The following text puts into words a change that I have seen happening the last month. At the Ghent Centre for Digital Humanities we manage a fleet of virtual servers on the Ghent University network and have first-hand experience with security incidents appearing regularly now. It has a different tone than other posts here: it was sent in as a letter for a newspaper but was not published. Let’s see in a few years if the tone was too alarmist or if it holds up:
The newest generation of AI coding tools is a great asset for software developers. They help with understanding complex codebases, and assist in writing code. Used properly, AI coding tools increase software quality and developer productivity. Unfortunately, these powerful tools can also be used with bad intentions. AI coding tools are now sufficiently advanced to find and exploit bugs in software. They pose a threat to essentially all computing systems that form the underpinning of modern infrastructure: banking, aviation, industry, and education.
While earlier reports still used conditional terms to describe these threats, now — only a couple of weeks later — the first effects are already here. With the help of AI coding tools, three bugs were found in Linux, an open-source operating system: Copy.fail, Dirty Frag, and Fragnesia. These first AI-discovered exploits in a broadly deployed system form a watershed moment. The bugs led to service outages, but diligent IT teams quickly patched systems, limiting the impact. The effects of Mythos — widely considered the most capable system for finding bugs in software — are now also clear. Mozilla reported finding and fixing around four hundred bugs last month, where in a typical month around twenty similar bugs are discovered and patched. Not every bug is exploitable, but every exploit starts with a bug. The age of AI exploits is here.
The transition to this new age will be painful. Many unmaintained systems are connected to the internet and will not receive security updates: IoT devices, orphaned servers, smartphones and proprietary systems locked in time. It will become easier to gain illegitimate access to these machines. The skills needed to break into such systems are diminishing. What previously required highly specialized experts or state actors is now within reach of a much broader pool of bad actors, due to the very tools that are meant to help developers.
What can be done? Companies need more stringent cybersecurity policies today. The broader public needs awareness of this evolution and basic cybersecurity hygiene to keep devices up to date. And we need a regulatory framework that holds producers of computing systems responsible for updates over a longer lifespan. Unfortunately, we can not afford to collectively ignore this emerging reality.
Since a couple of months FFmpeg supports audio transcription via OpenAI Whisper and Wisper-cpp. This allows to automatically transcribe interviews and podcasts or generate subtitles for videos. Most packaged versions of the command line tool ffmpeg do not ship with this option enabled. Here we show how to do this on macOS with the Homebrew package manager. On other platforms similar configuration will apply.
On macOS there is a prepared Homebrew keg which allows to enable or disable the many ffmpeg options. If you already have ffmpeg without options installed you may need to uninstall the current version and install a version with chosen options. See below on how to do this:
# check if you already have ffmpeg with whisper enabled
ffmpeg --help filter=whisper
# uninstall current ffmpeg, it will be replaced with a version with whisper
brew uninstall ffmpeg
# add a brew tap which provides options to install ffmpeg from source
brew tap homebrew-ffmpeg/ffmpeg
# this commands adds most common functionality and other default functions
brew install homebrew-ffmpeg/ffmpeg/ffmpeg \
--with-fdk-aac \
--with-jpeg-xl \
--with-libgsm \
--with-libplacebo \
--with-librist \
--with-librsvg \
--with-libsoxr \
--with-libssh \
--with-libvidstab \
--with-libxml2 \
--with-openal-soft \
--with-openapv \
--with-openh264 \
--with-openjpeg \
--with-openssl \
--with-rav1e \
--with-rtmpdump \
--with-rubberband \
--with-speex \
--with-srt \
--with-webp \
--with-whisper-cpp
Installation will take a while since many dependencies are required for the many options. Once the build is finished the whisper filter should be available in FFmpeg. See below on how this should look, once correctly installed:
Last Friday, I had the pleasure of facilitating a hands-on workshop in Luxembourg as part of MuTechLab workshop series, organized by Luc Nijs at the University of Luxembourg. Together with Bart Moens from XRHIL and IPEM, we presented a system to control musical parameters with body movement.
MuTechLab is a series of workshops for music teachers who wish to dive into the world of music technology. Funded by the Luxembourgish National Research Fund (FNR, PSP-Classic), the initiative brings together educators eager to explore how technology can enhance music education and creative practice.
What we built and presented
During the workshop, participants got hands-on experience with the EMI-Kit (Embodied Music Interface Kit) – an open-source, low-cost system that allows musicians to control Digital Audio Workstation (DAW) parameters through body movement.
The EMI-Kit consists of:
- A wearable sensor device (M5StickC Plus2) that captures body orientation and gestures
- A receiver unit (M5Stack STAMP S3A) that converts sensor data to MIDI messages
Unlike expensive commercial alternatives, EMI-Kit is fully open source, customizable, and designed specifically for creative music practice and embodied music interaction practice and research.
The Experience
Teachers experimented with mapping natural body movements – pitch, yaw, roll, and tap gestures – to various musical parameters in their DAWs. The low-latency wireless system made it possible to move and control sound, opening up new possibilities for expressive musical performance and pedagogy.
Learn More
Interested in exploring embodied music interaction yourself? Check out:
The EMI-Kit project as-is is a demonstrator to inspire educators to embrace these tools and imagine new ways of teaching and creating music. The EMI-Kit as a platform can - with some additional programming - be a good basis to control musical parameters using various sensors. Have fun with checking out the EMI-Kit.
Participant package - with sender and receiver pair
I’ve just pushed some updates to mot — a command-line application for working with OSC and MIDI messages. My LLM tells me that these are exciting updates but I am not entirely sure that this is the case. Let me know if this ticks your box and seek professional help.
1. Scriptable MIDI Processor via Lua
I have implemented a MIDI processor that lets you transform, filter, and generate MIDI messages using Lua scripts.
Why is this useful? MIDI processors act as middlemen between your input devices and output destinations.You can do the following on incoming MIDI messages:
Filter - Block unwanted messages - channels - or select specific ranges
Route - Send different notes to different channel
Generate - Create complex patterns from simple input
The processor reads incoming MIDI from a physical device, processes it through your Lua script, and outputs the modified messages to a virtual MIDI port that your DAW or synth can receive. Some examples:
# Generate chords from single notes
mot midi_processor --script scripts/chord_generator.lua 06666# Transpose notes up by one octave
mot midi_processor --script scripts/example_processor.lua 06666
2. Network Discovery via mDNS
OSC receivers now advertise themselves on the network using mDNS/Bonjour with the _osc._udp service type.
This makes mot compatible with the EMI-kit — the Embodied Music Interface Kit developed at IPEM, Ghent University. OSC-enabled devices can automatically discover mot receivers on your network, eliminating manual configuration if the OSC sources add this functionality.
Power banks have become a staple for charging smartphones, tablets, and other devices on the go. They seem ideal to power small microcontroller projects but, they often pose a problem for low-current applications. Most modern power banks include an auto-shutdown feature to conserve energy when they detect a current draw below a specific threshold, often around 50–200mA. The idea being that the power bank can shut off after charging a smartphone. However, if you rely on power banks to power DIY electronics projects or remote applications with low current draw, this auto-off feature can be a significant inconvenience.
To address this issue, consider using power banks designed with an “always-on” or “low-current” mode. These power banks are engineered to sustain power delivery even when the current draw is minimal. Look for models that explicitly mention support for low-power devices in their specifications. If replacing a power bank isn’t an option, you can add a small load resistor or a USB dummy load to artificially increase the current draw. It works, but feels wrong and dirty.
For a previous electronics project I bought a power bank randomly. After a bit of testing, I determined that the minimal power draw was around 150mA, so I added a resistor to increase current draw. Only afterwards did I check the manual of the power bank and noticed, luckily, that there was a low-current mode. I removed the resistor and improved the battery life of the project considerably. If you want to power your DIY Arduino or electronics project, first check the manual of the power bank you want to use!
Edit: after further testing it seemed that the low current mode of this specific power bank still shuts down after a couple of hours. Your mileage may vary, and the main point of this post still holds: check the manual of your power bank. Eventually I went with a solution designed for electronics projects.
In my house, I have a few smart home features: to control ventilation, to open and close solar screens, and to switch a few smart sockets. Up until a couple of days ago, the ventilation and screen controllers operated using custom software running on an ESP32. However, configuring, maintaining, upgrading, and integrating with this custom software gradually became a headache.
Recently, I switched from custom software to Tasmota, an open-source smart home platform targeting ESP32 devices. Tasmota includes a web UI, flexible configuration options, OTA upgrades, and scripting features. The scripting functionality allows devices to be extended with additional commands, which is especially practical for controlling my solar screens. These screens use pulses to toggle between up-stop-down-stop states. By default, Tasmota only supports enabling or disabling a relay, not enabling it for a very brief period (e.g., 150 milliseconds). With a short ‘Berry’ script, such functionality is quickly added.
I appreciate the effort of the Tasmota team to lower the entry barrier for users. They provide ample documentation and a web installer, making setup straightforward. Simply connect your ESP32 via USB, flash it with Tasmota, and configure it—all from your browser. It’s a surprisingly simple process compared to installing a dedicated toolchain. While this might not be what Tim Berners-Lee envisioned 35 years ago, it certainly simplifies the user experience. Lowering the entry barrier even further, some manufacturers even offer smart home devices with Tasmota preinstalled, such as the Nous A1 smart sockets. Eternal september is here.
If you’re managing custom ESP32 smart home devices, consider switching to Tasmota. Its robust features, ease of setup, and active community support make it an excellent choice for both beginners and advanced users.
There is something about surprising interfaces: clapping to switch on lights is more fun than a flipping a switch. Pressing a panic-button to order a pizza is more fun than ordering via an app. Recently I came across this surprising interface: a flute controlled mouse cursor for a first person shooter. I recognize a good idea when I see one, and immediately wanted replicate the idea and make it freely available. So I got to work:
Vid: a microcontroller controlling mouse movements based on pitch detection.
What do we need for flute-based mouse? First we need a way to determine if a note is being played and if a note is produced, we need to be able to determine which note is being played by the musician. Next, we need to hijack and control a cursor via the detected note and trigger a click event when a specific note is played. Finally we need to play a flute, preferably a recorder, to move the mouse cursor in an obviously superior and relaxed fashion. It is not strictly required to use a recorder but a recorder is very much advised.
The note determination can be done by a fundamental frequency detector. A detector returns a frequency in Hertz and a confidence score which tells you how reliable the detection is. With some filtering, this is exactly what we need. If the frequency is close enough to a configured value, a note is detected. The confidence score tells us to either accept or ignore the detection. With this info it is possible to connect a note-detection to an action - like moving a cursor left or right, up or down.
Finally we need to move the mouse cursor. There are a few ways to do this.
Fig: Flute-based web-browsing as envisioned by its developer.
A portable way to move a mouse cursor is to let a micro-controller impersonate as a standard mouse, a ‘USB Human Interface Device’. Once the micro-controller is attached via USB it registers as a mouse and allows to move the cursor and register click events. To build a flute-based mouse, the micro-controller then needs a microphone and a pitch estimator to finally send cursor events.
I based my project on an RP2040 - a micro-controller chip designed by Raspberry Pi - since it offers a simple way to present itself to an operating system as a mouse. Just include PluggableUSBHID.h and USBMouse.h and use the Mouse API to control the mouse. For me it only behaved as a standard mouse if Serial is not used at the same time: in other words the dual USB profile does not seem to work reliably.
Sending mouse events from your code looks, for example, like ` Mouse.move(-4, 7)` to move the mouse minus four units in the horizontal and seven units in the vertical direction. Click events have a similarly straightforward API. The RP2040 also has a built-in microphone, which makes it ideal for audio applications, or so it seems.
Unfortunately, the RP2040 chip performs poorly for computationally heavy audio processing workloads. Such applications need to perform many floating point operations per second, but the RP2040 lacks a hardware floating point unit (FPU) which makes it relatively slow. When attempting to run a pitch-detection algorithm, the RP2040 was too slow to run the algorithm in real-time. After profiling the pitch estimation algorithm there was a clear place where most float operations occurred. Replacing those with much quicker fixed point operations makes the algorithm faster than real-time and usable on the RP2040.lt
To give a sens of the difference in speed between fixed point and floating point operations on the RP2040: with the default arduino build process, a million floating point operations take over 883 000 microseconds, a million fixed point operations take 8 microseconds. Fixed point operations are around 5 orders of magnitude faster!
The hardware based solution works reliably but, evidently, it needs a piece of hardware. To make sure everybody can enjoy a solution in software is provided in this section in the form of a chrome browser extension.
Moving a cursor is not possible in a browser: if a pointer location could be modified it would open a whole range of possibilities for abuse. A surprisingly easy workaround, however, is to hide the actual cursor and show a replacement cursor-like icon. This fake cursor can be moved programmatically. With the position of this fake cursor known, a click event can be triggered and result in, for example, following a link.
To take this idea to its logical next step, I implemented a chrome browser plug-in for flute-based web-browsing. I also relased this on GitHub under the Pitch perfect Pointer Positioning or PiPePoPo brand. Check the installation instructions in the PiPePoPo repository. Perhaps most of interest is how audio processing is handled by a Web Audio API Audio Worklet.
Vid: Controlling a cursor via a browser extension.
Join the flute-based web-browsing revolution today and experience web browsing like never before and install PiPePoPo.
I am not sure how but PiPePoPo was also featured on HackADay and the official Arduino Blog.
I have asked ChatGPT to generate 3D models. ChatGPT can not generate 3D models directly but 3D models can generated via intermediary OpenSCAD scripts: OpenSCAD provides a scripting language to describe objects which can be combined to form 3D models. ChatGPT understands the syntax of this scripting language and generates perfectly cromulent scripts. I have asked two versions of ChatGPT to generate a 3D model of a house, a cat, a stick figure, a chair and a tree. The results are interesting…
The models immediately make the difference between ChatGPT 3.5 Turbo and ChatGPT 4.0 clear: 4.0 generates much better models with, at least, recognizable elements: a chair has four legs, a cat has a head and a tail. It is impressive that reasonable 3D models are generated but there is still room for improvement: proportions are not respected and elements are not always connected. Anyway, if the 3D-models can be seen as a way to visualize code quality, then 4.0 is a clear improvement and it makes me curious about future ChatGPT versions. It also made me reflect on a couple of aspects of LLMs in general.
Fig: a black box generating 3D models.
ephemerality The response of a LLM to a prompt is ephemeral: the same prompt causes a different response depending on context, randomness and the position of heavenly bodies - or so it seems. Traditional software systems follow a strict set of clear rules and provide deterministic, predictable and reliable results. The inverse is true for LLMs which takes some getting used to. As a user, an LLM is effectively a vantablack box - there is no way to know why a certain response was given instead of another.
Updates LLMs services - and SaaS in general - have an additional feature which makes them even more unpredictable: updates to systems can happen without notice. After a recent unannounced update, for example, ChatGPT 4 started to produce gibberish. This adds another layer to the already uncontrollable and ephemeral nature of responses to LLM prompts.
To counter the ephemeral quality of prompt responses, I have 3D printed the generated 3D models. Some pictures can be found below. I find that these physical, tangible, immutable objects provide a comforting counterbalance to the digital, ephemeral nature of LLM responses. Additionally, it highlights the absurdity of the generated models.
There are other ways to solidify ephemerality: crochet patterns, juggling patterns, guitar tablature, music notation all have some kind of structured text representation which LLMs can generate and which can have a physical representation. I would encourage people to bring prompt responses to the physical world: it really makes the - current - limitations of LLMs very clear.
Fig: Hammer vs. screw. Not the right tool for the job.
For the last couple of years this blog has not been using any Javascript. During the last decade this has become quite rare. Only 1.2% of websites do not use Javascript I see this as a problem. In this text I want to argue that Javascript is perhaps not always the right tool for the job. Especially for web-pages which visitors simply want to read and where no explicit interactive actions are wanted from a user perspective, I see Javascript as detrimental.
I was triggered to write this by a few observations. One is by a Rails frontend framework which claims that “the only technology we should be using to create web UI is JavaScript”. This implies that the whole DOM should be rendered by Javascript. On the other hand there are frameworks which now advertise server side rendering as new feature like Blazor and Nuxt. The old thing is new again.
Let’s look at a few examples. Take visiting news website. On a news site, a user expects to be able to read current news, reviews, opinions, .. and there is no expectation of interactivity. Basically, a news site could work equally well on physical paper, as was the case for the last century or more. Ideally, a news site is a static HTML page with an easy to follow layout and some images, perhaps some static ads, with information flowing in a single direction.
If we look at, for example, the Guardian, we do not get this ideal experience, instead 82 Javascript files are loaded and the full website takes six full seconds to load on a fast fiber connection. The site even tries to load files from other domains. This bloat results in 8 website programming errors and CORS-issues. The Guardian website is far from the worst example of this sprawl of Javascript, the front-end for the Guaridan is even developed in the open.
Another news site is Hacker News. With its focus on Sillicon valley and technical news, this site has probably one of the most tech-savvy readers and … it does not rely on Javascript for functioning. There is a single small, readable 150 line script to improve usability but that is it. The makes the the website fast, easily indexable, straightforward to maintain, accessible, future-proof, failsafe, and compatible with even the most basic browsers and screen-readers.
Similarly, this blog is a dynamic Rails site but thanks to extensive use of server-side rendering and caching it behaves more like a static site generator: once everything is cached, the application mostly serves static HTML fragments. The client-side requirements are minimal as well: since no Javascript is used to modify the DOM - or even at all - lay-outing is straightforward.
Note that some blog posts feature advanced web application prototypes which do use a boatload of Javascript e.g. to convert audio, visualize audio, interact with micro-controllers or MIDI instruments,… . These prototypes use many of the available browser APIs like the Web Audio API, WebAssembly, Web MIDI API, Web Bluetooth API, WebGL, …. I really do like targeting modern browsers with offer many possibilities to build easy-to-use applications. But that is exactly a distinction that needs to be made: applications versus pages. Javascript versus No Javascript.
There is something about surprising interfaces. Having a switch to turn on a light gets quite boring after a while. Turning on a light by clapping twice, on the other hand, has some kind of magic feel to it. In a recent Mr Beast video he and his gang visit a number of expensive houses and in one of those mansions there is a light operated by clapping twice. I am not sure about the blatant materialism, but it got me thinking on how to build a similar clap-operated light yourself.
So, what are the elements needed: first a microphone to pick up sound. Second an algorithm is needed that detects claps. And finally, something that reacts to claps: a light or something else.
Many devices have microphones so sound input is relatively easy, and with some creativity there are many things waiting to be ‘clap triggered’: vacuum robots, sunscreens, lights, in-house ventilation, … The main difficulty is implementing a efficient clap-detection algorithm. Luckily there are already a few described in the literature. I have based my ANSI C implementation on ‘Duxbury, C., et al (2003). Complex domain onset detection for musical signals’.
My version of the clap-detection algorithm has two parameters which might need adapting to fit your environment. The silence threshold determines the minimum loudness for a clap to be triggered. The onset threshold determines more or less how ‘percussive’ the sound needs to be: the idea is to only react to things sounding like a clap and not to e.g. a loud whistle or other sounds. This is what the onset threshold tries to control. You can try it out below:
Demo: click the 'start audio' to capture your microphone and try to clap clearly twice. Lower the parameters if nothing happens.
Clap detection on a micro-controller
With this working we now can try to run this code on a micro-controller. Running it on a micro-controller makes it more practical in daily use to e.g. switch on lights. A low-cost ESP32 with a MEMS microphone is a good platform: these microcontrollers are easy to use and have WiFi connectivity which opens the possibility to trigger commands to smart sockets or other WiFi-enabled devices. The pector GitHub repository contains an Arduino project to run the clap-detection algorithm on an ESP32 or similar device (Teensy, RP2040,… ).
Clap detection in the command line
Next to the main clap detection software, there is a small script to trigger commands when a clap is detected. In this case, the script waits for a double clap and then pushes updates to a git repository. There are two reasons for this: the first is that it is fun, the second is for bragging rights. Not that many people can say they once pushed source code simply by clapping twice. It is, however, a challenge to find people who have the patience to listen to me explaining what I have done and who are impressed by this feat, so maybe there is only one reason: it is fun. Below a screen capture can be found pushing code to the pector repository.
Vid: pushing code by clapping
Have a look at the pector GitHub repository for more info on how you can make your websites/apps/command line tools/devices clap controlled!
I have been asked to give a guest lecture introducing Music Information Retrieval for the course ‘Foundations of Musical Acoustics and Sonology’ at Ghent University. The lecture slides include interactive demos with live sound visualization and can be found below.
As we delve into the intricacies of how machines can analyze and understand musical content, students will gain insights into the cutting-edge research field that underpins modern music technology. From the algorithms powering music recommendation systems to the challenges of extracting meaningful information from audio signals, the lecture aims to ignite curiosity and inspire the next generation of musicologists in both music and technology. Get ready for an engaging session that promises to unlock the doors to a world where the science of sound meets the art of music.
Thanks to ChatGTP for the slightly over-the-top intro text above. Anyway, here you can find my introduction to Music Information Retrieval slides . Especially the interactive slides are perhaps of interest. The lecture was given in the Art-Science Interaction Lab (ASIL) which has a seven meter wide screen, which affects the slide design a bit.
Fig: Click the screenshot to go to the 'Introduction to Music Information Retrieval' slides.
The recent version of the OLAF (Overly Lightweight Acoustic Fingerprinting) audio fingerprinting system also includes an updated WASM build which deserves a bit more attention.
The browser version of Olaf enables audio fingerprinting in the browser. This can be used to e.g. react to music playing in the environment, so called second screen applications or to synchronize several devices to an audio stream.
The goal of the demo below is to play music aloud - not using headphones - using the controls on the left. You can either play the reference track or an unrelated distractor. Next, the Olaf fingerpinter system needs to be started using the button on the right which captures the microphone of your device. Then Olaf tries match the incoming sound of the microphone and the reference track. Once a match is found the exact time in the match is displayed until the sound matches no more. Note that there is no direct information flowing between the left and right part. You can also play the reference on another device to be sure.
Reference:
\
Distractor:
To get this demo working with the Web Audio API and use AudioWorklet objects, to process audio in the background an not on the main browser thread. There is surprisingly little info to find on how to combine WASM libraries - I used both Olaf and libsamplerate-js - and the AudioWorklet environment. Thanks to one of the very few resources on combining WASM, emscripten and AudioWorklets led me in the right direction.
The Web Audio API offers some great functionality for web based audio applications. The API also has a couple of quirks and is not always easy to use. One of those quirks is the limited support for resampling audio. When requesting a microphone stream of a certain sample rate the API only allows configurations your hardware supports. Ideally there should be an option to resample the incoming stream to a requested sample rate (and format) independent of hardware.
On macOS and Chrome the issue becomes even more confusing: when using multiple AudioContexts they can only have the same sample rate. E.g. starting a microphone on 16kHz by itself is possible but not when there is also audio playback on the same page, then everything switches over to 48kHz. There even seems to be an effect of different browser tabs. Other browsers and platforms have similar issues. This is problematic when you need audio in a fixed sample rate.
The solution is to resample audio incoming samples in your code or use the OfflineAudioContext as a resampler. The OfflineAudioContext way needs a lot of code and, crucially, only works on the main browser thread and not in an AudioWorklet. The AudioWorklet should be the place for computationally intensive audio processing like resampling. To solve the resampling problem I have glued together an AudioWorklet and libsamplerate-js to provide an easy to use audio resampling solution which is demo’d below:
The demo does not seem to do much but it reads incoming microphone data and uses a high quality audio resampling library to resample an audio stream into a requested audio sampling rate. The browser development console shows some info on this process. To get this working in an audio worklet, the libsamplerate-js needed to be recompiled and directly included in the AudioWorklet. To inspect the source, check the “Web Audio API AudioWorklet resampler”:[web-audio-api-resample.zip].
Getting MEMS microphones to work on microcontroller platforms as the ESP32 is challenging. In theory, the I2S protocol provides a standardised, easy way to receive audio from a microphone and send stereo audio to a DAC. In practice, the many parameters make I2S not straightforwards to use. As with most protocols and standards, the mismatch between limitations and quirks of specific hardware and software implementations can cause issues. To debug I2S microphones on ESP32 or the RP2040 I have prepared a small Arduino program.
The IS2 WiFi microphone program sends audio from the microphone over WiFi to a computer which listen to the microphone: this make sure that the microphone works as expected and audio samples are correctly interpreted. It validates the I2S settings like buffer sizes, sample rates, audio formats, stereo or mono settings, … After configuring an SSID, password and IP-address it becomes possible to listen — in real-time — to the microphone which also allows the listener to sense the microphone quality.
size_t bytesIn = 0;
esp_err_t result = i2s_read(I2S_PORT, &sBuffer, bufferLen, &bytesIn, portMAX_DELAY);
int16_t *sample_buffer = (int16_t *)sBuffer;
int16_t samples_read = bytesIn / 2;
float audio_block_float[samples_read];
for (size_t i = 0; i < samples_read; i++) {
sample_buffer[i] = gain_factor * sample_buffer[i];
// Max for signed int16_t is 2^15
audio_block_float[i] = sample_buffer[i] / 32768.f;
}
// Send raw audio 32bit float samples over UDP
Udp.beginPacket(outIp, outPort);
Udp.write((const uint8_t *)audio_block_float, bytesIn * 2);
Udp.endPacket();
Fig: The main part of reading i2s audio from a microphone and sending an UDP packet.
To listen to the incoming audio an UDP port needs to be captured and subsequently send to a program that can interpret and play or store audio. With netcat UDP data can be captured. With ffmpeg and ffplay audio can be payed or stored. In practice the receiving computer might run the following commands to decode UDP packages and hear the microphone:
# for playback, receive UDP packages and interpret raw audio
nc -l -u 3000 | ffplay -f f32le -ar 16000 -ac 1 -
# for playback, receive UDP packages and store in a wav file
nc -l -u 3000 | ffmpeg -f f32le -ar 16000 -ac 1 -i pipe: microphone.wav
Olaf is an acoustic fingerprinting system designed with embedded devices in mind. It has a low memory use and computational requirements which are compatible with e.g. the ESP32 line of microcontrollers devices like the SparkFun ESP32 Thing or devices based on the RP2040 chip. Recently I have prepared a demo with the newest version of Olaf running on an ESP32 which deserves some attention.
To match audio, Olaf needs access to streaming audio. This can be audio read from an SD-card but, more likely, audio comes from a microphone. Digital microphones have some great features: a low-noise floor, great at picking up omnidirectional sound and they are inexpensive. I have prepared a demo of Olaf which shows how to use Olaf on an ESP32 with an INMP441 MEMS microphone. To test the MEMS microphone I also made a MEMS microphone to WiFi program which sends incoming sound on the ESP32 over WiFi to a computer where the sound quality can be verified.
