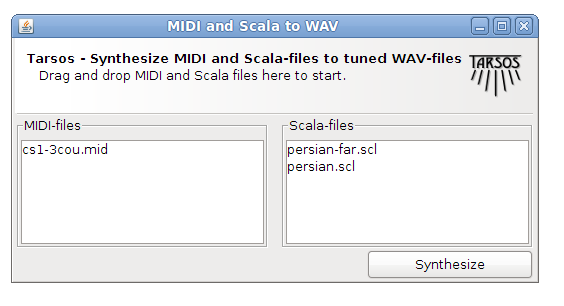
Tarsos can be used to render MIDI files to audio (WAV) files using arbitrary tone scales. This functionallity can be used to (automatically) verify tone scale extraction from audio files. Since I could not find a dataset with audio and corresponding tone scales creating one using MIDI seemed a good idea.
MIDI files can be found in spades (for example on piano-midi.de or kunstderfuge.com), tone scales on the other hand are harder to find. Luckily there is one massive source, the Scala Tone Scale Archive: A large collection of over 3700 tone scales.
Using Scala tone scale files and a midi files a Tone Scale - Audio dataset can be generated. The quality of the audio depends on the (software) synthesizer and the SoundFont used. Tarsos currently uses the Gervill synthesizer. Gervill is a pure Java software synthesizer with support for 24bit SoundFonts and the MIDI tuning standard.\
How To Render MIDI Using Arbitrary Tone Scales with Tarsos
A recent version of the JRE (Java Runtime Environment) needs to be installed on your system if you want to use Tarsos. Tarsos itself can be downloaded in the form of the “MIDI and Scala to Wav - JAR Package”:[MidiToWav.jar].
To test the program you can use “a MIDI file”:[MIDI_file.mid] and “a Scala file”:[persian.scl.txt] and drag and drop those on the graphical interface.
The result should sound like this:
To summarize: by rendering audio with MIDI and Scala tone scale files a dataset with tone scale - audio information can be generated and tone scale extraction algorithms can be tested on the fly.
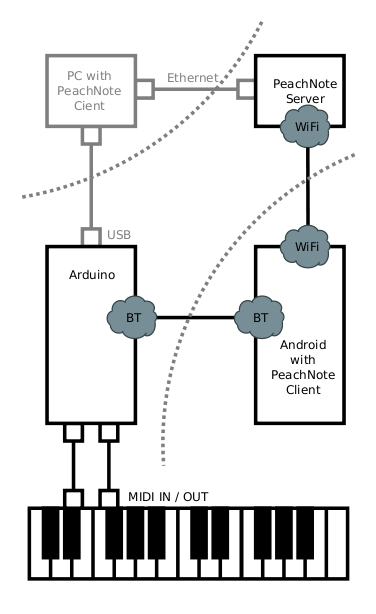
This is about PeachNote Piano, a project only tangentially related to Tarsos. PeachNote Piano aims to capture as many piano practice sessions as possible and offer useful services using this data. The system does this by capturing and redirecting MIDI events on a Bluetooth enabled smartphone. It is done together with Vladimir Viro and builds on the existing PeachNote infrastructure.
The schema - right - shows the components of the PeachNote Piano system. At the bottom you have a MIDI keyboard connected to the MIDI-Bluetooth-bridge. A smartphone (middle left) receives these MIDI events via Bluetooth and controls the communication to the server (top left). An alternative path goes through a standard computer (top right).
The Arduino based Bluetooth to MIDI bridge is an improvement on the work by Peter Brinkmann. The video below shows communication between USB-MIDI, Bluetooth MIDI and MIDI IN/OUT ports.
As an example application of the PeachNote Piano system we implemented a “Continue a Melody” service which works as follows: a user plays something on a keyboard, maybe just a few notes, and pauses for a few seconds. In the meantime, the server searches through a large database of MIDI piano recordings, finds the longest fuzzy match for the user’s most recent input, and, after a short silence on the users part, starts streaming the continuation of the best matched performance from the database to the user. This mechanism, in fact, is way of browsing a music collection. Users may play a known leitmotiv or just improvise something, and the system continues playing a high quality recording, “replying” to the musical proposition of the user.