The example provides a scaffold for embedded music-reactive applications. Once the microcontroller knows which song is playing and where in the song the match is found it can trigger LED’s (or explosions, fireworks, lyrics, other effects…) which should happen in sync with the music. See the example below to get the idea, this demo runs an older version of Olaf but the idea stays the same:
The main difference between the current and previous versions of Olaf is that now the ESP32 version, the browser version and the PC version are all running the exact same code. No hacks are needed any more to support a platform. This means that testing and debugging can be done on a computer and, if everything goes well, the code should work as expected on the embedded device (or browser).
I have just released a Python wrapper for the Olaf acoustic fingerprinting library. Olaf is a scalable audio search system based on indexing . Olaf is programmed in C but a wrapper now makes its functionality available in Python.
The python wrapper should make it more accessible for developers to get started with it and makes it compatible with other Python libraries. A few notable libraries are the librosa python package for music and audio analysis,nnAudio, A fast GPU audio processing toolbox and other more general plotting, data processing and machine learning libraries. Despite Python’s many flaws, its rich library ecosystem is unmatched.
The associated GitHub repository contains documentation on how to use the Olaf python wrapper and also contains examples. The first shows how to index a song into the database and subsequently query the database. The second visualises the event points extracted by Olaf. The figure below shows shows the resulting event points, extracted with Olaf, plotted on a magnitude spectrogram, calculated with Olaf. The spectrogram on top is calculated using librosa and is meant to be very similar to Olaf.
\
Fig: *A power spectrum from librosa and one from Olaf, with event points marked*.
The wrapper was made with Python CFFI which works reasonably well. The automatically generated wrapper library support a large part of the C language but it needs a compilation step for each platform. Currently, the instructions assume a POSIX-like system, but technically, the wrapper can also function on Windows, albeit with the potential need for Windows-equivalent instructions in place of certain POSIX ones. The wrapper is wrapped in an easy to use python class called Olaf.py:
```python\
from olaf import Olaf, OlafCommand\
import librosa
Store the first ten seconds of an audio file\
audio_file = librosa.ex(‘choice’)\
Olaf(OlafCommand.STORE,audio_file).do(duration=10.0)
Query for a part of the same file (with an offset of 7 seconds), but change volume\
y, sr = librosa.load(audio_file,mono=True, sr=16000,duration=10,offset=7.0)\
y = y * 0.8 #change the volume\
results = Olaf(OlafCommand.QUERY,audio_file).do(y=y)
We expect a match between the stored and partially overlapping query\
print(results)\
```
I often play board games with my kids. One of them is an absolute board game fan while the other is a sore loser and only wants to play collaborative games. These games are played ‘against the board’ and you win, or lose, together. I myself also still have problems losing games so I do understand this predicament. Genetics…
Rock & Troll is one of those games. It is a chance based game where you collaboratively try to build a path to a treasure before the dragon reaches it. Every player has to flip a tile which is either a part of the path (good) or a dragon (very bad). To increase engagement during play I often add sound effects. I was thinking: this can be improved and automated. For example, by doing this when a dragon tile is flipped:
The idea is to unobtrusively detect game state and add sound effects at critical moments. The sound effect should be playing without too much lag, ideally within about 200ms, so it feels immediate and connected to the game event. To implement this a camera based system with robust, fast object detection seemed like the way to go.
Dragon detection
To detect dragons in a video stream I want to retrain an existing object-detection system. So two things need to happen: first a realistic, labeled dataset needs to be created. Then a system needs to be trained to detect the dragons. We do not want to label a massive dataset so we will use transfer learning to retrain an existing network. This existing network should already have learned basic features like edges, colors, geometries and other basic patterns. With the hope that this would result in robust detection, even with a limited dataset.
To create the dataset I wrote a small script which took a webcam picture every few seconds while I was manipulating the board and tiles. This resulted in about 130 pictures, some with no dragons and some with six, 300 labels in total. For annotating the dataset I used the free roboflow web-app which also hosts the final dragon dataset. After augmentation, the size of the dataset can be tripled. The command to extract images from a webcam looks like this on my system:
After some consideration for alternatives I landed on the YOLOv8 object-detection system: a robust and fast object-detection system. Additionally, it is well-documented, pytorch-based, easy-to-use and it has support for video streams. The annotated roboflow dataset can be downloaded in a YOLOv8 compatible format as well. Transfer learning, was based on the yolov8s.pt weights, which are downloaded automatically. With the system installed correctly and the dataset dowloaded, a local GPU based training command might look like this:
Once the system was trained - download the “model wheights here”:[dragons.pt] - a bit of “glue code”:[rock_n_troll_v8.py] is needed. The python script needs to stream images from a camera, here via open cv, and detect dragons in each image. Every time a new dragon is found, the sound effect is played. Note that the Roboflow website automatically trains a model as well which can be tried out with a webcam.
There are a few ways improve the robustness of the system. During a game there are only more and more dragons: if the script detects less dragons than before it is probably a false negative or there is occlusion. Additionally, the dragon tiles remain in the same location once they are placed on the board. This means that new dragons are expected only in certain regions of the image. Both heuristics can be used to together to improve robustness.
Notes
One of the reasons I bought a M1 mac with unified memory is for exactly these types of AI applications. After installing pytorch 2.0, the GPU acceleration resulted in a 10x training speed improvement. Training on a GeForce 1080 GTX from 2016 was still quite a bit faster, probably thanks to years of performance tuning targeting CUDA. It is clear that the mac GPU acceleration software ecosystem can use more effort, even system tools in macOS are limited: e.g. in the macOS activity monitor, GPU activity is very much an afterthought.
I am and hesitant to use cloud based GPU computing due to lack of control and privacy. I am not willing to send pictures from my kids to e.g. Google Cloud GPUs. The dependency on hardware of others might also limit the longevity of systems.
The ease-of-use, performance and accessibility of these deep-learning systems is great. Only a couple of years ago it would take months of hard work to maybe only approach similar detection performance. Adapting this idea for other board games and more types of tiles or board game events should be very possible.
This post is an efficient way to determine whether a predefined frequency is present in a signal. If such an algorithm can be found, it can serve as a basis for a modem. With a modem data is modulated and demodulated at the receiving side. The modulation allows data to be send over a transmission channel.
With the ability to detect the presence of audible frequencies a modem can transform symbols into a combination of frequencies and send data over sound. This is exactly what happens with DTMF in the sound below. DTMF is also used in the dailup sound.
Audio: dail tone sequence: which numbers are pressed?
Typically, determining the presence of frequencies in a signal is done with an FFT: an FFT divides a signal into e.g. 512 linearly spaced frequency bands and determines the magnitude of each of these frequencies. The annoying thing is that a probe frequency can be right in between two bands: sample rate, FFT size and the frequency to look for need to be carefully chosen to reliably detect a frequency. Also, it is computationally inefficient to calculate the magnitudes for all frequency bands if only one band is actually needed.
Luckily there is an alternative approach which looks like the calculating the FFT but for only one predetermined frequencies. This algorithm is known as the Goertzel algorithm and is used in DTMF dail tone encoding and decoding. With the standard Goertzel algorithm it is still needed to consider sample rate and the frequency of interest.
Recenlty I needed a piece of ANSI c code to detect the magnitude of an arbitrary frequency for a project. The following is a C implementation of this algorithm. It uses the C support for complex numbers in the complex.h header:
Below you can try out the algorithm. You can choose a frequency to detect and a playback frequency. The magnitude of the frequency is reported via the slider. The demo uses a javascript translation of the code above.
Dual-tone Multi-Frequency - DTMF
DTMF in the browser.
On the right you can find a demo of dual tone frequency modulation and demodulation. A combination of frequencies is played and immediately detected.
The green bars show which frequencies have been detected. If for example 1209 Hz is detected together with 770 Hz then this means that we are looking for the symbol in the first column on the second row. Both the first column and the second row are highlighted in green. At that spot we see 4 so we can decode a 4. By using 2 combinations of four frequencies a total number of 16 symbols can be encoded.
Note that this code does not simply highlight the button press directly but encodes the symbol in audio, feeds it into an Web Audio API format and decodes audio, the result of the decoding step highlights the row and column detected.
The C programming language is deceptively simple. The syntax is straightforward, C has a limited amount of keywords and a small standard library. The first edition of the classic book ‘The C Programming Language’ is only about 200 pages. And yet, when programming in C, it is hard to avoid the many exiting footguns: integer type conversions, unchecked indexes and memory leaks can all cause subtle problems. This is part of the appeal of C: shooting yourself in the foot does make you feel alive. Here I want to focus on ways to check for memory leaks for C programs.
Memory leaks come about when memory is claimed but is never released again. If this is done in a loop or during a long running program, the claimed memory adds up and eventually the system may run out of memory. A memory leak is less a problem if a program forgets to free a small amount of memory it only claims once: after program shut down, the operating system reclaims all memory anyhow. However, it does feels very dirty to not clean up after oneself. And I for one, am not a dirty boy.
Another reason to look for memory use and leaks is when you are programming for embedded devices. For these systems memory is very limited: in that world 500kB RAM is considered a massive amount of memory. I have been busy programming a scalable audio search system called Olaf which targets both traditional computers, embedded systems and browsers (via WebAssembly). It is clear that memory use — and memory leaks — need to be kept in check to pull this of.
Now, these memory leaks might not be easy to spot by inspecting the code. There are tools which help to spot memory management problems. One of these is valgrind which is currently not easy to use on Apple system with ARM processors. Luckily there is an alternative which is probably already installed on macOS via the XCode Command Line Tools a command line tool aptly called leaks. To quote the apple documentation on leaks, leaks reports:
the address of the leaked memory
the size of the leak (in bytes)
the contents of the leaked buffer
The most straightforward use of leaks is to run a program and generate a report after program shutdown. See below to run a memory leak inspection, in this case for the bin/olaf_c program which indexes an audio file in a key-value store. For CI purposes it is practical to know that leaks has an exit status of zero only when no leaks have been found. The exit status can be used in an automated test script to break a build if a leak is detected. The --quiet option can be practical in such setting.
leaks --atExit -- bin/olaf_c store audio.raw audio
In the case of Olaf I made a classic mistake: I had called free() on hash table but I needed to call the hash table destructor: hash_table_destroy() which freed not only the hash table itself but also all memory associated with the hash table entries. After a quick fix the leaks command showed no more leaks!
Output of the `leaks` command which shows where a memory leak can be found.
General takaways
leaks is an easy to use memory leak inspector provided by Apple. It is an alternative for valgrind.
Memory leaks can be checked automatically using the leaks exit status in a CI-script. This makes spotting leaks timely and more straightforward to fix.
Programmers should at least once try to target embedded devices. It makes you conscious of the wealth of resources available when targeting modern computing devices.
This post details how I went about optimizing a C application. This is about an audio search system called Olaf which was made about 10 times faster but contains some generally applicable steps for optimizing C code or even other systems. Note that it is not the aim to provide a detailed how-to: I want to provide the reader with a more high-level understanding and enough keywords to find a good how-to for the specific tool you might want to use. I see a few general optimization steps:
The zeroth step of optimization is to properly **question the need** and balance the potential performance gains against added code complexity and maintainability.
Once ensured of the need, the first step is to **measure the systems performance**. Every optimization needs to be measured and compared with the original state, having automazation helps.
Thirdly, the second step is to **find performance bottle necks**, which should give you an idea where optimizations make sense.
The third step is to **implement and apply** an optimization and measuring its effect.
Lastly, **repeat** steps zero to three until optimization targets are reached.
More specifically, for the Olaf audio search system there is a need for optimization. Olaf indexes and searches through years of audio so a small speedup in indexing really adds up. So going for the next item on the list above: measure the performance. Olaf by default reports how quickly audio is indexed. It is expressed in the audio duration it can process in a single second: so if it reports 156 times realtime, it means that 156 seconds of audio can be indexed in a second.
The next step is to find performance bottlenecks. A profiler is a piece of software to find such bottle necks. There are many options gprof is a command line solution which is generally available. I am developing on macOS and have XCode available which includes the “Instruments - Time Profiler”. Whichever tool used, the result of a profiling session should yield the time it takes to run each functions. For Olaf it is very clear which function needs optimization:
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
The function is a max filter which is ran many, many times. The implementation is using a naive approach to max filtering. There are more efficient algorithms available. In this case looking into the literature and implementing a more efficient algorithm makes sense. A very practical paper by Lemire lists several contenders and the ‘van Herk’ algorithm hits the sweet spot between being easy to implement and needing only a tiny extra amount of memory. The Lemire paper even comes with example c max-filters. With only a slight change, the code fits in Olaf.
After implementing the change two checks need to be done: is the implementation correct and is it faster. Olaf comes with a number of functional and unit checks which provide some assurance of correctness and a built in performance indicator. Olaf improved from processing audio 156 times realtime to 583 times: a couple of times faster.
After running the profiler again, another method came up as the slowest:
//Naive implementationfloat olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
float max = -10000000;
for (size_t i = 0; i < array_size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
src: naive implementation of finding the max value of an array.
This is another part of the 2D max filter used in Olaf. Unfortunately here it is not easy to improve the algorithmic complexity: to find the maximum in a list, each value needs to be checked. It is however a good contender for SIMD optimization. With SIMD multiple data elements are processed in a single CPU instruction. With 32bit floats it can be possible to process 4 floats in a single step, potentially leading to a 4x speed increase - without including overhead by data loading.
Olaf targets microcontrollers which run an ARM instruction set. The SIMD version that makes most sense is the ARM Neon set of instructions. Apple Sillicon also provides support for ARM Neon which is a nice bonus. I asked ChatGPT to provide a ARM Neon improved version and it came up with the code below. Note that these type of simple functions are ideal for ChatGPT to generate since it is easily testable and there must be many similar functions in the ChatGPT training set. Also there are less ethical issues with ‘trivial’ functions: more involved code has a higher risk of plagiarization and improper attribution. The new average audio indexing speed is 832 times realtime.
src: a ARM Neon SIMD implementation of a function finding the max value of an array, generated by ChatGPT, licence unknown, informed consent unclear, correct attribution impossible.
Next, I asked ChatGPT for an SSE SIMD version targeting the x86 processors but this resulted in noticable slowdown. This might be related to the time it takes to load small vectors in SIMD registers. I did not pursue the SIMD SSE optimization since it is less relevant to Olaf and the first performance optimization was the most significant.
Finally, I went over the code again to see whether it would be possible exit a loop and simply skip calling olaf_ep_extractor_max_filter_time in most cases. I found a condition which prevents most of the calls without affecting the total results. This proved to be the most significant speedup: almost doubling the speed from about 800 times realtime to around 1500 times realtime. This is actually what I should have done before resorting to SIMD.
In the end Olaf was made about ten times faster with only two local, testable, targeted optimizations.
General takeways
Only think about optimization if there is a need and set a target: otherwise it is infinite.
Try to find a balance between complexity, maintainability and performance.
Changing a naive algorithm to a more intelligent one can have a significant performance increase. Check the literature for inspiration.
Check for conditions to skip hot code paths before trying fancy optimization techniques.
Profilers are crucial to identify where to optimize your code. Applying optimizations blindly is a waste of time.
Try to keep optimizations local and testable. Sprinkling your code with small, hard to test performance oriented improvements might not be worthwile.
SIMD generated by ChatGPT can be a very quick way to optimize critical, hot code paths. I would advise to only let ChatGPT generate small, common, easily testable code: e.g. finding the maximum in an array.
Fig: the NeXTCube with the Ariel ProPort and MIDI input/output interface.
Recently, I was able to restore a NeXTCube and install an early version of MAX - a graphical music programming environment. However, a crucial part of the system was missing: there was no way to do MIDI input/output. MIDI is used to connect controllers, keyboards, synthesizers or other musical instruments to the audio workstation. The NeXTCube itself has a serial port which allows users to connect MIDI devices. Next to the serial port on the mainboard, the NeXTCube I am working with also has a RS-422 serial port on the ISPW ‘soundcard’. The serial port uses RS-422 and mini DIN 8 connectors which provide MIDI input and output. While the MIDI data bytes are transmitted according to spec, the connector and the electrical signals are not compatible with standard MIDI.
Fig: the IRCAM/Ariel ISPW soundcard with mini DIN-8 RS-433 serial port on the right.
For MIDI I/O we need a device which allows to connect the RS-422 MIDI to both legacy MIDI devices and to computers via USB MIDI. If a MIDI event arrives from the NeXTCube’s RS-422 it needs to be passed through to the USB and legacy MIDI ports and the other way around. The Teensy platform is ideal: it supports hardware serial and USB MIDI. In this retro-computing project, it seems wasteful to use the 600MHz Teensy 4.0 only for message passing: the Teensy has much more computing power than NeXTcube but it is cheap, easy to program, available and practical.
The RS-422 serial port uses –6V to 6V logic which needs to be transformed to the 0V to 3.3V logic for the Teensy microcontroller. A PCB provides this capability and is connected to a hardware serial port of the Teensy. The pinout of the RS-422 port was measured via a scope and matched the documentation. The Teensy has an usbMIDI mode and can present itself as a standard MIDI device to a PC. Two opto-isolated legacy MIDI DIN-5 ports were connected to another hardware serial port. The software on the Teensy conducts the “three-way MIDI message passing”:[midi_passthrough.ino].
Vid: Max/FTS FM synth reacting to USB MIDI input.
The electronics were fixed into a reused metal enclosure. The front panel of the enclosure was replaced by a custom 3D printed panel. The front contains the RS-422 port, two MIDI DIN 5 ports and a micro usb port either for power alone or MIDI messages and power. Feel free to check out the “OpenSCAD design with a level MINI DIN8 hole”:[midi_box.scad].
With a working MIDI interface for the NeXTcube allows interfacing with MIDI keyboards and controllers. It can also be used to measure roundtrip latency. MIDI to sound latency determines how long it takes between pressing a MIDI key and hearing sound. MIDI to MIDI roundtrip latency determines how long it takes to process, parse and return a MIDI message. For a responsive, reliable system both types of latencies should be constant and preferably in the range of 10ms or below.
Fig: Measured MIDI roundtrip latency on the ISPW board for the NeXTCube.
Measuring the MIDI roundtrip latency shows that the system is able to respond in 3.6+–0.4 ms (N=300). A combination of a MAX patch and “Teensy firmware”:[next_midi_roundtrip_latency.ino] was used to measure this automatically. The MIDI-to-audio latency was measured a few times manually and always was around 13ms. These figures show that the system is ideal for low-latency real-time music making in its default configuration. In MAX the audio buffer sizes could be reduced to achieve an even lower latency but with the risk of running into buffer underruns and audio glitches.
As a way to get to know the Rust programming language I have developed a couple of practical tools for OSC and MIDI debugging. OSC and MIDI are protocols which are almost always used for applications dealing with music. In these applications latency should be kept in check. Languages with garbage collection (Java, Go) and scripting languages (Ruby, Python, …) are hard to tune for low-latency applications and do not really have real-time guarantees. Rust, as a modern alternative for C/C, is a better fit for cross platform CLI low-latency applications.
This opens a couple of possibilities which are discussed below.
Sending UDP messages from the browser
One of the ways to send OSC messages from a browser to a local network is by using the MIDI out capability of browsers and - using mot - translating MIDI to OSC an example can be seen below.
Fig: sending an UDP message to a network from a Browser using a the mot MIDI to OSC bridge, click the image for a better readable version.
Measuring UDP message latency
Both MIDI and OSC can be seen as rather general data encapsulation protocols with wide support in terms of libraries and cross platform support. Their value goes beyond mere musical applications. The same holds for mot. In this example we are using mot to measure UDP message latency between two hosts.
On the first host we send MIDI messages from MIDI device 0 over OSC to another host with e.g. mot midi_to_osc 192.168.1.12:3000 /m 0. At the other host we receive the OSC messages and send them to a virtual device: mot osc_to_midi 192.168.1.12:3000 /m 6666.
At the second host we return messages from the virtual device to the first host: mot midi_to_osc 192.168.1.4:5000 /m 1. Perhaps you first need to do mot midi_to_osc -l to find the index of the virtual device. As a final step the messages can be received at the first host and returned to the original midi device. On the first host: mot osc_to_midi 192.168.1.4:5000 /m 0.
If the original MIDI device is a Teensy running the “roundtrip patch” then finally the roundtrip time is accurately measured and shown in the serial console. I am sure the previous text is cromulent, totally not contrived and not confusing. Anyway, to make it more confusing: this is what happens when you use a single host to do midi to osc to midi to osc to midi and use the loopback networking device:
Fig: MIDI to OSC to MIDI to OSC to MIDI roundtrip latency.
Visualizing sensor data in the browser
Fig: Sensor data as MIDI.
When capturing sensor data on microcontrollers, data can be encoded into MIDI. This makes almost any sensor practically useful in Ableton Live or similar environments. It also makes it compatible with all other MIDI supporting devices. With mot it becomes trivial to send MIDI encoded sensor data over OSC e.g. to a central place to log that data.
Another use case is to visualize the incoming data in real-time. A single web page which reads and visualizes incoming MIDI-sensor data becomes much more useful if streams from other devices can be visualized as well with the mot midi_to_osc and mot osc_to_midi commands.
Cross-platform support
With the Rust compiler it is relatively easy to cross-compile for different targets. There is however an important limitation in mot. Windows has no support for virtual MIDI ports which limits the usefulness of mot on that platform.
TarsosDSP is a Java library for audio processing I have started working on more than 10 years ago. The aim of TarsosDSP is to provide an easy-to-use interface to practical music processing algorithms. Obviously, I have been using it myself over the years as my go-to library for audio-processing in Java. However, a number of gradual changes in the java ecosystem made TarsosDSP more and more difficult to use.
Since I have apparently not been the only one using it, there was a need to give it some attention. During the last couple of weeks I have found the time to give it this much needed attention. This resulted in a number of updates, some of the changes include:
Change of the build system from Apache Ant to Gradle
Make use of Java Modules to make TarsosDSP compatible with the ModulePath introduced in Java 9.
Packaged the software into a maven compatible format, which makes it easy to use as a dependency.
CI with GitHub actions to automatically build and test the software.
Updated some examples shipped with the TarsosDSP. I have still still some examples to verify.
Improved handling of errors on reading audio via ffmpeg
\
Fig: The updated TarsosDSP release contains many CLI and GUI example applications.
Notably the code of TarsosDSP has not changed much apart from some cosmetic changes. This backwards compatibility is one of the strong points of Java. With this update I am quite confident that TarsosDSP will also be usable during the next decade as well.
JNI is a way to use C or C code from Java and allows developers to reuse and integrate C/C in Java software. In contrast to the Java code, C/C code is platform dependent and needs to be compiled for each platform/architecture. Also it is generally not a good idea to make users compile a C/C library: it is best provide precompiled libraries. As a developer it is, however, a pain to provide binaries for each platform.
With the dominance of x86 processors receding the problem of having to compile software for many platforms is becoming more pressing. It is not unthinkable to want to support, for example, intel and M1 macOS, ARM and x86_64 Linux and Windows. To support these platforms you would either need access to such a machine with a compiler or configure a cross-compiler for each system: both are unpractical. Typically setting up a cross-compiler can be time consuming and finicky and virtual machines can be tough to setup. There is however an alternative.
Zig is a programming language but, thanks to its support for C/C, it also ships with an easy-to-use cross-compiler which is of interest here even if you have no intention to write a single line of Zig code. The built-in cross-compiler allows to target many platforms easily.
Cross compilation of C code is possible by simply replacing the gcc command with zig cc and adding a target argument, e.g. for targeting a Windows. There is more general information on zig as a cross-compiler here.
Cross-compiling a JNI library is not different to compiling other libraries. To make things concrete we will cross-compile a library from a typical JNI project: JGaborator packs the C/C library gaborator. In this case the C/C code does a computationally intensive spectral transformation of time domain data. The commands below create an x86_64 Windows DLL from a macOS with zig installed:
{style="overflow-x:scroll"}
<code>
bash
#wget https://aka.ms/download-jdk/microsoft-jdk-17.0.5-windows-x64.zip#unzip microsoft-jdk-17.0.5-windows-x64.zip#export JAVA_HOME=`pwd`/jdk-17.0.5+8/
git clone --depth 1https://github.com/JorenSix/JGaborator
cd JGaborator/gaborator
echo $JAVA_HOMEJNI_INCLUDES=-I"$JAVA_HOME/include"\ -I"$JAVA_HOME/include/win32"
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC pffft/pffft.c -o pffft/pffft.o
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC -DFFTPACK_DOUBLE_PRECISION pffft/fftpack.c -o pffft/fftpack.o
zig c++ -target x86_64-windows-gnu -I"pffft" -I"gaborator-1.7"$JNI_INCLUDES -O3\
-ffast-math -DGABORATOR_USE_PFFFT -o jgaborator.dll jgaborator.cc pffft/pffft.o pffft/fftpack.o
file jgaborator.dll
# jgaborator.dll: PE32+ executable (console) x86-64, for MS Windows
</code>
Note that, when cross-compiling from macOS, to target Windows a Windows JDK is needed. The windows JDK has other header files like jni.h. Some commands to download and use the JDK are commented out in the example above. Also note that targeting Linux from macOS seems to work with the standard macOS JDK. This is probably due to shared conventions regarding compilation of libraries.
To target other platforms, e.g. ARM Linux, there are only two things that need to be changed: the -target switch should be changed to aarch64-linux-gnu and the name of the output library should be (by Linux convention) changed to libjgaborator.so. During the build step of JGaborator a list of target platforms it iterated and a total of 9 builds are packaged into a single Jar file. There is also a bit of supporting code to load the correct version of the library.
Using a GitHub action or similar CI tools this cross compilation with zig can be automated to run on a software release. For Github the Setup Zig action is practical.
Loading the correct library
In a first attempt I tried to detect the operating system and architecture of the environment to then load the library but eventually decided against this approach. Mainly because you then need to keep an exhaustive list of supporting platforms and this is difficult, error prone and decidedly not future-proof.
In my second attempt I simply try to load each precompiled library limited to the sensible ones - only dll’s on windows - until a matching one is loaded. The rationale here is that the system itself knows best which library works and failing to load a library is computationally cheap. There is some code to iterate all precompiled libraries in a JAR-file so supporting an additional platform amounts to adding a precompiled library in the JAR folder: there is no need to be explicit in the Java code about architectures or OSes.
Trying multiple libraries has an additional advantage: this allows to ship multiple versions targeting the same architecture: e.g. one with additional acceleration libraries enabled and one without. By sorting the libraries alphabetically the first, then, should be the one with acceleration and the fallback without. In the case of JGaborator for mac aarch64 there is one compiled with -framework Accelerate and one compiled by the Zig cross-compiler without.
Takehome messages
If you find yourself cross-compiling C or C for many platforms, consider the Zig cross-compiler. Even when you have no intention to write a single line of Zig code.
For JNI and Java the JGaborator source code might offer some inspiration to pre-compile and load libraries for many platforms with little effort.
CI tools can help to verify builds and automate Zig cross-compilation.
If you build for Windows make sure to include windows header-files even when there are no compilation errors using UNIX-header files.
I have built a tool for audio-to-audio alignment. It has applications for synchronization of media files. It works in the browser and you can synchronize your media files here with SyncSink.wasm. SyncSink.wasm does the following:
From an incoming media-file audio is extracted, downmixed to mono and and resampled. This is done with ffmpeg.audio.wasm a wasm version of ffmpeg.
For each audio track, fingerprints are extracted. These fingerprints reduce the the search space for alignment drastically.
Each list of fingerprints is aligned with the list of fingerprints from the reference. Resulting in a rough alignment
Cross correlation is done to refine the alignment resulting in sample accurate results.
Fig: media synchronization with audio-to-audio alignment.
It supports small time-scale adjustments of around 5%: audio alignment can still be found if audio speed differs a bit.
Some potential use cases where it might be of use:
To stitch partially overlapping audio recordings together resulting in a single long audio recording.
To synchronize multiple independent video recordings of the same event each with an audio recording of the environment.
To align a high quality microphone recording with video/low-quality audio recording of the same event. The low quality audio recorded with a camera can then be replaced with the high quality microphone audio.
LMDB is a fast key value store, ideal to store and query sorted data with small keys and values. LMDB is a pure C library but often used from other programming languages via some type of bindings. These bindings are ‘bridges’ between languages and are automatically present on supported platform. On new or unsupported platforms, however, you need to build a this bridge yourself.
This blog post is about getting java-lmdb working on such unsupported platform: arm64. The arm64 platform is much more popular since the introduction of the Apple silicon - M1 platform. On Apple M1 the default architecture of Docker images is also aarch64.
Next you need to build the lmdb library for your platform and copy it to a location where Java looks for it. This only works when compilers are already available on your system. In macOS you might need to install the XCode command line tools:
#xcode-select --install
git clone --depth 1 https://git.openldap.org/openldap/openldap.git
cd openldap/libraries/liblmdb
make -e SOEXT=.dylib
cp liblmdb.dylib ~/Library/Java/Extensions
On Debian aarch64 the procedure is similar but a different extension is used (.so):
#apt install build-essential
git clone --depth 1 https://git.openldap.org/openldap/openldap.git
cd openldap/libraries/liblmdb
make
mv liblmdb.so /lib
Finally, to use the library in a JAR-file is might be needed to allow lmdbjava to access some parts of the JRE:
Basic media info: gives information about the streams and encodings used in a media file.
Fig: [audio transcodinging in the browser](/attachment/cors/ffmpeg.audio.wasm/transcode.html). A `wav` file is converted to an `mp3`.
A bit more about the rationale behind this effort: Browsers have become practical platforms for audio processing applications thanks to the combination of Web Audio API , performant Javascript environment and WebAssembly. Have a look, for example, at essentia.JS.
However, browsers only support a small subset of audio formats and container formats. Dealing with many (legacy) audio formats is often a rather painful experience since there are so many media container formats which can contain a surprising variation of audio (and video) encodings. In short, decoding audio for in-browser analysis or playback is often problematic.
Luckily there is FFmpeg which claims to be ‘a complete, cross-platform solution to record, convert and stream audio and video’. It is, indeed, capable to decode almost any audio encoding known to man from about any container. Additionally, it also contains tools to filter, manipulate, resample, stretch, … audio. FFmpeg is a must-have when working with audio. It would be ideal to have FFmpeg running in a browser…
Thanks to WebAssembly ffmpeg can be compiled for use in the browser. There have been effortstoget ffmpeg working in the browser. These efforts have been focusing on the complete ffmpeg suite. Now I have prepared an audio focused ffmpeg build for the web based on these efforts. I have selected only audio parts which makes the resulting .wasm binary four to five times smaller (from \~20MB to \~5MB). I also provided a simplified Javascript wrapper. The project brings audio decoding to the browser but also audio filtering, transcoding, pitch-shifting, sample rate conversions, audio channel manipulation, and so forth. It is also capable to extract audio streams from video container formats.
Next to the pure functionality of ffmpeg there are general advantages to run audio analysis software in the browser at client-side:
Ease-of-use: no software needs to be installed. The runtime comes with a compatible browser.
Privacy: Since media files are not transferred it is impossible for the system running the service to make unauthorised copies of these files. There is no need to trust the service since all processing happens locally, in the browser.
Speed: Downloading and especially uploading large media files takes a while. When files are kept locally, processing can start immediately and no time is wasted sending bytes over the internet. This results in a snappy user experience.
Computational load: the computational load of transcoding is distributed over the clients and not centralised on a (single) server. The server does not do any computing and only serves static files, so it can handle as many concurrent clients as its bandwidth allows.
PFFFT is a small, pretty fast FFT library programmed in C with a BSD-like license. I have taken it upon myself to compile a WebAssembly version of PFFFT to make it available for browsers and node.js environments. It is called pffft.wasm and available on GitHub.
The pffft.wasm library comes in two flavours. One is compiled with SIMD instructions while the other comes without these instructions. SIMD stands for ‘single instruction, multiple data’ and does what it advertises: in a single step it processes multiple datapoints. The aim of SIMD is to make calculations several times faster. Especially for workloads where the same calculations are repeated over and over again on similar data, SIMD optimisation is relevant. FFT calculation is such a workload.
Evidently the SIMD version is much faster but there is no need to take my word for it. Below you can benchmark the SIMD version of pffft.wasm and compare it with the non-SIMD version on your machine. A pure Javascript FFT library called FFT.js serves as a baseline.
When running the same benchmark on Firefox and on Chrome it becomes clear that FFT.js on Chrome is about twice as fast thanks to its superior Javascript engine for this workload. The performance of the WebAssembly versions in Chrome and Firefox is nearly identical. Safari unfortunately does not (yet) support SIMD WebAssembly binaries and fails to complete the benchmark.
Have you ever found yourself wondering how to build an accurate, low-latency LTC decoder with a common micro-controller? Well! Wonder no more and read on! Or, stop reading and do go read something that is more appealing to your predispositions.
SMPTE timecodes were originally used to synchronize audio and video material. SMPTE timecode data is often encoded into audio using LTC or linear time code. This special audio stream can be recorded together with other audio and video material. By decoding the LTC audio afterwards and working back to SMPTE timecodes, synchronization of multiple camera angles and audio material becomes straightforward. This concept tagging data streams with SMPTE timecodes is also used for other types of data.
\
Fig: LTC is a 'self-clocking' protocol for which a period can be found automatically. Once the period is found, transitions within the period are counted. A period with a transition translates to a 1, a period without any transitions to a 0.
SMPTE timecodes supports up to 30 frames per second and this resolution might not be sufficient for some data streams. It helps if the frames could be split up and 60 or 120 frames per second could be generated. With a low latency LTC decoder it would be possible to support this case and, for example, provide four pulses for every SMPTE frame. To be more precise: a SMPTE frame consists of 80 bits and in this case we would send a pulse exactly when decoding bit 0, bit 20, bit 40 and bit 60. We would then be able to sample at 120Hz while staying in sync with the SMPTE.
My first attempt was to treat the signal like audio and use a ready built library for LTC audio decoding The problem there is that sampling is done which might not exactly match the SMPTE bit transition period and relatively large buffers are used to decode LTC. The bit exact decoding is not possible using this method: the latency is too large, the method also uses excessive computational power and memory.
Fig: Biasing circuit to offset voltages
In my second attempt, the current iteration, interrupts are used to detect rising and falling edges in the LTC stream. By counting the number of microseconds between these edges a bit string is constructed. Effectively decoding LTC without any wasted computational power or memory and at a very low latency. If the LTC stream is well-formed, following each incoming bit and reacting to it becomes straightforward. Finally, after gently massaging the LTC bit string, SMPTE timecodes ooze out of the system at a low latency.
I have implemented a low latency LTC and SMPTE timecode data decoder for a Teensy microcontroller. One of the current limitations is that only 30fps SMPTE without skipped frames is supported. Another limitation is that the precision of the derived 120Hz clock is dependent on the sampling rate of the encoded audio signal: if e.g. only 8000Hz is used, transitions can only be precise up until 125µs. The derived clock will jitter slightly but will not drift.
There is still a slight problem with audio and Teensy input: audio is generally transmitted from ~~1.8V to +1.8V and not~~ as a Teensy would expect - from 0 to 3.3V. To make this change a small biasing circuit is placed before the Teensy input. In my case two 100k resistors and a 0.1uF capacitor worked best. The interrupt is relatively robust against signals that are a clipping (outside the 0 - 3.3V) or slightly too silent. If the signal becomes too small LTC decoding obviously fails.
Panako is an acoustic fingerprinting system I developed a couple of years ago. With acoustic fingerprinting systems it is possible to find duplicates in digital music archives and compare meta-data or identify unlabelled audio fragments. In the margins of my post-doc project working with large music archives, I have found the time to update Panako significantly. The updates simplify, improve and speed up Panako.
\
Fig. General content based audio search scheme.
The main algorithms are simplified. There is also a reduction of dependencies and a refocus to core functionality. This also simplifies building the software. The retrieval characteristics are improved, mainly thanks to the use of a fine-grained Gabor transform. Also new is the near-exact hashing construct which helps with off-by-one issues when matching time bins. The key-value store used is now LMDB, which speeds up the query performance of Panako significantly. The updates should make Panako stand the test of time somewhat better.
\
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.
- The number of dependencies has been drastically cut by removing support for multiple key-value stores.
- The key-value store has been changed to a faster and simpler system (from [MapDB](https://mapdb.org) to [LMDB](http://www.lmdb.tech/doc)).
- The SyncSink functionality has been moved to another project (with Panako as dependency).
- The main algorithms have been replaced with simpler and better working versions:
- Olaf is a new implementation of the classic Shazam algorithm.
- The algoritm described in the Panako paper was also replaced. The core ideas are still the same. The main change is the use of a [Gabor transform](https://en.wikipedia.org/wiki/Gabor_transform) to go from time domain to the spectral domain (previously a constant-q transform was used). The gabor transform is implemented by [JGaborator](https://github.com/JorenSix/JGaborator) which in turn relies on [The Gaborator](https://gaborator.com/) C library via JNI.
- Folder structure has been simplified.
- The UI which was mainly used for debugging has been removed.
- A new set of helper scripts are added in the `scripts` directory. They help with evaluation, parsing results, checking results, building panako, creating documentation,...
- Changed the default panako location to \~/.panako, so users can install and use panako more easily (without need for sudo rights)
I have just released a new version of SyncSink. SyncSink is a tool to synchronize media files with shared audio. It is ideal to synchronize video captured by multiple cameras or audio captured by many microphones. It finds a rough alignment between audio captured from the same event and subsequently refines that offset with a crosscorrelation step. Below you can see SyncSink in action or you can try out SyncSink (you will need ffmpeg and Java installed on your system).
SyncSink used to be part of the Panako acoustic fingerprinting system but I decided that it was better to keep the Panako package focused and made a separate repository for SyncSink. More information can be found at the SyncSink GiHub repo
SyncSink is a tool to synchronize media files with shared audio. SyncSink matches and aligns shared audio and determines offsets in seconds. With these precise offsets it becomes trivial to sync files. SyncSink is, for example, used to synchronize video files: when you have many video captures of the same event, the audio attached to these video captures is used to align and sync multiple (independently operated) cameras.
Evidently, SyncSink can also synchronize audio captured from many (independent) microphones if some environmental sound is shared (leaked in) the each recording.
This post deals with the problem of using stateful C code from multiple Java threads. With JNI (Java Native Interface) it is possible to glue C code to a Java environment. There are many helpful tutorials on how to call C code and receive results. JNI helps to reuse existing, often highly complex and computationally expensive, C code.
The introductory tutorials often stop once it is made clear how to repackage (simple) datatypes and do not mention threads. It is, however, reasonable to expect JNI code to take into account thread-safety and proper multi-threading. In all but the simplest cases it is not that straightforward to share state at the C side and allow JNI code to be called from multiple Java threads. Incorrectly sharing state can lead to memory leaks and segmentation faults (segfaults) and crashes the application. In what follows, a way to share thread-local state is presented.
It is quite common to have an init, work and dispose method to create a state, use that state and do some work and finally dispose of used resources. Each Java thread independently calls these methods and expects results. These results should not change if multiple Java threads are calling the same methods. In other words: the state should remain Java thread-local. A typical Java class could look like the code below.
With the Java code in mind, the C code should know which Java thread is used and which state needs to be used for the work. Luckily there is a way to find out: The JNI specification states that each JNIEnv is local to a Java thread. So we can use the JNIEnv pointer to identify a thread. This is the idea that is used below.
The code maps a JNIEnv pointer to a structure with (any) state information. An unordered map is used for this mapping. There is, however, still a problem: multiple threads can call the init method at once. So multiple threads potentially write to the unordered_map at the same time which leads to problems. To prevent this from happening a mutex is used. The mutex, together with a unique lock, makes sure that only a single thread writes to the unordered map. The same holds for the dispose method.
The work method does not need a unique lock since it does not write to the unordered map and reading from multiple threads is no problem.
#include<unordered_map>#include<mutex>constint DATA_ARRAY_SIZE = 300000 * 2;
struct BridgeState {
jfloat *data;
};
//A hash map with a JNIEnv * as key and a BridgeState * as value
std::unordered_map<uintptr_t, uintptr_t> stateMap;
//A mutex to ensure that writes to the stateMap are synchronized.
std::mutex stateMutex;
JNIEXPORT jint JNICALL Java_init(JNIEnv *env, jobject object) {
//Makes sure only one thread writes to the stateMap
std::unique_lock<std::mutex> lck(stateMutex);
BridgeState *state = new BridgeState();
uintptr_t env_addresss = reinterpret_cast<uintptr_t>(env);
state->data = new jfloat[DATA_ARRAY_SIZE];
uintptr_t state_addresss = reinterpret_cast<uintptr_t>(state);
stateMap[env_addresss] = state_addresss;
return1;
}
JNIEXPORT jint JNICALL Java_work(JNIEnv *env, jobject object) {
//get a ref to the state pointer
uintptr_t env_addresss = reinterpret_cast<uintptr_t>(env);
BridgeState *state = reinterpret_cast<BridgeState *>(stateMap[env_addresss]);
//do something with state->data, e.g. calculate the sumint sum = 0;
for (int i = 0; i < DATA_ARRAY_SIZE; i++) {
state->data[i] = state->data[i] + 1;
sum += (int)state->data[i];
}
return sum;
}
JNIEXPORT jint JNICALL Java_dispose(JNIEnv *env, jobject object) {
//Makes sure only one thread writes to the stateMap
std::unique_lock<std::mutex> lck(stateMutex);
uintptr_t env_addresss = reinterpret_cast<uintptr_t>(env);
BridgeState *state = reinterpret_cast<BridgeState *>(stateMap[env_addresss]);
stateMap.erase(env_addresss);
//cleanup memory
delete[] state->data;
delete state;
return0;
}
This conceptual code has been lifted from a JNI library doing actual work: The JGaborator JNI bridge . If you need more information on how to compile and use this construct in actual code, please have a look at the JGaborator GitHub repository
I have updated the JGaborator library. The library calculates fine grained constant-Q spectral representations of audio signals quickly from Java. Such spectral transform can be used for visualisation or as a front-end for audio processing or music information retrieval applications.
The calculation of a Gabor transform is done by a C library named Gaborator. JGaborator provides a Java native interface (JNI) bridge to that library. Thanks to the recent updates, the library is now automatically unpacked which makes it easy to use on supported platforms (intel macOS and x64 Linux).
The new version of JGaborator now also allows multiple Java threads to call the transform. This has the potential to speed up some audio processing chains dramatically.
The visualisation parts of JGaborator also received light touch-ups. Below a number of screenshots can be seen with of spectral representations of several audio files. If you want to try it yourself download the “JGaborator JAR-file”:[JGaborator-0.6.jar]. Note that it should work only on intel macOS and x64 Linux with ffmpeg installed on your path. For other environments, please read and follow the JGaborator instructions to get it working.
A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.
The prototype gathered dust for a while but the idea stuck in my head. With my daughters fourth birthday approaching during the lockdown, I decided to turn the prototype into an over-engineered birthday gift and let an ‘Elsa-dress’ react to ‘Let It Go’ from the Frozen soundtrack. With the prototype as a starting point, I ordered an RGB-LED-strip, a beefy Li-Ion Battery, an I2S digital microphone and, of course, an Elsa-dress.
I had an ESP32 microcontroller laying around and used it as the core of the system: it supports I²S, has a floating point unit (FPU), is easy to use together with LED strips and has enough memory. The FPU makes it straightforward to use the same code on traditional computers as on embedded devices: fixed-point math can be avoided.
After soldering the components together and with the help from my better half to sew in the LED strip, it all came together. In the video below, the result of our work can be seen. The video first shows a song that should not and is not recognised. Then, “Let It Go” is played and correctly recognised. After the song is stopped, the lights go on for a while and finally stop: this is by design to allow gaps in recognition. Lastly, the song is continued and again correctly recognised.
With my limited C experience the prototype code was not well organised. During my second attempt this improved enough so that I feel comfortable enough to share the code on GitHub: Olaf - Overly Lightweight Acoustic Fingerprinting.
The code went through several iterations and was expanded beyond the original scope and became a capable general purpose acoustic fingerprinting system with its many applications. Olaf performs quite well thanks to its resource friendly design and the use of PFFT and LMDB. Especially LMDB, a fast, B+-tree backed key value store with low storage overhead enables performant storage and lookups.
The GitHub does not contain an example for the ESP32. That code depends on the microcontroller, digital microphone and pins used and Olaf needs to be hacked to exhibit the requested behaviour. All in all that code is much less reusable (and sharable, testable, maintainable). I have, however, included a platformIO project for “Olaf on ESP32”:[ESP32-Olaf.zip] for reference.
WASM: Olaf in the browser
Olaf, being written in ANSI C, can run in the browser thanks to the Emscripten compiler. According to its website, Emscripten ‘…lets you run C and C on the web at near-native speed without plugins’ Combining the Web Audio API and the WASM version of Olaf makes web-based acoustic fingerprinting applications possible.
Below you can try out Olaf. The exact same code is running on your browser as on the ESP32 demonstrated above. This means that Olaf is listening to recognise ‘Let It Go’ from the Frozen soundtrack. For your convenience the song can be started below on the left. On the right, you can start Olaf by allowing incoming audio to be analysed. The FFT is calculated by Olaf and visualised using Pixi.js. After a few seconds the red fingerprints should become green, indicating a match. Once you stop the song, the fingerprints will eventually turn red again. As with the video above: going from a match to no match takes a couple of seconds to allow gaps in recognition.
1. Start the song and play it aloud. Singing along is encouraged.
2. Start the microphone and check whether recognition succeeds.
Olaf was featured on hackaday. There is also a small discussion about Olaf on Hacker News. A write-up of this project also ended up as a contribution to the Late Breaking Demo track of the first virtual ISMIR conference: Olaf ISMIR 2020 LBD abstract.
The audio shield takes care of the line level audio input. This audio input is then decoded. The decoding is done by libltc. The library runs as is on a Teensy without modification. The three elements are combined in a relatively simple teensy patch
To use the decoder connect the line level input left channel to an SMPTE source via e.g. an RCA plug.
For code, comments, pull requests please consult the Github repository for the Teensy SMPTE LTC decoder
During an experiment which monitors a music performance it might be a requirement to record music, video and sensor data synchronously. Recording analog sensors (balance boards, accelerometers, light sensors, distance sensors) together with audio and video is often problematic. Ideally standard DAW software can be used to record both audio and sensor data. A system is presented here that makes it relatively straightforward to record sensor data together with audio/video.
The basic idea is simple: a microcontroller is programmed to appear as a class compliant MIDI device. Analog measurements on the micro-controller are translated to a specific MIDI protocol. The MIDI data, on the capturing side, can then be converted again into the original sensor data. This setup has several advantages:
It makes it easy to record sensor data together with audio data in a standard DAW software package. Recording a recording a midi track and audio track simultaneously in, e.g., Ableton Live, is easy.
Communication with the micro-controller is bi-directional. The micro-controller can be programmed to react to certain MIDI messages. A note-on can, for example, be used to start analog sensor recording. These MIDI commands can be send from any possible source that can ‘speak’ MIDI.
Thanks to the Web MIDI API this construct presents an easy way to let analog sensors and websites interact.
Real time sonification of the sensor-data is also supported. There are many ready to go options to sonify MIDI. Axoloti, Max/MSP, Zupiter are some of the environments that can be pugged into.
Fig: Visualization in html of analog sensor data, captured as MIDI
While the concept is relatively simple, there are many details to get right. Please consult the MIDImorphosis github page which details the system that consists of an analog sensor, a MIDI protocol and a clocking infrastructure.
At work we have a really nice piano and I wanted to be able to broadcast a live performance over the internet with low latency to potential live listeners. In all honesty, only my significant other gets moderately lukewarm about the idea of hearing me play live. Anyhow:
I did not find any practical tool to easily pump audio over the internet. I did find something that was very close called trx by Mark Hills: trx is a simple toolset for broadcasting live audio from Linux. It unfortunately only works with the ALSA audio system and is limited to Linux. I decided to extend it to support macOS and Pulse Audio. I also extended its name to form trix.
Audio Transmitter/Receiver over Ip eXchange (trix) is a simple toolset for broadcasting live audio from Linux or macOS. It sends and receives encoded audio over IP networks, via an audio interface. If audio interfaces are properly configured, a low-latency point-to-point or multicast broadband audio connection can be achieved. This could be used for networked music performances. The inclusion of the intermediate rtAudio library provides support for various audio input and outputs.
More information on trix can be found on the trix github page.
Latency
The system can be configured for low latency use. The whole chain is dependent several different components which each add to the total latency: audio input latency, encoder (algorithmic) delay, network latency and finally audio output latency.
Thanks to the use of RtAudio it should be possible to use low latency API’s to access audio devices (ASIO on windows or Jack on Unix). This means that audio input and output latencies can be as low as the hardware allows. The opus encoder/decoder that is used has a low algorithmic delay. By default it has a 25ms delay but it can be configured to only 2.5ms (see here). The network latency (and jitter) is very much dependent on the distance to cover. On a local network this can be kept low, when using wide area networks (the internet) control is lost and latencies can add up depending on the number of hops to take. Jitter can be problematic if the smallest possible buffers are used: then dropouts might occur and this might affect the audio in a noticeable way.
I have uploaded a small piece of software which allows users to find a specific audio marker in audio streams. It is mainly practical to synchronise a camera (audio/video) recording with other audio with the same marker. The marker is a set of three beeps. These three beeps are found with millisecond accurate precision within the audio streams under analysis. By comparing the timing of marker synchronization becomes possible. It can be regarded as an alternative for the movie clapper boards.
Recently I have published a small library on github called JGaborator. The library calculates fine grained constant-Q spectral representations of audio signals quickly from Java. The calculation of a Gabor transform is done by a C library named Gaborator. A Java native interface (JNI) bridge to the C Gaborator is provided. A combination of Gaborator and a fast FFT library (such as pfft) allows fine grained constant-Q transforms at a rate of about 200 times real-time on moderate hardware. It can serve as a front-end for several audio processing or MIR applications.
While the gaborator allows reversible transforms, only a forward transform (from time domain to the spectral domain) is currently supported from Java.A spectral visualization tool for sprectral information is part of this package. See below for a screenshot:
The 2017 AES international conference on semantic audio was organized at ISS Fraunhofer, Erlangen, Germany. As the birthplace of the MP3 codec, it is holy ground, a stop that can not be skipped on the itinerary of an audio engineers pilgrimage of life. At the conference I presented “ A framework to provide fine-grained time-dependent context for active listening experiences”:[2017.author.aes.pdf] with a poster (“pdf”:[aes_2017_poster.pdf], “inkscape svg”:[aes_2017_poster_2.svg]).
The “active listening demo movie”:[active_listening_demo_movie.mp4] above should explain the aim system succinctly. It shows two different ways to provide ‘context’ to audio playing in the room. In the first instance beats information is used to synchronize smartphones and flash the screen, the second demo shows a tactile feedback device responding to beats. The device is a soundbrenner pulse tactile metronome and was kindly sponsored by the company that sells these.
The Mi Band is a bracelet with some sensors, three RGB leds and a vibration motor. It is marketed as an activity tracker and notifier. It is a neat little device that communicates via Bluetooth LE and has a battery life of around 30 days. It would be nice if it could be used for whatever purpose you want but alas, its API is not very open. This blog post gives pointers to useful resources and tips to make it work with your own code.
I would advise against installing the official Mi Band app, if you want to use it with custom code. The app upgrades the firmware to the latest version and it seems that Xiaomi is obfuscating the protocol more and more with each version. I was able to send vibrate and led commands to a Mi Band with firmware version 10.0.9.3. With the previously mentioned sources and the flow described to the right the device reacts to commands. I used an Android device. The flow:
Pair with the Mi Band in the Android Bluetooth setting.
In your code, connect to the paired device. Save the device address, you will need it later.
Send a pair command to the device. This is part of the Mi Band protocol and has nothing to do with the previous Bluetooth pairing. If all goes well it reacts with a 2. See here
Send user info. This step is crucial and not trivial. The user info needs to be encoded in a certain way and is CRC’d with the device address. The following is an example implementation of the Mi Band user info encoding
Now you can send vibrate or other commands.
Some notes: the self-test command works without the set user step. For Android the Mi Band protocol implementation in Java works well. To check the firmware version of the device, call the get device info characteristic. The last bytes, interpreted as an integer, define the version info. For my device it is 10.9.3.2:
Write to characteristic 0000ff05-0000-1000-8000-00805f9b34fb
onCharacteristicWrite status: 0 characteristic 0000ff05-0000-1000-8000-00805f9b34fb
Read firmware version
11value: 212value: 313value: 914value: 015value: 1
Another note: the set user info needs to be called with a 1 as type the first time the band is used. This is done with new UserInfo(20111111, 1, 32, 180, 55, "NM", 1) with the Android sdk by GitHub user pangliang. This sets and overwrites the user info. The next times you do not want to overwrite the info and the type needs to be zero.
The article titled “Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment” by Joren Six and Marc Leman has been accepted for publication in the Journal on Multimodal User Interfaces. The article will be published later this year. It describes and tests a method to synchronize data-streams. Below you can find the abstract, pointers to the software under discussion and an author version of the article itself.
Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment An Application of Acoustic Fingerprinting to Facilitate Music Interaction Research
Abstract:Research on the interaction between movement and music often involves analysis of multi-track audio, video streams and sensor data. To facilitate such research a framework is presented here that allows synchronization of multimodal data. A low cost approach is proposed to synchronize streams by embedding ambient audio into each data-stream. This effectively reduces the synchronization problem to audio-to-audio alignment. As a part of the framework a robust, computationally efficient audio-to-audio alignment algorithm is presented for reliable synchronization of embedded audio streams of varying quality. The algorithm uses audio fingerprinting techniques to measure offsets. It also identifies drift and dropped samples, which makes it possible to find a synchronization solution under such circumstances as well. The framework is evaluated with synthetic signals and a case study, showing millisecond accurate synchronization.