More technical details
The melody matching is done on the server, which is implemented in Javascript in the Node.js framework. The whole dataset (about 350 hours of piano recordings) resides in memory in two representations: as a sequence of pitches, and as a sequence of “densities” at the corresponding places of the pitch sequence dataset. This second array is used to store the rough tempo information (number of notes per second) absent in the pitch sequence data.\
By combining the two search criteria we can achieve reasonable approximation of the tempo-aware search without its computational complexity.
The implementation of the hardware is based on the open-source electronic prototyping platform Arduino. Optocoupled MIDI ports (IN/OUT) and the BlueSMiRF Bluetooth module were attached to the main board, as can be seen in the middle left block of the schema. The BlueTooth module is configured to use the Serial Port Profile (SPP) which emulates RS-232. The software on the Arduino manages bi-directional, low latency message passing between three serial ports: USB (through an FTDI chip), BlueTooth and the hardware MIDI-IN and OUT port.
The standard Arduino firmware has been replaced with firmware that implements the “Universal Serial Bus Device Class Definition for MIDI Devices”: when attached to a computer via USB, the Arduino shows up as a standard MIDI device, which makes it compatible with all available MIDI software. The software client currently works on the Android smartphone platform. It is represented using the middle right block in the schema. The client can send and receive MIDI events over its Bluetooth port. Pairing, connecting and communicating with the device is done using the Amarino software library. The client communicates with the Peachnote Piano server using TCP sockets implemented on the Dalvik Java runtime.
This article describes how to do makam recognition with a script that uses the Tarsos API.
The task we want to do is to find the tone scales most similar to the one used in recorded music. To complete this task you need a small set of theoretical scales and a large set of music, each brought in one of the scales. To make it more concrete, an example of Turkish classical music is used.
In an article by Bozkurt pitch histograms are used for - amongst other tasks - makam recognition. A maqam defines rules for a composition or performance of classical Turkish music. It specifies melodic shapes and pitch intervals, the scale. The task is to identify which of nine makams is used in a specific song. A simplified, generalized implementation of this task is shown here. In our implementation there is no tonic detection step. Also here we use only theoretical descriptions of the tone scales as a template and do not construct a template using the audio itself, as is done by Bozkurt. Ioannidis Leonidas wrote an interesting master thesis about makam recognition. Since no knowledge of the music itself is used the approach is generally applicable.
The following is an implementation in Scala a general purpose programming language that is interoperable with Jave . The first step is to write the Scala header. This is just some boilerplate code to be able to run the script from the command line - it assumes a UNIX-like environment and tarsos.jar in the same directory:
The second step constructs the templates the capability of Tarsos to create\
theoretical tone scale templates using Gaussian kernels is used, line 8. See the attached images for some examples.
```ruby\
val makams = List( “hicaz”,”huseyni”,”huzzam”,”kurdili_hicazar”,\
“nihavend”,”rast”,”saba”,”segah”,”ussak”)
var theoreticKDEs = Map[java.lang.String,KernelDensityEstimate]()\
makams.foreach{ makam =>\
val scalaFile = makam + “.scl”\
val scalaObject = new ScalaFile(scalaFile);\
val kde = HistogramFactory.createPichClassKDE(scalaObject,35)\
kde.normalize\
theoreticKDEs = theoreticKDEs + (makam -> kde)\
}\
```
The third and last step is matching. First a list of audio\
files is created by recursively iterating a directory and matching each file to\
a regular expression. Next, starting from line 4, each audio file is processed.\
The internal implementation of the YIN pitch detection\
algorithm is used on the audio file and a pitch class histogram is created\
(line 6,7). On line 10 normalization of the histogram is done, to\
make the correlation calculation meaningful. Line 11 until 15 compare the\
created histogram from the audio file with the templates calculated beforehand.\
The results are stored, ordered and eventually printed on line 19.
```ruby\
val directory = “/home/joren/turkish_makams/”\
val audio_pattern = “.*.(mp3|wav|ogg|flac)”\
val audioFiles = FileUtils.glob(directory,audio_pattern,true).toList
audioFiles.foreach{ file =>\
val audioFile = new AudioFile(file)\
val detectorYin = PitchDetectionMode.TARSOS_YIN.getPitchDetector(audioFile)\
val annotations = detectorYin.executePitchDetection()\
val actualKDE = HistogramFactory.createPichClassKDE(annotations,15);\
actualKDE.normalize\
var resultList = List[Tuple2[java.lang.String,Double]]()\
for ((name, theoreticKDE) <- theoreticKDEs){\
val shift = actualKDE.shiftForOptimalCorrelation(theoreticKDE)\
val currentCorrelation = actualKDE.correlation(theoreticKDE,shift)\
resultList = (name -> currentCorrelation) :: resultList\
}\
//order by correlation\
resultList = resultList.sortBy{_._2}.reverse\
Console.println(file + “ is brought in tone scale “ + resultList(0)._1)\
}\
```
A complete version of this script can is available: “Tone scale matching script”:[guess_makam.scala] Results of the script when ran on Bozkurt’s dataset can be seen in the attached spreadsheet (“openoffice format”:[makam_recognition_results.ods] or “excel format”:[makam_recognition_results.xls]).
Theoretical template
Other theoretical template
Actual Hicaz song overlayed with a theoretical template
Tarsos, a software package to analyse pitch organization in music, contains a new output modality. It is now possible to export a pitch class histogram and a pitch class interval matrix to latex from within Tarsos. This makes documenting tone scales more efficient.
An example for “a pitch class histogram and pitch class interval matrix”:[latex_export.pdf] can be seen. Also available is the “latex source code”:[latex_export.tex].
Tarsos, a software package to analyse pitch organization in music, contains a new output modality. Now it is possible to export resynthesized pitch annotations, detected by a pitch detection algorithm and compare those with the original sound. This can be interesting to see which errors a pitch detection algorithm makes.
Below you can listen to an example of synthesized pitch detection results compared with the original flute piece. The file starts with only the original flute sound (on the right channel) and gradually changes so only the synthesized annotations (on the left channel) can be heard.
This article describes how to make sun-java6 play nice with the PulseAudio sound sytem on Ubuntu with an x64 processor architecture. With some changes the method should also work with other operating systems and other platforms.
The default way sun-java6 operates with respect to sound on Ubuntu is, well unrespectfull. When playing audio it claims an audio device, which then can not be used any more by other applications trying to access the same device. This is far from ideal. Also changing audio interfaces (by e.g. plugging in a USB audio interface) goes wrong most of the time.
These problems are addressed by PulseAudio and there is a way to make sun-java6 aware of PulseAudio on Ubuntu. The OpenJDK does this automatically but it has some other, unrelated, issues. If you want to use PulseAudio with java6 on Ubuntu x64 you need copy “pulse-java.jar”:[pulse-java.jar] and platform dependent “libpulse-java.so”:[libpulse-java.so] file to correct JVM directories. To make it easy you can execute these commands:
From this moment on the “PulseAudio Mixer” is available for Java applications. Sharing, switching and assigning audio devices to Java programs is as a result smooth. To use the PulseAudio Mixer by default you need to change sound.properties which can be found at /usr/lib/jvm/java-6-sun/jre/lib/sound.properties. Details can be found here.
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method.
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in JAVA.
To make some of the possibilities clear I coded some examples.
“TarsosDSP UtterAsterisk”:[UtterAsterisk.jar] a game that shows real-time pitch detection with YIN.
“TarsosDSP Sound Detector”:[SoundDetector.jar] is simply to show how to react when (loud) sound is available.
“TarsosDSP Percussion Detector”:[PercussionDetector.jar] is capable of detecting percussion onsets using the method described here. It plays a sound from freesound.org when percussion is detected.