The algorithm under discussion is included in Panako an audio fingerprinting system but is also available for download here. The SyncSink application has been packaged separately for ease of use.
To use the application start it with double click the downloaded SyncSink JAR-file. Subsequently add various audio or video files using drag and drop. If the same audio is found in the various media files a time-box plot appears, as in the screenshot below. To add corresponding data-files click one of the boxes on the timeline and choose a data file that is synchronized with the audio. The data-file should be a CSV-file. The separator should be ‘,’ and the first column should contain a time-stamp in fractional seconds. After pressing Sync a new CSV-file is created with the first column containing correctly shifted time stamps. If this is done for multiple files, a synchronized sensor-stream is created. Also, ffmpeg commands to synchronize the media files themselves are printed to the command line.
This work was supported by funding by a Methusalem grant from the Flemish Government, Belgium. Special thanks goes to Ivan Schepers for building the balance boards used in the case study. If you want to cite the article, use the following BiBTeX:
@article{six2015multimodal,
author = {Joren Six and Marc Leman},
title = {{Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment}},
issn = {1783-7677},
volume = {9},
number = {3},
pages = {223-229},
doi = {10.1007/s12193-015-0196-1},
journal = {{Journal of Multimodal User Interfaces}},
publisher = {Springer Berlin Heidelberg},
year = 2015
}
A microcontroller fitted with an electret microphone and a microSD card slot. It can record audio in real-time together with sensor data.
Conceptual drawing used as a basis for the SyncSync application. A reference stream (blue) can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).
SyncSink Synchronize media files. A user-friendly interface to synchronize media and data files. First a reference media-file is added using drag-and-drop. The audio steam of the reference is extracted and plotted on a timeline as the topmost box. Subsequently other media-files are added. The offsets with respect to the reference are calculated and plotted. CSV-files with timestamps and data recorded in sync with a stream can be attached to a respective audio stream. Finally, after pressing Sync!, the data and media files are modified to be exactly in sync with the reference.
Multimodal recording system diagram. Each webcam has a microphone and is connected to the pc via USB. The dashed arrows represent analog signals. The balance board has four analog sensors but these are simplified to one connection in the schematic. The analog output of the microphones is also recorded through the DAQ. An analog accelerometer is connected with a microcontroller which also records audio.
Two streams of audio with fingerprints marked. Some fingerprints are present in both streams (green, O) while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.
Synchronized streams in Sonic Visualizer. Here you can see two channel audio synchronized with accelerometer data (top, green) and balanceboard data (bottom, purple).
The synchronized data from the two webcams, accelerometer and balanceboard in ELAN. From top to bottom the synchronized streams are two video-streams, balance-board data (red), accelerometer-data (green) and audio (black).
This post explains how to do real-time pitch-shifting and audio time-stretching in Java. It uses two components. The first component is a high quality software C library for audio time-stretching and pitch-shifting C called Rubber Band. The second component is a Java audio library called TarsosDSP. To bridge the gap between the two JNI (Java Native Interface) is used. Rubber Band provides a JNI interface and starting from the currently unreleased version 1.8.2, makefiles are provided that make compiling and subsequently using the JNI version of Rubber Band relatively straightforward.
However, it still requires some effort to control real-time pitch-shifting and audio time-stretching from java. To make it more easy some example code and documentation is available in a GitHub repository called RubberBandJNI. It documents some of the configuration steps needed to get things working. It also offers precompiled libraries and documents how to compile those for the following systems:
This post describes a tool to quickly visualize and record analog signals with a Teensy micro-controller and some custom software. It is mainly useful to quickly get an idea of how an analog sensor reacts to different stimuli. Since it is also able to capture and store analog input siginals it is also useful to generate test data recordings which then can be used for example to test a peak detection algorithm on. The tool is called TeensyDAQ hinting at the Data AcQuisition features and the micro-controller used.
Some of the features of the TeensyDAQ:
Visualize up to five analog signals simultaneously in real-time.
Capture analog input signals with sampling rates up to 8000Hz.
Record analog input to a CSV-file and, using drag-and-drop, previously recorded CSV-files can be visualized.
Works on Linux, Mac OS X and Windows.
While a capture session is in progress you can going back in time and zoom, pan and drag to get a detailed view on your data.
Allows you to listen to your input signal, this is especially practical with analog microphone input.
The system consists of two parts. A hardware and a software part. The hardware is a Teensy micro-controller running an Arduino sketch that ready analog input A0 to A4 at the requested sampling rate. A Teensy is used instead of a regular Arduino for two reasons. First the Teensy is capable of much higher data throughput, it is able to send five reading at 8000Hz, which is impossible on Arduino. The second reason is the 13bit analog read resolution. Classic Arduino only provides 10 bits.
The software part reads data from the serial port the Teensy is attached to. It interprets the data and stores it in an efficient data-structure. As quickly as possible the data is visualized. The software is written in Java. A recent Java runtime environment is needed to execute it.
This post describes how to get notifications from a Bluetooth LE (Low Energy) or Bluetooth v4.0 device on a Linux machine. Since it took me a while to get it going it is perhaps of interest to others.
The hardware I used is an RFduino board and a Belikin mini Bluethooth v4.0 adapter. The RFduino was programmed to wait for an event with RFduino_pinWake(pni, HIGH). When the pin is HIGH a count is incremented and this number is send to any device that is listening. In my case a Linux machine. The code is essentially the same as the button example included in the RDduino software distribution.
To install the Bluetooth stack on Debian the following command is executed sudo apt-get install bluetooth bluez bluez-utils bluez-firmware. A blog post describes more about the Bluetooth tools. Some other interesting reads are Get started with Bluetooth Low Energy and this stackoverflow question. Once the stack is installed correctly the lescan utility should give an output like this:
Bluetooth LE works with the Generic Attribute Profile (GATT). A Bluetooth LE device can provide services by combining characteristics. These characteristics are the way to communicate with the device. Some characteristics are writable and are able to send notifications. To receive notifications one such characteristic (referred to with a hex handle) needs to be written. Write 0100 to get notifications, 0200 for indications (indications are notifications that are acknowledged), 0300 for both, or 0000 for nothing (default). With this in mind, the following command enables listening for notifications:
With those commands working, the process can be automated with “a Ruby script to get Bluetooth LE notifications”:[bluetooth_notifications.rb]. The script essentially calls gatttool with the correct parameters and parses and reacts to its output. To make it work lescan needs to be called before starting the script:
This post describes how to connect music in your library with precomputed features. Say, for example, you are developing a DJ application and you want to facilitate mixing tracks. To provide a seamless mix you perhaps want information about beats and about the key the music in your library is in. Since vast databases of features are already available you probably want to access those, instead of using your own feature extractors and database. The problems that need to be addressed are:
Automatically identify the music in your library without relying on incomplete meta-data (tag information).
Connect the music with a data-base of meta-data. Preferably a large and well curated database.
Fetch pre-computed features for the music. The features should be extracted using algorithms that are currently state of the art or at least perform well. The features and the audio itself should be synchronized, otherwise beat information, for example, is not of much use.
To help with these task there are several open source tools and services available.
To identify music a condensed representation of musical audio is created. This process is known as acoustic fingerprinting. On the website AcoustID a tool is available to create such fingerprint. The library is called Chromaprint and the command line client is called fpcalc. Currently the latest version is Chromaprint version 1.2 and static binaries for fpcalc are available on the AcoustID website. A packages for Debian (and probably Ubuntu) can be installed by calling apt-get install libchromaprint-tools. Once this tool is correctly installed a fingerprint for a piece of music can be created:
A fingerprint by itself is not of much use. The AcoustID webservice translates a fingerprint into one or more MusicBrainz identifiers. One fingerprint can result in multiple identifiers because the same audio can be released on several albums. There is documentation for AcoustID webservice available. To use the webservice an API key is needed. Confusingly, the AcoustID service has two types of API keys. One for end-users and one for developers. The last type is needed to translate ID’s. To request a developer API key, log in on the AcoustID website and “add an application”, there you can find the correct API key. Substitute dev_api_key in the following URL. Also change the fingerprint and duration to match the information provided by the fpcalc application. The webservice should reply with a set of MusicBrainz identifiers:
AcousticBrainz provides features for a subset of music that has a MusicBrainz identifier. Currently about a million tracks are analyzed but more are added every day. The API for the webservice is straightforward:
The low-level features include beat positions and chroma information. For the hypothetical DJ-application this is the information that would be used.
If you find the services useful please consider contributing to MusicBrainz, AcoustID and AcousticBrainz.
A small Ruby script to “automatically fetch features”:[mbid_lookup.rb] for audio can be downloaded here. It needs Ruby and a RubyGems to parse JSON. On Debian this can be installed with apt-get install ruby and rubygems install json. Once these dependencies are installed the script can be ran as follows:
ruby mbid_lookup.rb example.mp3
Found6 musicbrainz identifiers!
Not found inAcousticBrainz: 0afcd4a1-3709-499b-b76f-0d5491f839a5
Beat positions for3d49fab8-fd08-42be-b0d2-9f1dc884d902: 0.522448956966,1.05650794506,1.57895684242,2.10140585899,2.61224484444,3.13469386101Not found inAcousticBrainz: 448258f0-aa5a-4968-8efd-8c9348d5142e
Not found inAcousticBrainz: adcd7079-57d9-49bd-a36b-a20fa27b02b1
Beat positions for d1cd1321-0b66-4848-935e-f3afba6c7356: 0.441179126501,0.905578196049,1.369977355,1.83437633514,2.29877543449,2.76317453384Not found inAcousticBrainz: e1f433be-af6b-4b5d-a969-4b53f014c395
TarsosDSP is a real-time audio processing library written in Java. Since version 2.0 it is compatible with Android. Judging by the number of forks of the TarsosDSP GitHub repository Android compatibility increased the popularity of the library. Now the first Android application which uses TarsosDSP has found its way to the Google Play store. Download and play with SINGmaster to see an application of the pitch tracking capabilities within TarsosDSP. The SINGmaster description:
“SING master is a smart phone app that helps you to learn how to sing. SING master presents a collection of practical exercises (on the most important building blocks of melodies). Colours and sounds guide you in the exercise. After recording, SING master gives visual feedback : you can see and hear your voice. This is important so that you can identify where your mistakes are.”
Another application in the Play Store that uses TarsosDSP is CuePitcher.
This post explains how to receive OSC in a MatLab environment. It uses a platform independent Java library which should work on 64 and 32 bit versions of Windows, Unix and Mac OS X. Using Java makes installation relatively easy compared with other solutions.
The most used method to get OSC-messages in Matlab can be found here. This method uses a library called liblo which needs to be configured (compiled) correctly on your system. Especially on Windows this can be problematic. A brave soul documented his quest to get OSC working with Matlab on Windows here. Obviously not for the faint of heart.
An alternative way leverages the Matlab facilities to run Java. Since there is a Java OSC library available (JavaOSC on github) it is relatively easy to bridge the two. To make the connection, I have written some glue code and provide an easy to use Jar-library here. Using the bridge is done as follows:
How to make Matlab receive OSC-messages
Download the “JavaOSCtoMatlab Java library”:[javaosctomatlab.jar] and store it in an easy to remember directory.
Download the “example Matlab OSC client Script”:[osc_java_test.m] and store it in the same directory. The client is included below as well.
Start Matlab, modify the client script to fit your needs. You probably need to change the OSC method to listen to and the OSC port. Also make sure that the cd command points to the directory with the downloaded jar-file.
Run the client script and receive your OSC messages.
Note that there are three ways to receive the payload of a message. They are returned by the Java code as either Object[], double[] or String[]. The last two are automatically understood by Matlab, so they are more easy to work with. Respectively to get the message data you need to call either osc_listener.getMessageArguments(), osc_listener.getMessageArgumentsAsDouble(), osc_listener.getMessageArgumentsAsString().
This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).
Audio latency is an important aspect of a system, especially if it is used for real-time sonification or for musical applications. Audio latency is the, preferably short, delay between audio entering a system and emerging from a system. Audio output latency is the time it takes between a signal (e.g. a button pressed) and when audio emerges. For sonification purposes audio output latency is more interesting than round-trip audio latency.
Android systems are often portable, generally available and relatively cheap. Android offers an attractive platform to develop sonifications or musical applications for. Unfortunately, audio latency on Android has not been a priority in the first versions. With Android 4.1 things started to change but due to hard- and software fragmentation it is still hard to find how much audio latency is expected. Even if the exact model (e.g. Nexus 5) and software version (stock Android 5.0) is known, exact numbers are, so it seems, nowhere to be found. For more information on the internal changes that make low latency audio on Android possible, watch the talk on High Performance Audio from the 2013 Google I/O conference. Also note the lack of exact latency numbers in that talk. It is a very enjoyable talk by two Google engineers going after the culprits of high latency in true Sherlock/dr. Watson style.
Since audio output latency is generally not documented and since it is an important factor to decide if Android is a viable platform for real-time sonification or musical applications it needs to be measured. One way of measuring audio output latency on Android is documented by the people of Google. Unfortunately, the approach is not easily reproducible since it needs a custom circuit board, an oscilloscope and there is no source code available. Below a reproducible way to measure audio output latency for Android is documented.
An Arduino, an Android device, an USB-OTG cable and a butchered mini-jack audio cable are needed together with the software provided here. Optionally, a data acquisition module can be used to visualize the signals. The measurement system works as follows:
An Arduino sends a signal over USB. The time at which the signal is send is stored for later use.
An Android device, connected to the Arduino via an USB-OTG-cable, receives the signal.
The Android device responds as quickly as possible, with the lowest latency as possible, by emitting a sound.
The sound is captured on an analog input port of the Arduino, via the mini-jack cable. The time the sound appears on the Arduino is stored.
By comparing the time when the signal was send with the time when the sound arrived, the audio output latency is measured and reported.
The previous steps are repeated every second to gain insights into the variability of the measurements. To generate microsecond accurate timing interrupts are used on the Arduino. For visualisation, a digital pin is toggled every time the Arduino sends a signal. The Arduino sketch is attached to this post, as is the source code for the Android application. An already compiled APK is also available. With some luck - a recent Android version is needed, your device should support USB-OTG - it might work on your device.
Results
Using the OpenSL ES native interface on a Nexus 5 with Lollipop installed the USB input to audio output latency is on average about 48 milliseconds. There is some variability but it is usually within 15 milliseconds. For music applications this latency is not great but, depending on the application, acceptable. For expert drummers latency should be in the range of 20ms but for many sonification tasks, 50ms suffices. It is clear that Android will never be able to compete with purpose built hardware running a real time operating system like Axoloti (Audio roundtrip latency 2ms, usb-audio 1.6ms) but for a general purpose device the measured latency is significantly better than what I expected (around 100ms).
The non-native audio interface is a lot slower. I have measured an average latency of about 85ms and a much larger variability (25ms).
With this post I hope others will report the latency for their devices as well, so that buyers that are interested in a low-latency Android devices can make an informed decision.
Onsets and audio visualized using a DAC and a Java program.
TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbor search algorithm for high dimensional vectors that operates in sublinear time. The open source software package is authored by me and is available on GitHub: TarsosLSH on GitHub.
With TarsosLSH, Joseph Hwang and Nicholas Kwon from Rice University created an Image Mosaic web application. The application chops an uploaded photo into small blocks. For each block, a color histogram is created and compared with an index of color histograms of reference images. Subsequently each block is replaced with one of the top three nearest neighbors, creating a mosaic. Since high dimensional nearest neighbor search is needed, this is an ideal application for TarsosLSH. The application somewhat proves that TarsosLSH can be used in practical applications, which is comforting.
The Starry Night, by Van Ghogh in Mosaic as created by the mosaic webapplication.
Below some notes on installing and using the drivers for the Avandtech USB-4716 on Linux can be found. Since I was unable to find these instructions elsewhere and it took me some time to figure things out, it is perhaps of use to someone else. A similar approach should work for the following devices as well: pci1715, pci1724, pci1734, pci1752, pci1758, pcigpdc, usb4711a, usb4750, pci1711, pci1716, pci1727, pci1747, pci1753_mic3753_pcm3753i, pci1761_pcm3761i, pcm3810i, usb4716, usb4761, pci1714_pcie1744, pci1721, pci1730_pcm3730i, pci1750, pci1756, pci1762, usb4702_usb4704, usb4718
Download the linux driver for the Avandtech USB-4716 DAQ. If you are on a system that can install either deb or rpm use the driver_package. Unzip the package. The driver is split into two parts. A base driver biokernbase and a driver specific for the USB-4716 device, bio4716. The drivers are Linux kernel modules that need to installed. First the base driver needs to be installed, the order is important. After the base driver install the device specific deb kernel module. After a reboot or perhaps immediately this should be the result of executing lsmod | grep bio:
A library to interface with the hardware is provided as a deb package as well. Install this library on your system.
Next download the the examples for the Avandtech USB-4716 DAQ. With the kernel modules installed the system is ready to test the examples in the provided examples directory. If you are using the Java code, make sure to set the java.library.path correctly.
This post contains some info on how do some basic home automation: it shows how cheap remote controlled power sockets can be managed using a computer. The aim is to power on or power off lights, a stereo or other devices remotely from a command shell.
The solution here uses an Arduino connected to a 433.33MHz transmitter. Via a Ruby script installed on the computer a command is send over serial to the Arduino. Subsequently the Arduino sends the command over the air to the power socket(s). If all goes well the power socket reacts by switching the connecting device on or off.
In the video below the process is shown. The command line interface controls the light via the Arduino. It should show the general idea.
The following Ruby script simply sends the binary control codes to the Arduino. For this type of power socket the code consist of a five bit group code and five bit device code. The Arduino is connected to /dev/tty.usbmodem411.
The code below is the complete Arduino sketch. It uses the RCSwich library, which makes the implementation very simple. Essentially it waits for a complete command and transmits it through the connected transmitter. The transmitter connected is a tx433n
```ruby\
#include <RCSwitch.h>
RCSwitch mySwitch = RCSwitch();
char command[12];//2x5 for device and group + command\
int index = 0;\
char currentChar = –1;
//the led pin in use\
int ledPin = 12;
void setup() {\
//start the serial communication\
Serial.begin(9600);\
// 433MHZ Transmitter is connected to Arduino Pin #10\
mySwitch.enableTransmit(10);\
//Led connected to led pin\
pinMode(ledPin, OUTPUT);\
Serial.println(“Started the power command center! Mwoehahaha!”);\
}
void readCommand(){\
//read a command\
while (Serial.available() > 0){\
if(index < 11){\
currentChar = Serial.read(); // Read a character\
command[index] = currentChar; // Store it\
index; // Increment where to write next\
command[index] = ‘\0’; // append termination char\
}\
}\
}
void loop() {\
//read a command\
readCommand();\
//if a command is complete\
if(index == 11){\
Serial.print(“Recieved command: “);\
Serial.println(command);\
char operation = command[0];\
char* group = &command[1];\
//group is 5 bits, as is device\
char* device = &command[6];
//execute the operation\
doSwitch(operation,group,device);\
//reset the index to read a new command\
index=0;\
}\
}
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a Constant-Q Transform (as of version 1.6). The Constant-Q transform does essentially the same thing as an FFT, but has the advantage that each octave has the same amount of bins. This makes the Constant-Q transform practical for applications processing music. If, for example, 12 bins per octave are chosen, these can correspond with the western musical scale.
Also included in the newest release (version 1.7) is a way to visualize the transform, or other musical features. The visualization implementation is done together with Thomas Stubbe.
The example application below shows the Constant-Q transform with an overlay of pitch estimations. The corresponding waveform is also shown.
TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbour search algorithm for multidimensional vectors that operates in sublinear time. It supports several Locality Sensitive Hashing (LSH) families: the Euclidean hash family (L2), city block hash family (L1) and cosine hash family. The library tries to hit the sweet spot between being capable enough to get real tasks done, and compact enough to serve as a demonstration on how LSH works. It relates to the Tarsos project because it is a practical way to search for and compare musical features.
<code>git clone https://JorenSix@github.com/JorenSix/TarsosLSH.git
cd TarsosLSH/build
ant #Builds the core TarsosLSH library
ant javadoc #build the API documentation
</code>
\
When everything runs correctly you should be able to run the command line application, and have the latest version of the TarsosLSH library for inclusion in your projects. Also, the Javadoc documentation for the API should be available in TarsosLSH/doc. Drop me a line if you use TarsosLSH in your project. Always nice to hear how this software is used.
The fastest way to get something on your screen is executing this on your command line: java - jar TarsosLSH.jar this lets LSH run on a random data set. The full reference of the command line application is included below:
Name
TarsosLSH: finds the nearest neighbours in a data set quickly, using LSH.
Synopsis
java - jar TarsosLSH.jar [options] dataset.txt queries.txt
Description
Tries to find nearest neighbours for each vector in the
query file, using Euclidean (L2) distance by default.
Both dataset.txt and queries.txt have a similar format:
an optional identifier for the vector and a list of N
coordinates (which should be doubles).
[Identifier] coord1 coord2 ... coordN
[Identifier] coord1 coord2 ... coordN
For an example data set with two elements and 4 dimensions:
Hans 12 24 18.5 -45.6
Jane 13 19 -12.0 49.8
Options are:
-f cos|l1|l2
Defines the hash family to use:
l1 City block hash family (L1)
l2 Euclidean hash family(L2)
cos Cosine distance hash family
-r radius
Defines the radius in which near neighbours should
be found. Should be a double. By default a reasonable
radius is determined automatically.
-h n_hashes
An integer that determines the number of hashes to
use. By default 4, 32 for the cosine hash family.
-t n_tables
An integer that determines the number of hash tables,
each with n_hashes, to use. By default 4.
-n n_neighbours
Number of neighbours in the neighbourhood, defaults to 3.
-b
Benchmark the settings.
--help
Prints this helpful message.
Examples
Search for nearest neighbours using the l2 hash family with a radius of 500
and utilizing 5 hash tables, each with 3 hashes.
java - jar TarsosLSH.jar -f l2 -r 500 -h 3 -t 5 dataset.txt queries.txt
Source Code Organization
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
Further Reading
This section includes a links to resources used to implement this library.
The LSH-page maintained by Alexandr Andoni contains pointers to good resources:
Locality-Sensitive Hashing Scheme Based on p-Stable Distributions a chapter by Alexandr Andoni, Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab Mirrokni which appeared in the book Nearest Neighbor Methods in Learning and Vision: Theory and Practice, by T. Darrell and P. Indyk and G. Shakhnarovich (eds.), MIT Press, 2006.
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize cat sounds. The inspration came from this youtube video
To hear what exactly it does, listen to the following audio example.
There is also a command line interface, the following command does
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4). The goal of pitch shifting is to change the pitch of a piece of audio without affecting the duration. The algorithm implemented is a combination of resampling and time stretching. Resampling changes the pitch of the audio, but affects the total duration. Consecutively, the duration of the audio is stretched to the original (without affecting pitch) with time stretching. The result is very similar to phase vocoding.
The example application below shows how to pitch shift input from the microphone in real-time, or pitch shift a recorded track with the TarsosDSP library.
To test the application, download and execute the PitchShift.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command lowers the pitch of in.wav by two semitones.
java -jar in.wav out.wav -200
----------------------------------------------------
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Pitch shifting utility.
----------------------------------------------------
Synopsis:
java -jar PitchShift.jar source.wav target.wav cents
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the pitch shifted file.
cents Pitch shifting in cents: 100 means one semitone up,
-100 one down, 0 is no change. 1200 is one octave up.
The resampling feature was implemented with libresample4j by Laszlo Systems. libresample4j is a Java port of Dominic Mazzoni’s libresample 0.1.3, which is in turn based on Julius Smith’s Resample 1.7 library.
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
The Amsterdam Music Hack Day is a full weekend of hacking in which participants will conceptualize, create and present their projects. Music + software + mobile + hardware + art + the web. Anything goes as long as it’s music related
The hackathon was organized at the NiMK(Nederlands instituut voor Media Kunst) the 25th and 24th of May. My hack tries to let a phone start a conversation on its own. It does this by speaking a text and listening to the spoken text with speech recognition. The speech recognition introduces all kinds of interesting permutations of the original text. The recognized text is spoken again and so a dreamlike, unique nonsensical discussion starts. It lets you hear what goes on in the mind of the phone.
The idea is based on Alvin Lucier’s I am Sitting in a Room form 1969 which is embedded below. He used analogue tapes to generate a similar recursive loop. It is a better implementation of something I did a couple of years ago.
The implementation is done with Android and its API’s. Both speech recognition and text to speech are available on android. Those API’s are used and a user interface shows the recognized text. An example of a session can be found below:
To install the application you can download “Tryalogue.apk”:[Tryalogue.apk] of use the QR-code below. You need Android 2.3 with Voice Recognition and TTS installed. Also needed is an internet connection. “The source”:[Tryalogue.zip] is also up for grabs.
The Dan Ellis implementation is nicely documented here: Robust Landmark-Based Audio Fingerprinting . To download, get info about and decode mp3’s some external binaries are needed:
```bash\
#install octave if needed\
sudo apt-get install octave3.2\
#Install the required dependencies for the script\
sudo apt-get install mp3info curl
mpg123 is not present as a package, install from source:\
wget http://www.mpg123.de/download/mpg123-1.13.5.tar.bz2\
tar xvvf mpg123-1.13.5.tar.bz2\
cd mpg123-1.13.5/\
./configure\
make\
sudo make install\
```
In mp3read.m the following code was changed (line 111 and 112):
```matlab\
mpg123 = ‘mpg123’; % was fullfile(path,[‘mpg123.’,ext]);\
mp3info = ‘mp3info’; % was fullfile(path,[‘mp3info.’,ext]);\
```
Then, the demo program runs flawlessly when executing octave -q demo_fingerprint.m.
Running the demo with the original code with GNU Octave, version 3.2.3 takes 152 seconds on a PC with a Q9650 @ 3GHz processor. A small tweak can make it run almost 8 times faster. When working with larger data sets (10k audio files) this makes a big difference. I do not know why but storing a hash in the large hash table was really slow (0.5s per hash, with 900 hashes per song…). Caching the hashes and adding them all at once makes it faster (at least in Octave, YMMV). The optimized version of “record_hashes.m”:[record_hashes.m.txt] can be found attached. With this alteration the same demo ran in 20s. When caching the data locally the difference is 11.5s to 141s or 12 times faster. The code with all the changes can be found here: “Robust Landmark-Based Audio Fingerprinting - optimized for Octave 3.2”:[fingerprint_fast.zip]. Please note again that the implementation is done by Dan Ellis (2009) ( available on Robust Landmark-Based Audio Fingerprinting) and I did only some small tweaks.
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of an audio echo effect. An echo effect is very simple to implement digitally and can serve as a good example of a DSP operation.
"":\[Delay.jar\]
The implementation of the effect can be seen below. As can be seen, to achieve an echo one simply needs to mix the current sample i with a delayed sample present in echoBuffer with a certain decay factor. The length of the buffer and the decay are the defining parameters for the sound of the echo. To fill the echo buffer the current sample is stored (line 4). Looping through the echo buffer is done by incrementing the position pointer and resetting it at the correct time (lines 6-9).
```java\
//output is the input added with the decayed echo\
audioFloatBuffer[i] = audioFloatBuffer[i] + echoBuffer[position] * decay;\
//store the sample in the buffer;\
echoBuffer[position] = audioFloatBuffer[i];\
//increment the echo buffer position\
position;\
//loop in the echo buffer\
if(position == echoBuffer.length)\
position = 0;\
```
To test the application, download and execute the “Delay.jar”:[Delay.jar] file and start singing in a microphone.
The source code of the Java implementation can be found on the TarsosDSP github page.
This is post presents a better version of the spectrogram implementation. Now it is included as an example in TarsosDSP, a small java audio processing library. The application show a live spectrogram, calculated using an FFT and the detected fundamental frequency (in red).
To test the application, download and execute the “Spectrogram.jar”:[Spectrogram.jar] file and start singing in a microphone.
There is also a command line interface, the following command shows the spectrum for in.wav:
\
java -jar Spectrogram.jar in.wav\
The source code of the Java implementation can be found on the TarsosDSP github page.
Tarsos contains a couple of useful command line applications. They can be used to execute common tasks on lots of files. Dowload Tarsos and call the applications using the following format:
The first part java -jar tarsos.jar tells the Java Runtime to start the correct application. The first argument for Tarsos defines the command line application to execute. Depending on the command, required arguments and options can follow.
To get a list of available commands, type java -jar tarsos.jar -h. If you want more information about a command type java -jar tarsos.jar command -h
Detect Pitch
Detects pitch for one or more input audio files using a pitch detector. If a directory is given it traverses the directory recursively. It writes CSV data to standard out with five columns. The first is the start of the analyzed window (seconds), the second the estimated pitch, the third the saillence of the pitch. The name of the algorithm follows and the last column shows the original filename.
A small part of Tarsos has been turned into a audio fingerprinting application. The idea of audio fingerprinting is to create a condensed representation of an audio file. A perceptually similar audio file should generate similar fingerprints. To test how robust a fingerprinting technique is, a data set with audio files that are alike in some way is practical.
SoX - Sound eXchange is a command line utility for sound processing. It can apply audio effects to a sound. Using these effects and a set of unmodified songs an audio fingerprinting data set can be created. To generate such a data set SoX can be used to:
Trim the first x seconds of a file
Speed-up or slow-down the audio
Change the pitch of a file without modifying the tempo
Generate background noise (white noise is used)
Reverse the audio stream
```ruby\
#Trim the first 10 seconds\
sox input.wav output.wav trim 10
speed-up of 10%\
sox input.wav output.wav speed 1.10
change the pitch upwards 100 cents (one semitone)\
#without changing the tempo\
sox input.wav output.wav pitch 100
generate white noise with the length of input.wav\
sox input.wav noise.wav synth whitenoise\
#mix the white noise with the input to generate noisy output\
#-v defines how loud the white noise is\
sox -m input.wav -v 0.1 noise.wav output.wav
reverse the audio\
sox input.wav output.wav reverse\
```
A ruby script to generate a lot of these files can be found “attached”:[audio_fingerprinting_dataset_generator.rb.txt].
The aim of acoustic fingerprinting is to generate a small representation of an audio signal that can be used to identify or recognize similar audio samples in a large audio set. A robust fingerprint generates similar fingerprints for perceptually similar audio signals. A piece of music with a bit of noise added should generate an almost identical fingerprint as the original. The use cases for audio fingerprinting or acoustic fingerprinting are myriad: detection of duplicates, identifying songs, recognizing copyrighted material,…
Using a pitch class histogram as a fingerprint seems like a good idea: it is unique for a song and it is reasonably robust to changes of the underlying audio (length, tempo, pitch, noise). The idea has probably been found a couple of times independently, but there is also a reference to it in the literature, by Tzanetakis, 2003: Pitch Histograms in Audio and Symbolic Music Information Retrieval:
Although mainly designed for genre classification it is possible that features derived from Pitch Histograms might also be applicable to the problem of content-based audio identification or audio fingerprinting (for an example of such a system see (Allamanche et al., 2001)). We are planning to explore this possibility in the future.
Unfortunately they never, as far as I know, did explore this possibility, and I also do not know if anybody else did. I found it worthwhile to implement a fingerprinting scheme on top of the Tarsos software foundation. Most elements are already available in the Tarsos API: a way to detect pitch, construct a pitch class histogram, correlate pitch class histograms with a pitch shift,… I created a GUI application which is presented here. It is, probably, the first open source acoustic / “audio fingerprinting system based on pitch class histograms”:[AudioFingerprinter.jar].
It works using drag and drop and the idea is to find a needle (an audio file) in a hay stack (a large amount of audio files). For every audio file in the haystack and for the needle pitch is detected using an optimized, for speed, Yin implementation. A pitch class histogram is created for each file, the histogram for the needle is compared with each histogram in the hay stack and, hopefully, the needle is found in the hay stack.
Unfortunately I do not have time for rigorous testing (by building a large acoustic fingerprinting data set, or an other decent test bench) but the idea seems to work. With the following modifications, done with audacity effects the needle was still found a hay stack of 836 files :
A 10% speedup
15 and 30 seconds removed form the needle (a song of 4 minutes 12 seconds)
White noise added
Reversed the audio (This is, I believe, a rather unique property of this fingerprinting technique)
GSM reencoded
The following modifications failed to identify the correct song:
A one semitone pitch shift
A two semitone pitch shift
60 seconds removed from the needle
The original was also found. No failure analysis was done. The hay stack consists of about 100 hours of western pop, the needle is also a western pop song. If somebody wants to pick up this work or has an acoustic fingerprinting data set or drop me a line at
The DSP library of Tarsos, aptly named TarsosDSP, now contains an implementation of the Goertzel Algorithm. It is implemented using pure Java.
The Goertzel algorithm can be used to detect if one or more predefined frequencies are present in a signal and it does this very efficiently. One of the classic applications of the Goertzel algorithm is decoding the tones generated on by touch tone telephones. These use DTMF (Dual tone multi frequency)-signaling.
To make the algorithm visually appealing a Java Swing interface has been created(visible right). You can try this application by running the “Goertzel DTMF Jar-file”:[GoertzelDTMF.jar]. The souce code is included in the jar and is avaliable as a separate “zip file”:[GoertzelDTMF_src.zip]. The TarsosDSP github page also contains the source for the Goertzel algorithm Java implementation.
The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the Late Breaking and Demo Session) or read the paper: “Peachnote Piano: Making MIDI instruments social and smart using Arduino, Android and Node.js”:[PeachNote_Piano_ISMIR_Demo.pdf]. What follows here is the introduction of the extended abstract:
Playing music instruments can bring a lot of joy and satisfaction, but not all apsects of music practice are always enjoyable. In this contribution we are addressing two such sometimes unwelcome aspects: the solitude of practicing and the "dumbness" of instruments.
The process of practicing and mastering of music instruments often takes place behind closed doors. A student of piano spends most of her time alone with the piano. Sounds of her playing get lost, and she can't always get feedback from friends, teachers, or, most importantly, random Internet users. Analysing her practicing sessions is also not easy. The technical possibility to record herself and put the recordings online is there, but the needed effort is relatively high, and so one does it only occasionally, if at all.
Instruments themselves usually do not exhibit any signs of intelligence. They are practically mechanic devices, even when implemented digitally. Usually they react only to direct actions of a player, and the player is solely responsible for the music coming out of the insturment and its quality. There is no middle ground between passive listening to music recordings and active music making for someone who is alone with an instrument.
We have built a prototype of a system that strives to offer a practical solution to the above problems for digital pianos. From ground up, we have built a system which is capable of transmitting MIDI data from a MIDI instrument to a web service and back, exposing it in real-time to the world and optionally enriching it.
A previous post about PeachNote Piano has more technical details together with a video showing the core functionality (quasi-instantaneous USB-BlueTooth-MIDI communication). Some photos can be found below.
While working on a Latex document with several collaborators some problems arise:
Who has the latest version of the TeX-files?
Which LaTeX distributions are in use (MiKTeX, LiveTex,…)
Are all LaTeX packages correctly installed on each computer?
Why is the bibliography, generated with BiBTeX, not included or incomplete?
How does the final PDF look like when it is build by one of the collaborators, with a different LaTeX distribution?
Especially installing and maintaining LaTeX distributions on different platforms (Mac OS X, Linux, Windows) in combination with a lot of LaTeX packages can be challenging. This blog post presents a way to deal with these problems.
Solution
The solution proposed here uses a build-server. The server is responsible for compiling the LaTeX source files and creating a PDF-file when the source files are modified. The source files should be available on the server should be in sync with the latest versions of the collaborators. Also the new PDF-file should be distributed. The syncing and distribution of files is done using a Dropbox install. Each author installs a Dropbox share (available on all platforms) which is also installed on the server. When an author modifies a file, this change is propagated to the server, which, in turn, builds a PDF and sends the resulting file back. This has the following advantages:
Everyone always has the latest version of files;
Only one LaTeX install needs to be maintained (on the server);
The PDF is the same for each collaborator;
You can modify files on every platform with Dropbox support (Linux, Mac OS X, Windows) and even smartphones;
Compiling a large LaTeX file can be computationally intensive, a good task for a potentially beefy server.
Implementation
The implementation of this is done with a couple of bash-scripts running on Ubuntu Linux. LaTeX compilation is handeled by the LiveTeX distribution. The first script compile.bash handles compilation in multiple stages: the cross referencing and BiBTeX bibliography need a couple of runs to get everything right.
```ruby\
#!/bin/bash\
#first iteration: generate aux file\
pdflatex -interaction=nonstopmode —src-specials article.tex\
#run bibtex on the aux file\
bibtex article.aux\
#second iteration: include bibliography\
pdflatex -interaction=nonstopmode —src-specials article.tex\
#third iteration: fix references\
pdflatex -interaction=nonstopmode —src-specials article.tex\
#remove unused files\
rm article.aux article.bbl article.blg article.out\
```
The second script watcher.bash is more interesting. It watches the Dropbox directory for changes (only in .tex-files) using the efficient inotify library. If a modification is detected the compile script (above) is executed.
```ruby\
#!/bin/bash\
directory=/home/user/Dropbox/article/\
#recursivly watch te directory\
while inotifywait -r $directory; do\
#find all files changed the last minute that match tex\
#if there are matches then do something…\
if find $directory -mmin –1 | grep tex; then\
#tex files changed => recompile\
echo “Tex file changed… compiling”\
/bin/bash $directory/compile.bash\
#sleep a minute to prevent recompilation loop\
sleep 60\
fi\
done\
```
To summarize: a user-friendly way of collaboration on LaTeX documents was presented. Some server side configuration needs to be done but the clients only need Dropbox and a simple text editor and can start working togheter.
The Pidato experiment demonstrates a rather straightforward method to handle vibrato on a digital piano. It solves the age-old problem on what to do with the enigmatic “vibrato” instructions on some piano solo scores of Franz Liszt. The figure on the right is an exerpt of sonetto 104 del Petrarca.
Since there is no way to perform vibrato on an analogue piano there are all kinds of different interpretations. Interpretations of the ‘vibrato’ instruction include: vibrating the pedal, vibrating the key, simply ignoring it, a vibrato like wiggling with a psychological sounding effect, … A pianist specialized in 19th century music, explains his embodied use of vibrato in a youtube video: Brian Ganz on piano vibrato. Those solutions all seem a bit halfhearted, so I created an alternative approach which resulted in the Pidato experiment.
Pidato is a portmanteau of piano and vibrato, the d, a and o hint to the use of an Arduino. Pidato is also Indonesian for speech, expression. To get a feel of what it actually does I created the video below. Please note that this is a technical demonstration, not an artistic performance… in any way.
Vid: The Pidato experiment - Vibrato on a Digital Piano using an Arduino.
The way it works is by translating movement (accelerometer data) to MIDI messages. The hardware consists of an Arduino, MIDI-ports and a three axis accelerometer. The MIDI-ports are provided by this MIDI IN & OUT Arduino shield. The accelerometer is a MMA7260Q from Sparkfun. Attaching the MMA7260Q and the arduino is done by following the instructions here. One change was made: by attaching the 3.3V output to AREF and executing analogReference(EXTERNAL); fluctuations in power supply cease to have an influence on accelerometer data readings. It is represented by the purple wire in the diagram below.
The software should know when a vibrato like movement is made and how to translate such movement to MIDI messages. The software therefore contains a periodicity estimator and frequency detector to detect how periodic a movement is and how fast the movement is repeated. This was done with the YIN algorithm (more commonly used in audio signal analysis). A periodicity threshold was determined experimentally so the system does not yield false positives when playing the piano in the usual way. Another interesting bit of code is the interrupt setup that samples the accelerometer at a fixed sample rate and sends MIDI messages, also at a fixed rate.
MIDI messaging is done over a serial connection. From the Arduino sending a MIDI message is as simple as calling Serial.print with the correct data. For the task at hand (sending vibrato) Pitch Bend messages were used. The standard Arduino UNO firmware is replaced with Arduino MIDI firmware. This makes the Arduino appear as a standard MIDI device when connected to a computer, which makes interfacing with it practical.
The YIN algorithm is encapsulated in a reusable Arduino library and can be used to detect periodicity and frequency for any signal. This guy used his implementation to create a chromatic tuner. The source code for both the Yin Arduino library and Pidato experiment can be found on github or “here (zip)”:[Pidato.src.zip].
The Pidato experiment was done with the help the friendly hackers at Hackerspace Ghent.
Tarsos can be used to render MIDI files to audio (WAV) files using arbitrary tone scales. This functionallity can be used to (automatically) verify tone scale extraction from audio files. Since I could not find a dataset with audio and corresponding tone scales creating one using MIDI seemed a good idea.
MIDI files can be found in spades (for example on piano-midi.de or kunstderfuge.com), tone scales on the other hand are harder to find. Luckily there is one massive source, the Scala Tone Scale Archive: A large collection of over 3700 tone scales.
Using Scala tone scale files and a midi files a Tone Scale - Audio dataset can be generated. The quality of the audio depends on the (software) synthesizer and the SoundFont used. Tarsos currently uses the Gervill synthesizer. Gervill is a pure Java software synthesizer with support for 24bit SoundFonts and the MIDI tuning standard.\
How To Render MIDI Using Arbitrary Tone Scales with Tarsos
A recent version of the JRE (Java Runtime Environment) needs to be installed on your system if you want to use Tarsos. Tarsos itself can be downloaded in the form of the “MIDI and Scala to Wav - JAR Package”:[MidiToWav.jar].
To test the program you can use “a MIDI file”:[MIDI_file.mid] and “a Scala file”:[persian.scl.txt] and drag and drop those on the graphical interface.
The result should sound like this:
To summarize: by rendering audio with MIDI and Scala tone scale files a dataset with tone scale - audio information can be generated and tone scale extraction algorithms can be tested on the fly.
This is about PeachNote Piano, a project only tangentially related to Tarsos. PeachNote Piano aims to capture as many piano practice sessions as possible and offer useful services using this data. The system does this by capturing and redirecting MIDI events on a Bluetooth enabled smartphone. It is done together with Vladimir Viro and builds on the existing PeachNote infrastructure.
The schema - right - shows the components of the PeachNote Piano system. At the bottom you have a MIDI keyboard connected to the MIDI-Bluetooth-bridge. A smartphone (middle left) receives these MIDI events via Bluetooth and controls the communication to the server (top left). An alternative path goes through a standard computer (top right).
The Arduino based Bluetooth to MIDI bridge is an improvement on the work by Peter Brinkmann. The video below shows communication between USB-MIDI, Bluetooth MIDI and MIDI IN/OUT ports.
As an example application of the PeachNote Piano system we implemented a “Continue a Melody” service which works as follows: a user plays something on a keyboard, maybe just a few notes, and pauses for a few seconds. In the meantime, the server searches through a large database of MIDI piano recordings, finds the longest fuzzy match for the user’s most recent input, and, after a short silence on the users part, starts streaming the continuation of the best matched performance from the database to the user. This mechanism, in fact, is way of browsing a music collection. Users may play a known leitmotiv or just improvise something, and the system continues playing a high quality recording, “replying” to the musical proposition of the user.
More technical details
The melody matching is done on the server, which is implemented in Javascript in the Node.js framework. The whole dataset (about 350 hours of piano recordings) resides in memory in two representations: as a sequence of pitches, and as a sequence of “densities” at the corresponding places of the pitch sequence dataset. This second array is used to store the rough tempo information (number of notes per second) absent in the pitch sequence data.\
By combining the two search criteria we can achieve reasonable approximation of the tempo-aware search without its computational complexity.
The implementation of the hardware is based on the open-source electronic prototyping platform Arduino. Optocoupled MIDI ports (IN/OUT) and the BlueSMiRF Bluetooth module were attached to the main board, as can be seen in the middle left block of the schema. The BlueTooth module is configured to use the Serial Port Profile (SPP) which emulates RS-232. The software on the Arduino manages bi-directional, low latency message passing between three serial ports: USB (through an FTDI chip), BlueTooth and the hardware MIDI-IN and OUT port.
The standard Arduino firmware has been replaced with firmware that implements the “Universal Serial Bus Device Class Definition for MIDI Devices”: when attached to a computer via USB, the Arduino shows up as a standard MIDI device, which makes it compatible with all available MIDI software. The software client currently works on the Android smartphone platform. It is represented using the middle right block in the schema. The client can send and receive MIDI events over its Bluetooth port. Pairing, connecting and communicating with the device is done using the Amarino software library. The client communicates with the Peachnote Piano server using TCP sockets implemented on the Dalvik Java runtime.
This article describes how to do makam recognition with a script that uses the Tarsos API.
The task we want to do is to find the tone scales most similar to the one used in recorded music. To complete this task you need a small set of theoretical scales and a large set of music, each brought in one of the scales. To make it more concrete, an example of Turkish classical music is used.
In an article by Bozkurt pitch histograms are used for - amongst other tasks - makam recognition. A maqam defines rules for a composition or performance of classical Turkish music. It specifies melodic shapes and pitch intervals, the scale. The task is to identify which of nine makams is used in a specific song. A simplified, generalized implementation of this task is shown here. In our implementation there is no tonic detection step. Also here we use only theoretical descriptions of the tone scales as a template and do not construct a template using the audio itself, as is done by Bozkurt. Ioannidis Leonidas wrote an interesting master thesis about makam recognition. Since no knowledge of the music itself is used the approach is generally applicable.
The following is an implementation in Scala a general purpose programming language that is interoperable with Jave . The first step is to write the Scala header. This is just some boilerplate code to be able to run the script from the command line - it assumes a UNIX-like environment and tarsos.jar in the same directory:
The second step constructs the templates the capability of Tarsos to create\
theoretical tone scale templates using Gaussian kernels is used, line 8. See the attached images for some examples.
```ruby\
val makams = List( “hicaz”,”huseyni”,”huzzam”,”kurdili_hicazar”,\
“nihavend”,”rast”,”saba”,”segah”,”ussak”)
var theoreticKDEs = Map[java.lang.String,KernelDensityEstimate]()\
makams.foreach{ makam =>\
val scalaFile = makam + “.scl”\
val scalaObject = new ScalaFile(scalaFile);\
val kde = HistogramFactory.createPichClassKDE(scalaObject,35)\
kde.normalize\
theoreticKDEs = theoreticKDEs + (makam -> kde)\
}\
```
The third and last step is matching. First a list of audio\
files is created by recursively iterating a directory and matching each file to\
a regular expression. Next, starting from line 4, each audio file is processed.\
The internal implementation of the YIN pitch detection\
algorithm is used on the audio file and a pitch class histogram is created\
(line 6,7). On line 10 normalization of the histogram is done, to\
make the correlation calculation meaningful. Line 11 until 15 compare the\
created histogram from the audio file with the templates calculated beforehand.\
The results are stored, ordered and eventually printed on line 19.
```ruby\
val directory = “/home/joren/turkish_makams/”\
val audio_pattern = “.*.(mp3|wav|ogg|flac)”\
val audioFiles = FileUtils.glob(directory,audio_pattern,true).toList
audioFiles.foreach{ file =>\
val audioFile = new AudioFile(file)\
val detectorYin = PitchDetectionMode.TARSOS_YIN.getPitchDetector(audioFile)\
val annotations = detectorYin.executePitchDetection()\
val actualKDE = HistogramFactory.createPichClassKDE(annotations,15);\
actualKDE.normalize\
var resultList = List[Tuple2[java.lang.String,Double]]()\
for ((name, theoreticKDE) <- theoreticKDEs){\
val shift = actualKDE.shiftForOptimalCorrelation(theoreticKDE)\
val currentCorrelation = actualKDE.correlation(theoreticKDE,shift)\
resultList = (name -> currentCorrelation) :: resultList\
}\
//order by correlation\
resultList = resultList.sortBy{_._2}.reverse\
Console.println(file + “ is brought in tone scale “ + resultList(0)._1)\
}\
```
A complete version of this script can is available: “Tone scale matching script”:[guess_makam.scala] Results of the script when ran on Bozkurt’s dataset can be seen in the attached spreadsheet (“openoffice format”:[makam_recognition_results.ods] or “excel format”:[makam_recognition_results.xls]).
Theoretical template
Other theoretical template
Actual Hicaz song overlayed with a theoretical template
A paper about Tarsos was submitted for review at the 12th International Society for Music Information Retrieval Conference which will be held in Miami. The paper “Tarsos - a Platform to Explore Pitch Scales in Non-Western and Western Music”:[tarsos_ismir_2011.pdf] was reviewed and accepted, it will be published in this year’s proceedings of the ISMIR conference. It can be read below as well.
An oral presentation about Tarsos is going to take place Tuesday, the 25 of October during the afternoon, as can be seen on the ISMIR preliminary program schedule.
If you want to cite our work, please use the following data:
```ruby\
\@inproceedings{six2011tarsos,\
author = {Joren Six and Olmo Cornelis},\
title = {Tarsos - a Platform to Explore Pitch Scales\
in Non-Western and Western Music},\
booktitle = {Proceedings of the 12th International\
Society for Music Information Retrieval Conference,\
ISMIR 2011},\
year = {2011},\
publisher = {International Society for Music Information Retrieval}\
}\
```
Tarsos, a software package to analyse pitch organization in music, contains a new output modality. Now it is possible to export resynthesized pitch annotations, detected by a pitch detection algorithm and compare those with the original sound. This can be interesting to see which errors a pitch detection algorithm makes.
Below you can listen to an example of synthesized pitch detection results compared with the original flute piece. The file starts with only the original flute sound (on the right channel) and gradually changes so only the synthesized annotations (on the left channel) can be heard.
This article describes how to make sun-java6 play nice with the PulseAudio sound sytem on Ubuntu with an x64 processor architecture. With some changes the method should also work with other operating systems and other platforms.
The default way sun-java6 operates with respect to sound on Ubuntu is, well unrespectfull. When playing audio it claims an audio device, which then can not be used any more by other applications trying to access the same device. This is far from ideal. Also changing audio interfaces (by e.g. plugging in a USB audio interface) goes wrong most of the time.
These problems are addressed by PulseAudio and there is a way to make sun-java6 aware of PulseAudio on Ubuntu. The OpenJDK does this automatically but it has some other, unrelated, issues. If you want to use PulseAudio with java6 on Ubuntu x64 you need copy “pulse-java.jar”:[pulse-java.jar] and platform dependent “libpulse-java.so”:[libpulse-java.so] file to correct JVM directories. To make it easy you can execute these commands:
From this moment on the “PulseAudio Mixer” is available for Java applications. Sharing, switching and assigning audio devices to Java programs is as a result smooth. To use the PulseAudio Mixer by default you need to change sound.properties which can be found at /usr/lib/jvm/java-6-sun/jre/lib/sound.properties. Details can be found here.
Vorige zaterdag werd Apps For Ghent georganiseerd: een activiteit om het belang van open data te onderstrepen in navolging van onder meer Apps For Amsterdam en New York City Big App. Tijdens de voormiddag kwamen er verschillende organisaties hun open gestelde data voorstellen de namiddag werd gereserveerd voor een wedstrijd. Het doel van de wedstrijd was om in enkele uren een concept uit te werken en meteen voor te stellen. Het uitgewerkte prototype moest gedeeltelijk functioneren en gebruik maken van (Gentse) open data.
Luk Verhelst en ikzelf hebben er TwinSeats voorgesteld.
TwinSeats is een website / online initiatief om nieuwe mensen te leren kennen. Met hen deel je dezelfde culturele interesse en ga je vervolgens samen naar deze of gene voorstelling. Door events centraal te stellen kan TwinSeats uitzonderlijke cultuurburen zoeken. Leden vinden die cultuurburen dankzij een gezamenlijke voorliefde voor een artiest of attractie of eender welke bezigheid in de vrijetijdssfeer.
Het prototype is ondertussen terug te vinden op TwinSeats.be. Let wel dit is in enkele uren in elkaar geflanst en is verre van ‘af’, het achterliggende concept is belangrijker.
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method.
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in JAVA.
To make some of the possibilities clear I coded some examples.
“TarsosDSP UtterAsterisk”:[UtterAsterisk.jar] a game that shows real-time pitch detection with YIN.
“TarsosDSP Sound Detector”:[SoundDetector.jar] is simply to show how to react when (loud) sound is available.
“TarsosDSP Percussion Detector”:[PercussionDetector.jar] is capable of detecting percussion onsets using the method described here. It plays a sound from freesound.org when percussion is detected.
Saturday the 25th of March TarsosDSP was presented at Newline, a small conference organized by whitespace. Here you can download “the slides I used to present TarsosDSP”:[tarsosDSP_presentation.pdf], I also created “an introductory text on sound and Java”:[sound_and_java.pdf].
With this post I would like to draw attention to the fact that remote port forwarding with OpenSSH 4.7 on Ubuntu 8.04.1 does not work as expected.
If you follow the instructions of a SSH remote port forwarding tutorial everything goes well until you want to allow everyone to access the forwarded port (not just localhost). The problem arises when binding the forwarded port to an interface. Even with GatewayPorts yes present in /etc/ssh/sshd_config the following command shows that it went wrong:
```ruby\
user@local$ssh -R 2222:localhost:22 user@remote\
user@remote$sudo netstat -lntp #on the remote server\
Active Internet connections (only servers)\
Proto Recv-Q Send-Q Local Address Foreign Address State\
tcp6 0 0 ::1:2222 :::* LISTEN\
```
It listens only via IPv6 and only on localhost an not on every interface (as per request by defining GatewayPorts yes). The netstat command should yield this output:
```ruby\
user@local$ssh -R 2222:localhost:22 user@remote\
user@remote$sudo netstat -lntp #on the remote server\
Active Internet connections (only servers)\
Proto Recv-Q Send-Q Local Address Foreign Address State\
tcp 0 0 0.0.0.0:2222 0.0.0.0:* LISTEN\
```
I do not really know here it goes wrong but there is an easy workaround. By defining both
in /etc/ssh/sshd_config remote port forwarding works fine but you lose IPv6 connectivity (this due to the AddressFamily setting). Another solution is to use more up to date software: the bug is not present in Ubuntu 10.04 with OpenSSH 5.3 (I don’t know if it is an Ubuntu or OpenSSH bug, or even a configuration issue.
I have been struggling with this issue for a couple of hours and, with this blog post, I hope I can prevent someone else from doing the same.
ssh-copy-id is a practical bash script, installed by default on Ubuntu. The script is used to distribute public keys. The following oneliner makes it available on Mac OS X:
```ruby\
sudo bash < <( curl —silent http://0110.be[install-ssh-copy-id.bash] )\
```\
This oneliner does three things:
It copies ssh-copy-id from this website to /bin/ssh-copy-id.
It makes sure that ssh-copy-id is executable, using chmod.
There is no three
The install procedure needs superuser rights because it writes in the /bin folder. Executing scripts from untrusted sources with superuser rights is actually really, really, extremely dangerous. But in this case it is rather innocent.
The ssh-copy-id script is the one provided with Ubuntu and Debian, I assume it is GPL’ed. I have not modified it for Mac OS X but it seems to behave as expected. I have only tested the install script and behavior on 10.6.5, YMMV (Your Mileage May Vary).
There is more to Tarsos then meets te eye. The graphical user interface only exposes some functionality; the API (Application Programmer Interface) exposes all of Tarsos’ capabilities.
Tarsos is programmed in Java so the API is accessible trough Java and other programming languages targeting the JVM (Java Virtual Machine) like JRuby, Scala and Groovy. The following examples use the Groovy programming language because I find it the most aesthetically pleasing with regards to interoperability and it gets the job done without getting in your way.
To run the examples a copy of the Tarsos JAR-file needs to be added to the Classpath and the Groovy runtime must be installed correctly. I’ll leave this as an exercise for the reader: godspeed to you, brave soul. Quick protip: placing a copy of the jar in the extensions directory seems to work best, e.g. see important java directories on mac OS X.