Saturday the 25th of March TarsosDSP was presented at Newline, a small conference organized by whitespace. Here you can download “the slides I used to present TarsosDSP”:[tarsosDSP_presentation.pdf], I also created “an introductory text on sound and Java”:[sound_and_java.pdf].
There is more to Tarsos then meets te eye. The graphical user interface only exposes some functionality; the API (Application Programmer Interface) exposes all of Tarsos’ capabilities.
Tarsos is programmed in Java so the API is accessible trough Java and other programming languages targeting the JVM (Java Virtual Machine) like JRuby, Scala and Groovy. The following examples use the Groovy programming language because I find it the most aesthetically pleasing with regards to interoperability and it gets the job done without getting in your way.
To run the examples a copy of the Tarsos JAR-file needs to be added to the Classpath and the Groovy runtime must be installed correctly. I’ll leave this as an exercise for the reader: godspeed to you, brave soul. Quick protip: placing a copy of the jar in the extensions directory seems to work best, e.g. see important java directories on mac OS X.
The first example extracts pitch class histograms from a bunch of files and saves them as EPS (Encapsulated PostScript)-files. It iterates a directory recursively and handles each file that matches a given regular expression. In this example the regular expression matches all WAV-files. Batch processing is one of those things scripting is ideal for, doing the same thing with the user interface would be tedious or even mind-numbingly boring, not groovy at all indeed.
FileUtils.glob(dir,”.*.wav”,true).each { file ->\
audioFile = new AudioFile(file)\
pitchDetector = PitchDetectionMode.TARSOS_YIN.getPitchDetector(audioFile)\
pitchDetector.executePitchDetection()\
//get some annotations\
annotations = pitchDetector.getAnnotations()\
//create an ambitus and tone scale histogram\
ambitusHistogram = Annotation.ambitusHistogram(annotations)\
toneScaleHisto = ambitusHistogram.toneScaleHistogram()\
//plot a smoothed version of the histogram\
p = new SimplePlot()\
p.addData 0, toneScaleHisto.gaussianSmooth(0.2)\
p.save FileUtils.basename( file) + “.eps”\
}\
```
The second example uses functionality that is currently only available trough the API. It takes a MIDI-file and synthesizes it to a wave file using an arbitrary scale. In this case 10-TET. The heavy-work is done by the Gervill synthesizer. The resulting file is available for download, micro—macro?—tonal Bach is great: “BWV 1013 in 10-TET”:[BWV_1013_10-TET.mp3]. The result of “an analysis with Tarsos on the synthesized audio”:[120.png] clearly shows an interval of 120 cents with some deviations.
midiFile = new File(“BWV_1013.mid”)\
outFile = new File(“out.wav”)
tuning = [0,120,240,360,480,600,720,840,960,1080] as double []
MidiToWavRenderer renderer\
renderer = new MidiToWavRenderer()\
renderer.setTuning(tuning)\
renderer.createWavFile(midiFile, outFile)\
```
An extended version of this second example script could be used to generate a dataset with audio and corresponding tone scale information on the fly. The dataset could then be used as a baseline.
The API is not yet well documented and is still in flux or more correctly: superflux. Note to self: I will provide documentation and a number of useful examples when the dust settles down. I’m not even sure if I will stick with Groovy. Scala has a nice Lispy feel to it and seems more developed. Groovy has a less steep learning curve, especially if you have some experience with Ruby. JRuby is also nice but the interoperability with legacy Java looks like an ugly hack.
Drag and drop works for scala tone scale files and different kinds of audio files. Audiofiles are transcoded automagically using an embedded ffmpeg binary which is platform dependend. It works on linux and windows, on other platforms only WAV files are supported.