The first example extracts pitch class histograms from a bunch of files and saves them as EPS (Encapsulated PostScript)-files. It iterates a directory recursively and handles each file that matches a given regular expression. In this example the regular expression matches all WAV-files. Batch processing is one of those things scripting is ideal for, doing the same thing with the user interface would be tedious or even mind-numbingly boring, not groovy at all indeed.
FileUtils.glob(dir,”.*.wav”,true).each { file ->\
audioFile = new AudioFile(file)\
pitchDetector = PitchDetectionMode.TARSOS_YIN.getPitchDetector(audioFile)\
pitchDetector.executePitchDetection()\
//get some annotations\
annotations = pitchDetector.getAnnotations()\
//create an ambitus and tone scale histogram\
ambitusHistogram = Annotation.ambitusHistogram(annotations)\
toneScaleHisto = ambitusHistogram.toneScaleHistogram()\
//plot a smoothed version of the histogram\
p = new SimplePlot()\
p.addData 0, toneScaleHisto.gaussianSmooth(0.2)\
p.save FileUtils.basename( file) + “.eps”\
}\
```
The second example uses functionality that is currently only available trough the API. It takes a MIDI-file and synthesizes it to a wave file using an arbitrary scale. In this case 10-TET. The heavy-work is done by the Gervill synthesizer. The resulting file is available for download, micro—macro?—tonal Bach is great: “BWV 1013 in 10-TET”:[BWV_1013_10-TET.mp3]. The result of “an analysis with Tarsos on the synthesized audio”:[120.png] clearly shows an interval of 120 cents with some deviations.
midiFile = new File(“BWV_1013.mid”)\
outFile = new File(“out.wav”)
tuning = [0,120,240,360,480,600,720,840,960,1080] as double []
MidiToWavRenderer renderer\
renderer = new MidiToWavRenderer()\
renderer.setTuning(tuning)\
renderer.createWavFile(midiFile, outFile)\
```
An extended version of this second example script could be used to generate a dataset with audio and corresponding tone scale information on the fly. The dataset could then be used as a baseline.
The API is not yet well documented and is still in flux or more correctly: superflux. Note to self: I will provide documentation and a number of useful examples when the dust settles down. I’m not even sure if I will stick with Groovy. Scala has a nice Lispy feel to it and seems more developed. Groovy has a less steep learning curve, especially if you have some experience with Ruby. JRuby is also nice but the interoperability with legacy Java looks like an ugly hack.
This post describes a crucial aspect of how to connect an android phone, the LG GT540 Optimus, to an Ubunu Linux computer. The method is probably similar on different UNIX like platforms with different phones.
To recognize the phone when it is connected via usb you need to create an UDEV rule. Create the file /etc/udev/rules.d/29.lg545.rules with following contents:
On the phone you need to enable debugging using the settings and (this is rather important) make sure that the “mass storage only” setting is disabled.
Rooting the device makes sure you have superuser rights. Installing the android SDK is well documented.
This post is about the tools I use to keep the source code of Tarsos reasonably clean, consistent and readable. Static code analysis can be of great help if you want to maintain strict coding standards and follow language idioms. Some of the patterns they can detect for you:
Dead code - unused variables, parameters, methods
Suboptimal code - wasteful resource usage
Overcomplicated expressions - unnecessary if statements, for loops that could be while loops
Duplicate code - copied/pasted code is a code smell.
Formatting inconsistencies, e.g. variable modifier order
And even more subtle, but equally important:
Resource management: is a resource handled (closed) correctly on all possible code paths?
Abstraction level: is it needed to expose the concrete type of an object or could an (abstract) supertype or even an interface be used instead?
…
In a previous life I used .NET and the static code analysis tools FxCop & StyleCop. FxCop operates on bytecode (or intermediate language in .NET parlance) level, StyleCop analyses the source code itself. Tarsos uses JAVA so I looked for JAVA alternatives and found a few.
PMD & Checkstyle both operate on source code level.
FindBugs operates on bytecode level.
On freesoftwaremagazine.com there is an article series on JAVA static code analysis software. It covers PMD and FixBugs and integration in Eclipse. It does not cover Checkstyle. Checkstyle is essentialy the same as PMD but it is better integrated in eclipse: it checks code on save and uses the standard ‘Problems’ interface, PMD does not.
Continuous testing is also a really nice thing to have: detecting unexpected behavior while refactoring/programming can prevent unnecessary bug hunts. A video about immediate feedback using continuous testing makes this clear.
Another tip is a more philosophical one: making your code and code revisions publicly available makes you think twice before implementing (and subsequently publishing) a quick and dirty hack. Tarsos is available on github.
The problem: There is a group of people that want access to Hackerspace Ghent but there is only one remote to open the gate.
The solution: Build a system that reacts to a phone call by opening the gate if the number of the caller is whitelisted.
What you need:
A BeagleBoard or some BeagleBoard alternative with a Linux distribution running on it. Any server running a unix like operating system should be usable.
A Huaweii e220 or an alternative GSM that supports (a subset of) AT commands and has a USB port.
A team of hackers that know how to solder something togeher. E.g. The hardware guys of hackerspace Ghent.
A “python script”:[gatekeeper.py] that reacts to calls.
The Hack: First of all try to get caller id working by following the Caller ID with Linux and Huawei e220 tutorial. If this works you can listen to the serial communication using pySerial and react to a call. The following python code shows the wait for call method:
```ruby\
def wait_for_call(self):\
self.data_channel.open()\
call_id_pattern = re.compile(‘.CLIP.”\+([0-9]+)”,.*’)\
while True:\
bytes = self.data_channel.inWaiting()\
buffer = self.data_channel.readline(bytes)\
call_id_match = call_id_pattern.match(buffer)\
if call_id_match:\
number = call_id_match.group(1)\
self.handle_call(number)\
```
The handle_call method … handles the call.
The second thing that is needed is a way to send a signal from the beagle board to the remote. Sending a signal from the beagle board using Linux is really simple. The following bash commands initialize, activate and deactivate a pin.
Today I created a spectrogram application using Tarsos. The application listens to an audio input, computes an FFT and at the same time calculates pitch. The expected pitch is overlaid on the spectrogram. All this happens real-time and is implemented using JAVA.
This is the scenario: you have a Huawei e220, a linux computer and you want to react to a call from a set of predefined numbers. E.g. ordering a pizza when you receive a call from a certain number.
The Huawei e220 supports a subset of the AT commands, which subset is an enterprise secret of te Huawei company. So there is no documentation available for the device I bought, thanks Huawei. Anyhow when you attach the e220 to a Linux machine you should get two serial ports:
```ruby\
/dev/ttyUSB0\
/dev/ttyUSB1\
```
To connect to the devices you can use a serial client. GNU Screen can be used as a serial client like this: screen /dev/ttyUSB0 115200. The first device, ttyUSB0 is used to control ttyUSB1, so to enable caller ID on te Huawei e220 you need to send this message to ttyUSB0:
```ruby\
AT+CLIP=1\
```
To check for calls you should listen to ttyUSB1. A serial session for ttyUSB1 looks like:
The RING and CLIP messages are the most interesting. The RING signifies an incoming call, the CLIP is the caller ID. The BOOT and RSSI are some kind of ping messages. The following Python script demonstrates a complete session that enables caller ID, waits for a phone call and prints the number of the caller.
```python\
#!/usr/bin/env python\
import serial, re
ser = serial.Serial(\
port=’/dev/ttyUSB1’,\
baudrate=9600,\
parity=serial.PARITY_NONE,\
stopbits=serial.STOPBITS_ONE,\
bytesize=serial.EIGHTBITS\
)
ser.open()
pattern = re.compile(‘.CLIP.”\+([0-9]+)”,.*’)
while 1:\
buffer = ser.read(ser.inWaiting()).strip()\
buffer = buffer.replace(“\n”,””)\
match = pattern.match(buffer)\
if match:\
number = match.group(1)\
print number\
```
To make Tarsos more portable I wrote a pitch tracker in pure JAVA using the YIN algorithm based on the implementation in C of aubio. The implementation also uses some code written by Karl Helgasson and Teun de Lange of the Jazzperiments project.
It can be used to perform real time pitch detection or to analyse files. To use it as a real time pitch detector just start the “JAR-file”:[pitch_detector_yin.jar] by double clicking. To analyse a file execute one of the following. The first results in a list of annotations (text), the second shows the annotations graphically.
The JAVA software program we are developing is called Tarsos and can now be found on GitHub. GitHub is a web-based hosting service for projects that use the Git version control system.
Currently Tarsos is a collection of Java classes to create, compare and process pitch-frequency data using histograms. In it’s current state it is not usable for end-users.
Recently I bought a big shiny red USB-button. It is big, red and shiny. Initially I planned to use it to deploy new versions of websites to a server but I found a much better use: ordering pizza. Graphically the use case translates to something akin to:
If you would like to enhance your life quality leveraging the power of a USB pizza-button: you can! This is what you need:
A PC running Linux. This tutorial is specifically geared towards Debian-based distos. YMMV.
A big, shiny red USB button. Just google “USB panic button” if you want one.
A location where you can order pizzas via a website. I live in Ghent, Belgium and use just-eat.be. Other websites can be supported by modifying a Ruby script.
Technically we need a driver to check when the button was pushed, a way to communicate the fact that the button was pushed and lastly we need to be able to react to the request.
The driver: on the internets I found a driver for the button. Another modification was done to make the driver process a daemon.
The communication: The original Python script executed another script on the local pc. A more flexible approach is possible using sockets. With sockets it is possible to notify any computer on a network.
```ruby\
if PanicButton().pressed():\
# create a TCP socket\
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\
# connect to server on the port\
s.connect((SERVER, SERVER_TCP_PORT))\
# send the order (margherita at restaurant mario)\
s.send(“mario: [margherita_big]\n”)\
```
The reaction: a ruby TCP server waits for message from the driver. When it does it automates a HTTP session on a website. It executes a series of HTTP-GET’s and POST’s. It uses the mechanize library.
Some libraries are needed. For python you need the usb library, the python deamons lib needs to be installed seperatly. Setuptools are needed to install the deamons package.
Ruby needs rubygems to install the needed mechanize and daemons library. Mechanize needs the libxslt-dev package. You also need the build-essential package to build mechanize.
This blog post is about how to use the Touchatag RFID reader hardware on Ubuntu Linux without using the Touchatag web service.
An RFID reader with tags can used to fire events. With a bit of scripting the events can be handled to do practically any task.
Normally a Touchatag reader is used together with the Touchatag web service but for some RFID applications the web service is just not practical. E.g. for embedded Linux devices without an Internet connection. In this tutorial I wil document how I got the Touchatag hardware working under Ubuntu Linux.
To follow this tutorial you will need:
Touchatag hardware: the USB reader and some tags
A Ubuntu Linux computer (I tested 9.10 Karmic Koala and 8.04 )
SVN to download source code from a repository
The touchatag USB reader works at 13.56MHz (High Frequency RFID) and has a readout distance of about 4 cm (1.5 inch) when used with the touchatag RFID tags. Internally it uses an ACS ACR122U reader with a SAM card. A Linux driver is readily available so when you plug it in lsusb you should get something like this:
```ruby\
lsusb
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub\
Bus 005 Device 004: ID 072e:90dd Advanced Card Systems, Ltd\
```
lsusb recognizes the device incorrectly but that’s not a problem. To read RFID-tags and respond to events additional software is needed: tagEventor is a software library that does just that. It can be downloaded using an svn command:
To compile tagEventor a couple of other software packages or header files should be available on your system. Te tagEventor software dependencies are described on the tagEventor wiki. On Ubuntu (and possibly other Debian based distro’s the installation is simple:
```ruby\
sudo aptitude install build-essential libpcsclite-dev build-essential pcscd libccid\
#if you need gnome support\
#sudo aptitude install libgtk2.0-dev\
```
Now the tricky part. Two header files of the pcsclite package need to be modified (update: this bug is fixed see here). tagEventor builds and can be installed:
```ruby\
cd tageventor\
make\
…\
tagEventor BUILT (./bin/Release/tagEventor)
sudo ./install.sh\
…\
```
When tagEventor is correctly installed the only thing left is … to build your application. When an event is fired tagEventor executes the /etc/tageventor/generic script with three parameters (see below). Using some kind of IPC (Inter Process Communication) an application can react to events. A simple and flexible way to propagate events (inter-processes, over a network, platform and programming language independent) uses sockets. The code below is the /etc/tageventor/generic script (make sure it is executable), it communicates with the server: the second script. To run the server execute ruby /name/of/server.rb
```ruby\
#!/usr/bin/ruby
$1 = SAM (unique ID of the SAM chip in the smart card reader if exists, “NoSAM” otherwise
$2 = UID (unique ID of the tag, as later we may use wildcard naming)
$3 = Event Type (IN for new tag placed on reader, OUT for tag removed from reader)
The tagEventor software is made by the Autelic Association a Non-Profit association dedicated to making technology easier to use for all. I would like to thank Andrew Mackenzie, the founder and president of the association for creating the software and the support.
Ik heb in opdracht van scholengroep Sperregem een website gemaakt die het vinden van kandidaten voor korte vervangingen vlotter doet verlopen. Mensen met interesse voor vacatures in het onderwijs in West-Vlaanderen kunnen zich er op inschrijven.
De website heeft enkele voordelen voor verschillende scholen in de scholengroep:
Het zoeken van kandidaten is erg eenvoudig: na het invoeren van een vacature komt er een lijst met kandidaten met een geschikt profiel die tijdens de vacature beschikbaar zijn.
Er kunnen e-mail of SMS-berichten verstuurd worden om kandidaten op de hoogte te brengen van een vacature.
Profielen van kandidaten zijn altijd up-to-date: de kandidaten zijn er zelf verantwoordelijk voor en kandidaten lange tijd niets van zich laten horen worden automatisch op non-actief gezet.
De historiek van kandidaten wordt automatisch bijgehouden en kan opgezocht worden.
Ook voor de aspirant onderwijzers is de website handig:
De vacatures zijn publiek zichtbaar, kandidaten kunnen dus actief solliciteren.
Ze kunnen zelf hun profiel beheren en bijvoorbeeld een vernieuwde versie van hun C.V. uploaden.
Voor elke kandidaat is een gepersonaliseerde lijst met vacatures beschikbaar (ook via RSS), afgestemd op hun profiel.
Daarnaast is het ook voor de personeelsdienst een handige tool: die kan nu een beter overzicht bewaren over de vacatures en de invulling ervan in de verschillende scholen.
Vandaag is de vernieuwde vooruitwebsite gelanceerd:
We bieden je nog meer video’s, foto’s, audiotracks en tekstmateriaal en hebben ook jouw persoonlijke voordelen uitgebreid. Wanneer je lid wordt van www.vooruit.be, kan je nog steeds je kalender aanvullen, vrienden maken en reacties posten, maar daarnaast krijg je ook aanbevelingen op maat, kan je voorstellingen tippen en kan je berichten sturen naar vrienden *.
Waarschijnlijk heb je het al gemerkt: deze site gaat nu heel wat sneller. Dit is te danken aan een verhuis. 0110.be wordt nu gehost op een VPS (Virtual Private Server).
De virtuele server heeft Ubuntu 8.04 LTS Server als besturingssysteem en draait op een Xen hypervisor. De fysieke server zelf bevat een achttal Intel® Xeon® E5440 @ 2.83GHz CPU’s.
De server staat in Amsterdam en is rechtstreeks verbonden met het grootste internetknooppunt ter wereld: AMS-IX.
Uit de lijst van postcodes van alle Belgische steden heb ik een SQL-bestand samengesteld. De gegevens bevatten de postcode zelf, de naam van de stad, de naam van de stad in hoofdletters en een veld “structure” waaruit de gemeente-deelgemeente relatie gehaald kan worden als er op gesorteerd wordt. Dit zijn bijvoorbeeld de deelgemeentes van Chimay.
\
\
Het sorteren kan in PostgreSQL met deze SQL instructie: order by translate(structure, ' ', 'z'). Het SQL-script zelf is een lijst van INSERT INTO SQL-Statements.
insert into cities(zipcode,name,up,structure) VALUES ('1790','Affligem','AFFLIGEM','1790 AFFLIGEM');
insert into cities(zipcode,name,up,structure) VALUES ('9051','Afsnee','AFSNEE','9051 Afsnee');
insert into cities(zipcode,name,up,structure) VALUES ('5544','Agimont','AGIMONT','5544 Agimont');
...
Dit is het “SQL-bestand met een lijst van alle Belgische postcodes en steden”:[steden.sql.txt]. Hopelijk is hier iemand ooit iets mee.
While working at the Vooruit Arts Centre I got the assignment to create a tool to query an Oracle database with ticketing data. There were a few requirements for the Query Tool, in the current version all of these are met:
First of all it had to be easy to execute complex queries, no knowledge of SQL (Structured Query Language) should be required for the end user.
The results of the queries should be exportable to an easy to analyse format. * Editing queries or adding new ones should be doable, by someone knowledgeable with SQL.
The Query Tool should be easy to configure and database independent.
Should work on Windows, Mac OS X and Linux.
By publishing the Query Tool on my website I hope that the fruits of my labour can be enjoyed by a wider audience. To see it in action you can “give it a spin”:[QueryTool.jar]. A recent version, version 6, of the JRE (Java Runtime Environment) is needed.
How Do I Use The Query Tool?
The program supports two ways to query a database:
A number of predefined queries can be selected and executed. Depending on the selected query, zero or more parameters are required. E.g. the screen shot below depicts a query with one parameter: a product category. When the query is executed all the products in the selected category are fetched.
The tab “SQL” can be used to execute arbitrary SQL-instructions.
The two buttons below are self explanatory. When the button “CVS Export” is hit a CVS file is created in a configured directory.
Depending on the complexity of a query it can take a long time before results are returned. Because the application is multithreaded the user interface remains responsive and the query can be stopped at any time.
The contents of the tab “log” gives you an idea what the application does. When something goes awry while executing a query a message appears in this tab.
The tab “Config” can be used to set configuration parameters. The tab “Help” contains… helpful information.
The list of predefined queries is constructed by iterating over SQL-files in a configured directory. Adding additional queries to the program is easy, just add an extra SQL-file to the directory. An SQL-file should have the following format, otherwise it is ignored:
TITEL
----
DESCRIPTION
----
SQL-INSTRUCTION with zero or more !{PARAMETERS}!
In the screen shot above this query is visible:
Select products in category
----
Select all the products in a category.
----
SELECT * FROM
products WHERE categoryid = !{category}!
To make the queries dynamic the Query Tool supports different kinds of parameters. A parameter has this form: !{type name}!, the name is optional. If there is a name specified it is used as a label in the interface, otherwise type is used. There are three types of parameters:
Parameters that define a type. For each type a corresponding user interface is rendered. E.g. for the type string a text field is rendered. The supported types are:\
#* !{string}!\
#* !{boolean}!\
#* !{double}!\
#* !{date}!\
#* !{integer}!
Parameters for raw SQL. A textfield is rendered, the contents is directly injected in the SQL-query. It has this format: !{sql}!
Parameters for lists. In the example above a list parameter is used. These lists are fetched from the database. E.g. a list of categories. The SQL-instruction and name of the list parameters can be configured.
If you want to use your own database you need to configure the database connection string. The program uses JDBC to connect to the database. It uses metadata provided by the JDBC layer. If your database has a JDBC driver with support for metadata the Query Tool will work correctly. The JDBC driver must be included in the classpath.
For demoing purposes the executable contains a lightweight hsql database. The data in the database is a modified version of the Microsoft Northwind database. The “northwind hsql database”:[northwind.hsql.zip] is created with this “SQL-script”:[northwind.script.txt].
Downloads
“Java Source code en documentation”:[QueryTool.source.zip]: contains an eclipse project.
“Executable”:[QueryTool.jar]: Contains only the executable.
Na het bekijken van het onderstaande filmpje van een zwerm spreeuwen vroeg ik mij af of die bewegingen zich aan een bepaald algoritme houden en of ik een programma kon schrijven die dit gedrag simuleerde. Na wat onderzoek bleek dat zowat alle dieren die zich in kudde voortbewegen dit doen volgens gelijkaardige, relatief eenvoudige processen.
Er zijn drie basisregels waaraan onder andere scholen vissen, zwermen vogels en kuddes gnoes zich houden:
Voorkom botsingen met de dichtste buren door de andere kant op te gaan.
Beweeg ongeveer in de zelfde richting en even snel als het gemiddelde van de buren.
Beweeg naar het midden van de groep.
De paper Flocks, Herds, and Schools:\
A Distributed Behavioral Model - 1987 van Craig W. Reynolds was de eerste die deze regels formeel omschreef. Aan de hand van die documentatie en een praktische omschrijving kon ik aan een implementatie beginnen. De “boids implementatie in Python (src)”:[boids.zip] gebruikt pygame om een groep creaturen voor te stellen met een gekleurd vierkantje. De creaturen bewegen zich volgens de drie bovenstaande regels. Daarnaast proberen ze om binnen het zichtbare kader te blijven en begeven ze zich naar het midden van het kader. Om de boel wat interactiever te maken wordt de muisaanwijzer gezien als een gevaarlijk roofdier die niets liever lust dan vierkantjes. De vierkantjes proberen de roof-muis dus te ontlopen. De zesde en laatste regel legt een maximum snelheid op, zodat de bewegingen realistisch blijven.
De huidige implementatie is O (n²), terwijl het O (nk) zou moeten zijn, met k de grootte van de burenlijst. Een vloeiende simulatie van een zwerm van duizenden is dus momenteel niet mogelijk. De berekeningen voor een extra dimensie zijn erg eenvoudig te implementeren, helaas is de visualisatie van de resultaten dat niet. Ik heb geprobeerd om met de OpenGL bindingen voor Python te werken maar veel resultaat heeft dat niet opgeleverd. Dit is de “3D-versie”:[3D.zip], maar dan met een 2D visualsatie.
Ik heb er voor het gemak ook een “uitvoerbaar bestand voor Windows”:[boids_binary.zip] van gemaakt.
Ik heb een B-Tree en een Red-Black tree geschreven in Ruby. Om die datastructuren te testen heb ik een programma geschreven dat alle woorden uit een grote tekst inleest in een b-tree met het woord als sleutel en de frequentie als waarde en daarna een red black tree gebruikt als priority queue met als sleutel de frequentie en als waarde het woord. Op die manier kunnen de meest voorkomende woorden bepaald worden. De broncode is “hier neer te laden”:[trees.zip].
Het programma is een ideale test voor Ruby VM’s: het is redelijk intensief en gevarieerd. IronRuby, JRuby, Ruby 1.8 en Ruby 1.9 werden getest op een Intel Core 2 Duo E6660 en dit zijn de resultaten:
De verschillen zijn dus erg groot. Zowel in geheugengebruik als in duur. Ruby 1.8 is blijkbaar erg traag maar gebruikt relatief weinig geheugen. JRuby is in deze test drie keer sneller maar gebruikt meer geheugen. Ook IronRuby is sneller dan de standaard Ruby VM maar gebruikt net niet het dubbele aan geheugen. Hierbij moet wel verteld worden dat IronRuby een alfa build is, de resultaten kunnen dus nog veel veranderen.
Ruby 1.9 werd later getest op Mac OS X, met dezelfde pc. De nieuwe Ruby lijkt toch enkele beloften in te lossen. Ter vergelijking werd de voor Mac OS X geoptimaliseerde Ruby 1.8 VM die standaard met het besturingssysteem meegeleverd wordt ook nog getest.
I have modified a bash-script to backup PostgreSQL databases, this is the original script. The “modified version”:[database_backup_script.txt] can be used to backup databases on a remote or local database server. Also this script does not need a trust relationship but uses a login and password. To get started you need to:
Modify the directory and database variables to suit your needs.
Add an entry to crontab to perform the backups nightly or whenever you wish.
Have fun.
The script empties ~/.pgpass\ and\ writes\ login\ info\ for\ the\ system\ databases.\ Then\ it\ logs\ in\ and\ fetches\ an\ up-to-date\ list\ of\ databases.\ For\ every\ database\ an\ entry\ is\ made\ in~/.pgpass and every database is backed up. The results are logged to $logfile.
Gisteren werd de laatste hand gelegd aan de thesis over collaborative filtering (CF) waar Greet Dolvelde en ikzelf een jaar mee bezig zijn geweest. Als je hier meer over wilt weten dan kan je het werk “Collaborative Filtering: Onderzoek & implementatie [pdf]”:[collaborative_filtering_onderzoek_en_implementatie.pdf] downloaden. De intiemste details van verschillende CF-benaderingen worden er in geuren en kleuren uit de doeken gedaan. Uit de poster zou moeten duidelijk zijn waarover de thesis eigenlijk gaat:
Maandag heb ik een examen over A.I. Dat gaat onder ander over genetische algoritmen. Om dat principe in werking te zien heb ik een eenvoudig programmatje geschreven in Python: er zitten enkele beestjes (vierkantjes) in een omgeving. Als de beestjes opvallen, witte beestjes zie je goed zitten op een zwarte achtergrond, worden ze verslonden. De beestjes die minder opvallen overleven, muteren of planten zich voort. Overlevenden gaan een generatie langer mee. Bij het muteren verandert de huidskleur willekeurig. Bij voortplanten wordt er een kind gemaakt die het gemiddelde van de huidskleuren van zijn ouders als kleur heeft. Als het meerendeel van de beestjes uiteindelijk een goeie schutkleur aangenomen hebben kan de achtergrond veranderd worden en begint alles van voor af aan.
Dit is de “broncode van het programma”:[generations.py], het werkt enkel met grijswaarden. Er is ook “een uitvoerbaar bestand voor Windows”:[generations.exe]. De .exe is gemaakt met PyInstaller. De achtergrondkleur kan veranderd worden door er op te klikken. Dit is “broncode van de versie met kleur”:[generations-kleur.py].
Om Python wat te leren kennen heb ik een “Text To Speech Recognition” programma geschreven. Het roept SAPI 5.1 aan om een tekst voor te laten lezen door Microsoft Sam. Het voorgelezen stuk tekst wordt daarna meteen via microfoon opgenomen en Sam probeert het zelf, via Speech Recognition, te verstaan. Het resultaat van de speech recognition wordt dan gelezen door Sam enzovoort… Dit is een voorbeeld van Sam in dialoog met zichzelf:
I am sitting in a room different from the one you are in now. I am recording the sound of my speaking voice and I am going to play it back into the room again.
I’m sitting in a room different from the one U.N. NA I’m recording the sound of my speak English and I’m going to play it back into the room against
I’m sitting in a room different from the one you could in a LAN recording the sound of my speak English and I’m going to clamp back into the room against
I’m sitting in a room different from the one you put in a LAN recording the sound and I speak English and I’m going to clamp back into the room against
I’m sitting in a room different from the one you put in a LAN recording the sound and I speak a Mac into ghent
I’m sitting in a room different from the one you put in a LAN recording the sound and I speak a match into ghent
Kunstencentrum Vooruit heeft sinds kort een nieuwe site opgericht. Aan de site is een community luik gekoppeld waarop gebruikers een profiel kunnen aanmaken en evenementen op een persoonlijke wishlist kunnen plaatsen. Daarnaast kunnen ze er ook tickets voor voorstellingen kopen. Ook kunnen de gebruikers relaties tussen zichzelf en vrienden leggen.
Aan de hand van die gegevens en de gegevens van in het back-office systeem zou het mogelijk moeten zijn om een cultureel profiel op te stellen van de gebruikers en ze gepersonaliseerde, relevante tips geven. De voordelen van zo’n Customer Intelligence systeem zijn legio:
Kunstencentrum Vooruit leert zijn klanten beter kennen
De klanten krijgen gepersonaliseerde tips en hierdoor wordt hun culturele interesse geprikkeld
Trends kunnen makkelijker ontdekt worden
Er kan gerichter reclame gevoerd worden
…
En dat C.I. systeem gaan wij volgend jaar ontwikkelen. Er zal een uitgebreid onderzoek gebeuren naar de manier waarop en daarna wordt een implementatie gekoppeld met de in Ruby on Rails ontwikkelde website.
Voor het vak algoritmen hebben we enkele sorteeralgoritmes besproken en in c geïmplementeerd. Dit is mijn versie van de algoritmes het gebruikt een interface SortAlgorithm en het Strategy design pattern om zijn werk te doen.
In principe kan om het even wat gesorteerd worden maar sommige sorteeralgoritmes (Counting Sort) werken enkel met int’s. Om strings te sorteren kan gebruik gemaakt worden van de Nstring klasse.
Elk sorteeralgoritme kan getest en gemeten worden, dit is de uitvoor voor het shell sort algoritme met de Sedgewick incrementen:
Hier kan de code gedownload worden: “download”:[Sort.zip]. Niet alle algoritmes werken even goed dit is een lijst van werkende algoritmes die het wel doen:
Ik werk momenteel bij Encima. Encima maakt websites en andere toepassingen in Java. Mijn eerste week zit er al op en ik heb me bezig gehouden met een module voor www.weekendesk.com. Maandag wordt de module, samen met de nieuwe versie van de site, in gebruik genomen. Weekenddesk doet het volgende:
Weekendesk.com is een B2C e-commerce site die weekend- en dagtrips on line verkoopt en zich hierbij in eerste instantie op de Belgische en Nederlandse markt richt.
Weekendesk fungeert hierbij als tussenpersoon tussen de consument en de organisator van de vrijetijdsactiviteit.
De website biedt de klant op een frisse en overzichtelijke manier alle nodige informatie over de vrijetijdsactiviteiten.
De activiteiten zijn onderverdeeld in twee types: cadeaubonnen en weekendideeën. De prijs en beschikbaarheid van elke activiteit is steeds up-to-date. On line boeken is snel, eenvoudig en veilig. Betalen kan via creditcard of per overschrijving.
Via een on line content management module kan Weekendesk alle activiteiten en de gerelateerde informatie (beschrijving, fotoboek, prijzen, beschikbaarheid, promotie, ...) beheren. Een order management module laat hen toe de bestellingen on line op te volgen.
Ook de leveranciers (organisatoren) van de activiteiten kunnen via een private on line module de beschikbaarheid, prijzen en promoties inbrengen.
En net die module voor de leveranciers, organisatoren (meestal hotels) heb ik in elkaar gestoken.
Mel en ik zijn bezig aan een systeem om war games te ondersteunen. War games zijn
grootschalige ramp-oefeningen.
Bijvoorbeeld een aanval van terroristen op een kerncentrale. Er wordt een bepaald scenario opgesteld: terroristen
gijzelen werknemers en dreigen de boel op te blazen. Er wordt op deze situatie gereageerd door iedereen die daar
in het echt ook mee zou te maken hebben: politie, swat teams, er worden fake nieuwsberichten gemaakt door de media,
de werknemers van de centrale zelf,....
Tijdens die simulatie wordt adhv vragenlijsten gepolst hoe goed (of slecht)
alles verloopt. Die vragenlijsten komen op een beveiligde website die wij aan het programmeren zijn.
Die data is dan de basis voor een rapport met de bevindingen: wat verliep er goed en wat kan beter.
We gebruiken het ASP.NET 2.0 platform in samenwerking met een sql express 2005 database én een object database: db4o. Daarmee zijn we aan het experimenteren. Daarbij horen unit tests en load tests. Daaruit blijkt dat Db4o zijn beloftes waar maakt:
Embed db4o's native Java and .NET open source object database engine into your product and store even the most complex object structures with only one line of code.
db4o slashes development cost and time, provides superior performance, and requires no DBA.
blijkbaar zijn we verplicht een access database te gebruiken, hoe 1994, zucht.
 Fig: Gemini imagining the age of AI exploits.
Fig: Gemini imagining the age of AI exploits.  Last Friday, I had the pleasure of facilitating a hands-on workshop in Luxembourg as part of
Last Friday, I had the pleasure of facilitating a hands-on workshop in Luxembourg as part of 