Some of the current features:
Scala file extraction from audio
Real time pitch tracking
Real time pitch class histogram visualization
Alignment of pitch intervals with histogram using mouse dragging
Tarsos is now capable of reproducing speech using MIDI. The idea to convert speech into MIDI comes from the blog of Corban Brook where the following video can be found, actually a work by Peter Ablinger:
Another example of music inspired by speech is this interview with Louis Van Gaal:
Tarsos sends out midi data based on an FFT analysis of the signal. It maps the spectrogram to MIDI Messages and uses the power spectrum to calculate the velocity of each note on message.
The implementation can run in real-time but the output has some delay: the FFT calculation, constructing MIDI messages, calculating velocity, synthesizing sound, … is not instantaneous.
To use this capability Tarsos supports the following syntax. If a MIDI file is given the MIDI messages are written to the file. If an audio file is given Tarsos uses the audio as input. If the --pitch switch is used only the F0 is considered to construct MIDI messages instead of a complete FFT.
This post is about the tools I use to keep the source code of Tarsos reasonably clean, consistent and readable. Static code analysis can be of great help if you want to maintain strict coding standards and follow language idioms. Some of the patterns they can detect for you:
Dead code - unused variables, parameters, methods
Suboptimal code - wasteful resource usage
Overcomplicated expressions - unnecessary if statements, for loops that could be while loops
Duplicate code - copied/pasted code is a code smell.
Formatting inconsistencies, e.g. variable modifier order
And even more subtle, but equally important:
Resource management: is a resource handled (closed) correctly on all possible code paths?
Abstraction level: is it needed to expose the concrete type of an object or could an (abstract) supertype or even an interface be used instead?
…
In a previous life I used .NET and the static code analysis tools FxCop & StyleCop. FxCop operates on bytecode (or intermediate language in .NET parlance) level, StyleCop analyses the source code itself. Tarsos uses JAVA so I looked for JAVA alternatives and found a few.
PMD & Checkstyle both operate on source code level.
FindBugs operates on bytecode level.
On freesoftwaremagazine.com there is an article series on JAVA static code analysis software. It covers PMD and FixBugs and integration in Eclipse. It does not cover Checkstyle. Checkstyle is essentialy the same as PMD but it is better integrated in eclipse: it checks code on save and uses the standard ‘Problems’ interface, PMD does not.
Continuous testing is also a really nice thing to have: detecting unexpected behavior while refactoring/programming can prevent unnecessary bug hunts. A video about immediate feedback using continuous testing makes this clear.
Another tip is a more philosophical one: making your code and code revisions publicly available makes you think twice before implementing (and subsequently publishing) a quick and dirty hack. Tarsos is available on github.
I just finished creating a first release of Tarsos. The release contains several demo applications, some more usefull than other. Tarsos is a work in progress: not all functionality is exposed with the CLI (Command Line Interface) demo applications. The demos should however give a taste of the possibilities. All demo applications follow this pattern:
Today I created a spectrogram application using Tarsos. The application listens to an audio input, computes an FFT and at the same time calculates pitch. The expected pitch is overlaid on the spectrogram. All this happens real-time and is implemented using JAVA.
The JAVA software program we are developing is called Tarsos and can now be found on GitHub. GitHub is a web-based hosting service for projects that use the Git version control system.
Currently Tarsos is a collection of Java classes to create, compare and process pitch-frequency data using histograms. In it’s current state it is not usable for end-users.








 can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).")


 while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.")
 and balanceboard data (bottom, purple).")
, accelerometer-data (green) and audio (black).")




 The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of  ":\[A0-Poster.jpg\]
":\[A0-Poster.jpg\]



 \
\














 This is about PeachNote Piano, a project only tangentially related to Tarsos. PeachNote Piano aims to capture as many piano practice sessions as possible and offer useful services using this data. The system does this by capturing and redirecting MIDI events on a Bluetooth enabled smartphone. It is done together with
This is about PeachNote Piano, a project only tangentially related to Tarsos. PeachNote Piano aims to capture as many piano practice sessions as possible and offer useful services using this data. The system does this by capturing and redirecting MIDI events on a Bluetooth enabled smartphone. It is done together with