 Power banks have become a staple for charging smartphones, tablets, and other devices on the go. They seem ideal to power small microcontroller projects but, they often pose a problem for low-current applications. Most modern power banks include an auto-shutdown feature to conserve energy when they detect a current draw below a specific threshold, often around 50–200mA. The idea being that the power bank can shut off after charging a smartphone. However, if you rely on power banks to power DIY electronics projects or remote applications with low current draw, this auto-off feature can be a significant inconvenience.
Power banks have become a staple for charging smartphones, tablets, and other devices on the go. They seem ideal to power small microcontroller projects but, they often pose a problem for low-current applications. Most modern power banks include an auto-shutdown feature to conserve energy when they detect a current draw below a specific threshold, often around 50–200mA. The idea being that the power bank can shut off after charging a smartphone. However, if you rely on power banks to power DIY electronics projects or remote applications with low current draw, this auto-off feature can be a significant inconvenience. In my house, I have a few smart home features: to control ventilation, to open and close solar screens, and to switch a few smart sockets. Up until a couple of days ago, the ventilation and screen controllers operated using custom software running on an ESP32. However, configuring, maintaining, upgrading, and integrating with this custom software gradually became a headache.
In my house, I have a few smart home features: to control ventilation, to open and close solar screens, and to switch a few smart sockets. Up until a couple of days ago, the ventilation and screen controllers operated using custom software running on an ESP32. However, configuring, maintaining, upgrading, and integrating with this custom software gradually became a headache.
 Fig: a black box generating 3D models.
Fig: a black box generating 3D models.











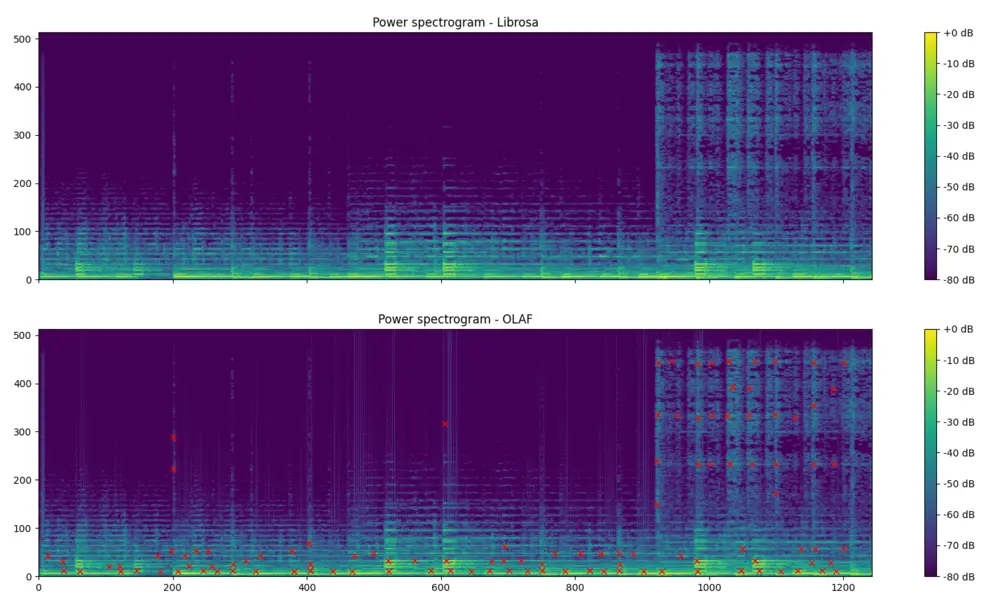 \
\







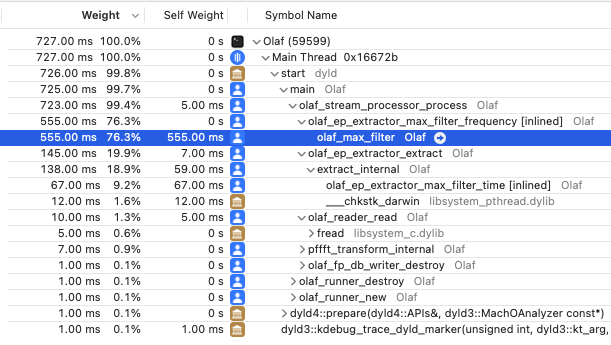 \
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
















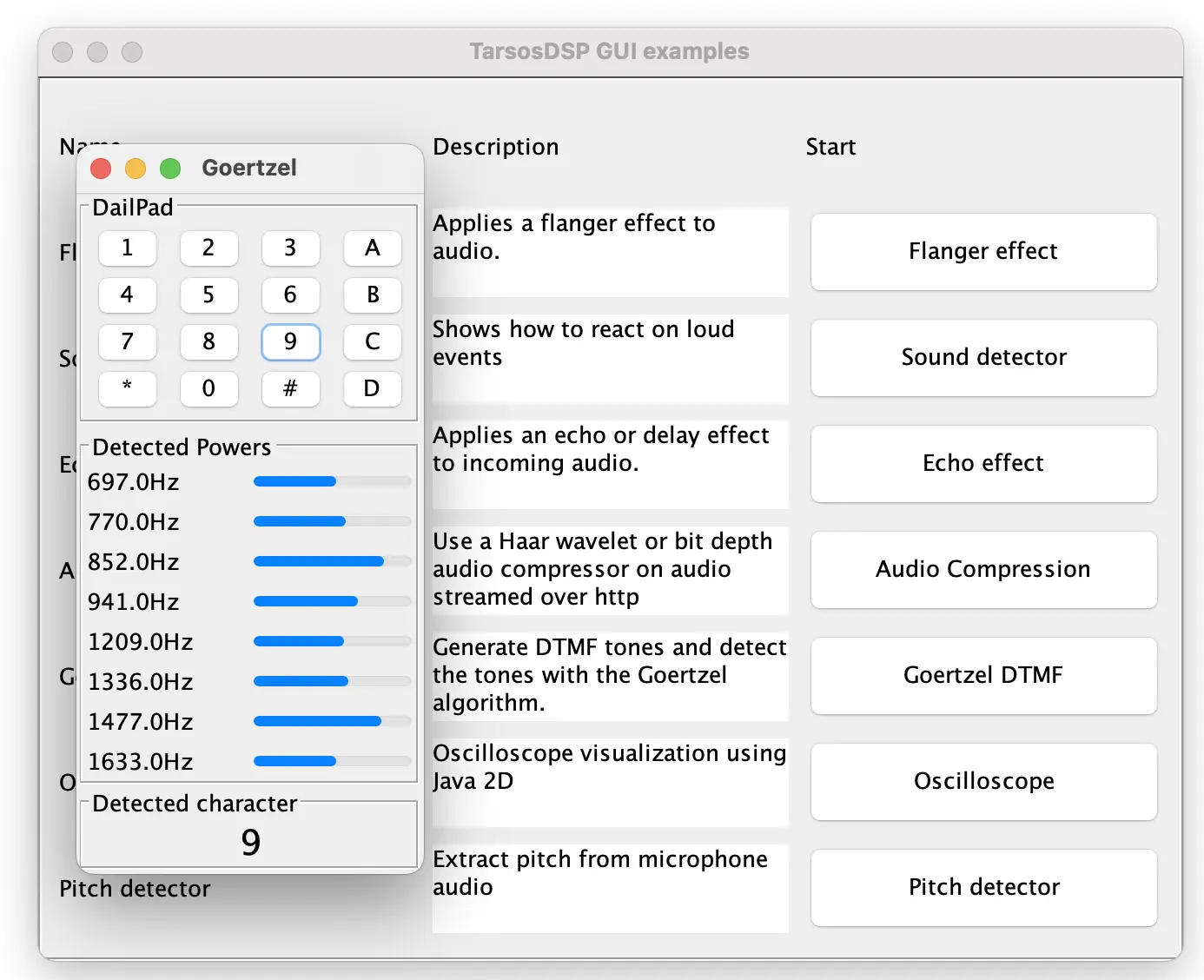










 \
Fig. General content based audio search scheme.
\
Fig. General content based audio search scheme.
 \
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.
\
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.

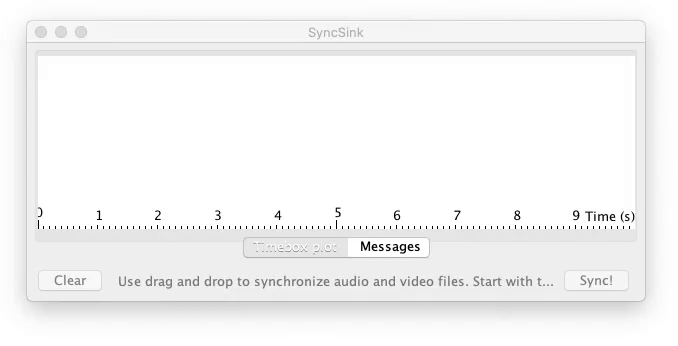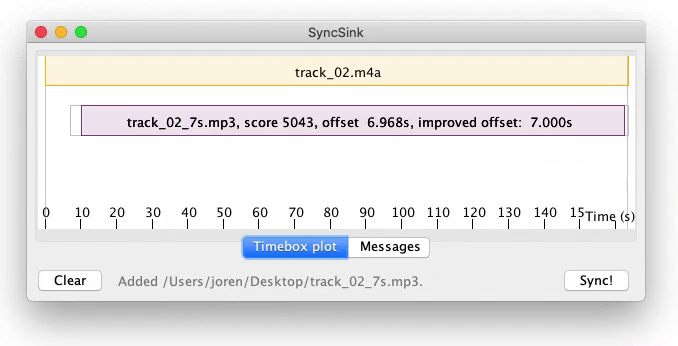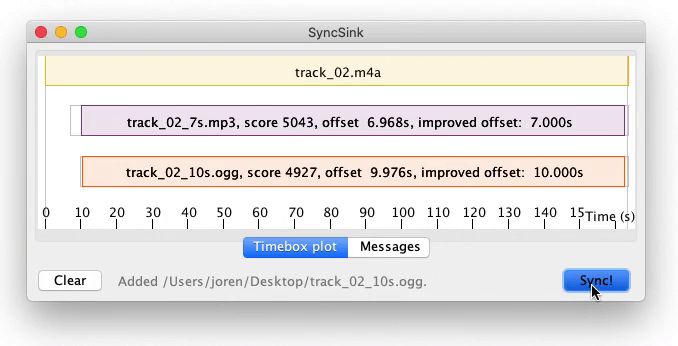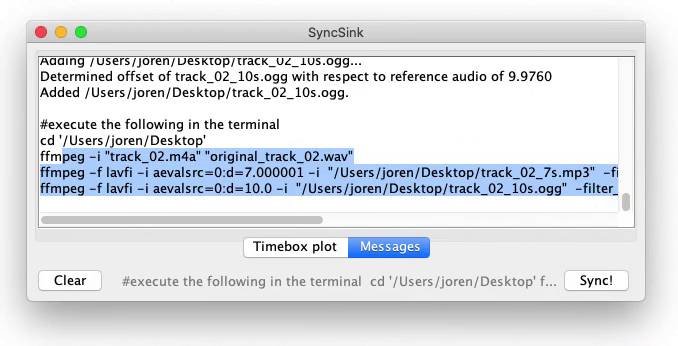



 A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.
A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.

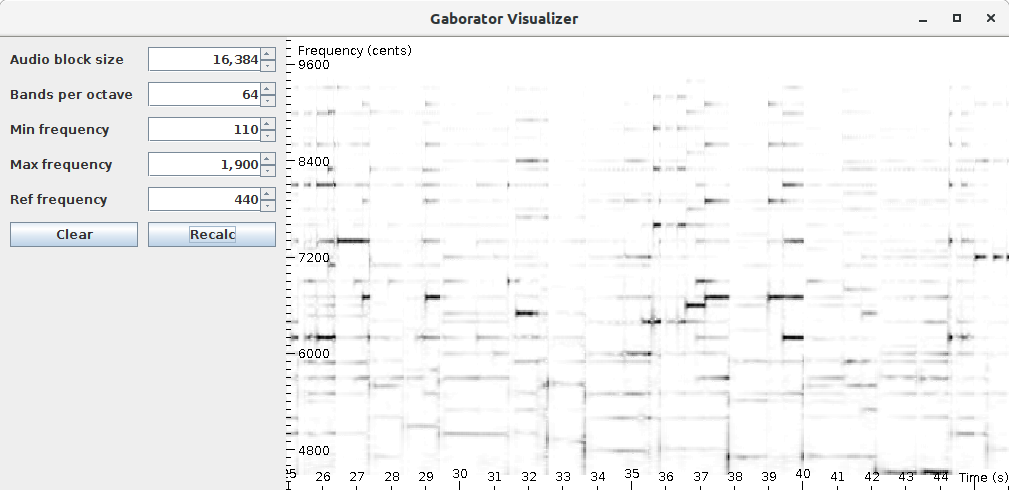



 The
The 


 can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).")


 while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.")
 and balanceboard data (bottom, purple).")
, accelerometer-data (green) and audio (black).")





 This post describes how to get notifications from a Bluetooth LE (Low Energy) or Bluetooth v4.0 device on a Linux machine. Since it took me a while to get it going it is perhaps of interest to others.
This post describes how to get notifications from a Bluetooth LE (Low Energy) or Bluetooth v4.0 device on a Linux machine. Since it took me a while to get it going it is perhaps of interest to others.

 This post explains how to receive
This post explains how to receive  This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).
This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).














 This post is about a hack I did for the 2012
This post is about a hack I did for the 2012 


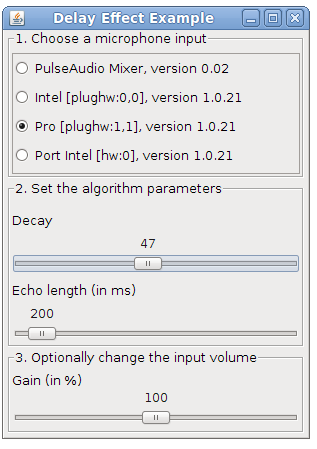
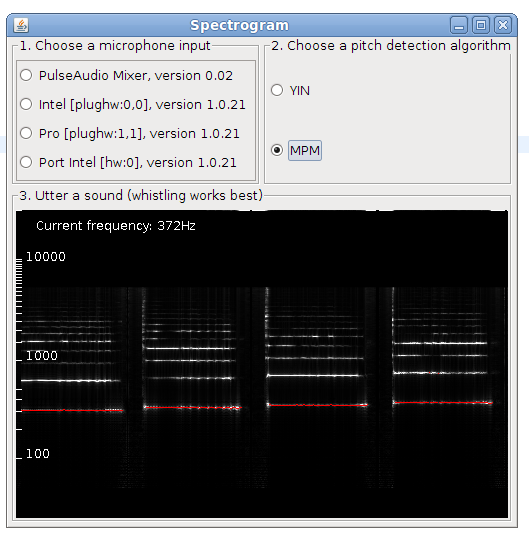
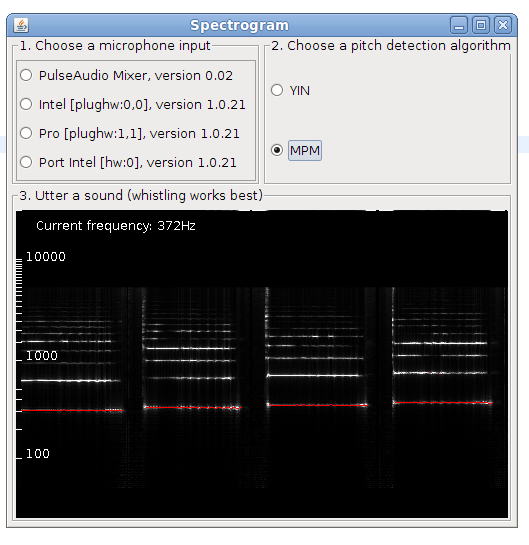



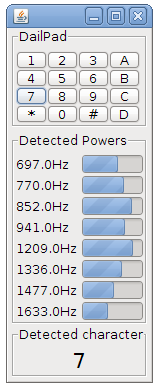


 The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the
The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the 




 While working on a Latex document with several collaborators some problems arise:
While working on a Latex document with several collaborators some problems arise: The Pidato experiment demonstrates a rather straightforward method to handle vibrato on a digital piano. It solves the age-old problem on what to do with the enigmatic “vibrato” instructions on some piano solo scores of Franz Liszt. The figure on the right is an exerpt of
The Pidato experiment demonstrates a rather straightforward method to handle vibrato on a digital piano. It solves the age-old problem on what to do with the enigmatic “vibrato” instructions on some piano solo scores of Franz Liszt. The figure on the right is an exerpt of 





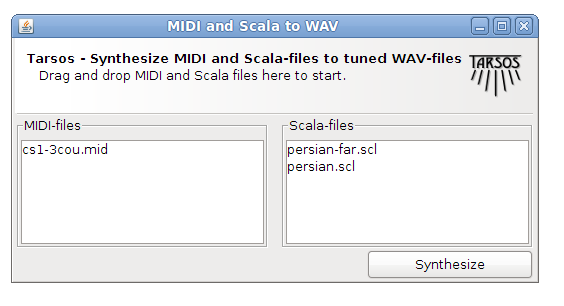










 TwinSeats is een website / online initiatief om nieuwe mensen te leren kennen. Met hen deel je dezelfde culturele interesse en ga je vervolgens samen naar deze of gene voorstelling. Door events centraal te stellen kan TwinSeats uitzonderlijke cultuurburen zoeken. Leden vinden die cultuurburen dankzij een gezamenlijke voorliefde voor een artiest of attractie of eender welke bezigheid in de vrijetijdssfeer.
TwinSeats is een website / online initiatief om nieuwe mensen te leren kennen. Met hen deel je dezelfde culturele interesse en ga je vervolgens samen naar deze of gene voorstelling. Door events centraal te stellen kan TwinSeats uitzonderlijke cultuurburen zoeken. Leden vinden die cultuurburen dankzij een gezamenlijke voorliefde voor een artiest of attractie of eender welke bezigheid in de vrijetijdssfeer.











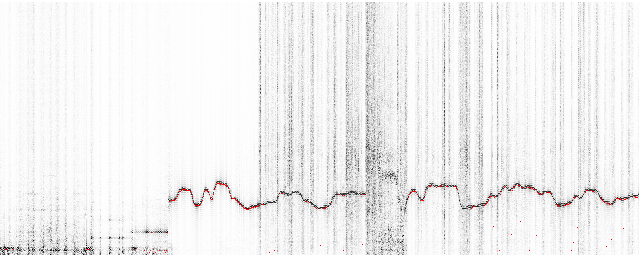
 This is the scenario: you have a Huawei e220, a linux computer and you want to react to a call from a set of predefined numbers. E.g.
This is the scenario: you have a Huawei e220, a linux computer and you want to react to a call from a set of predefined numbers. E.g. 


















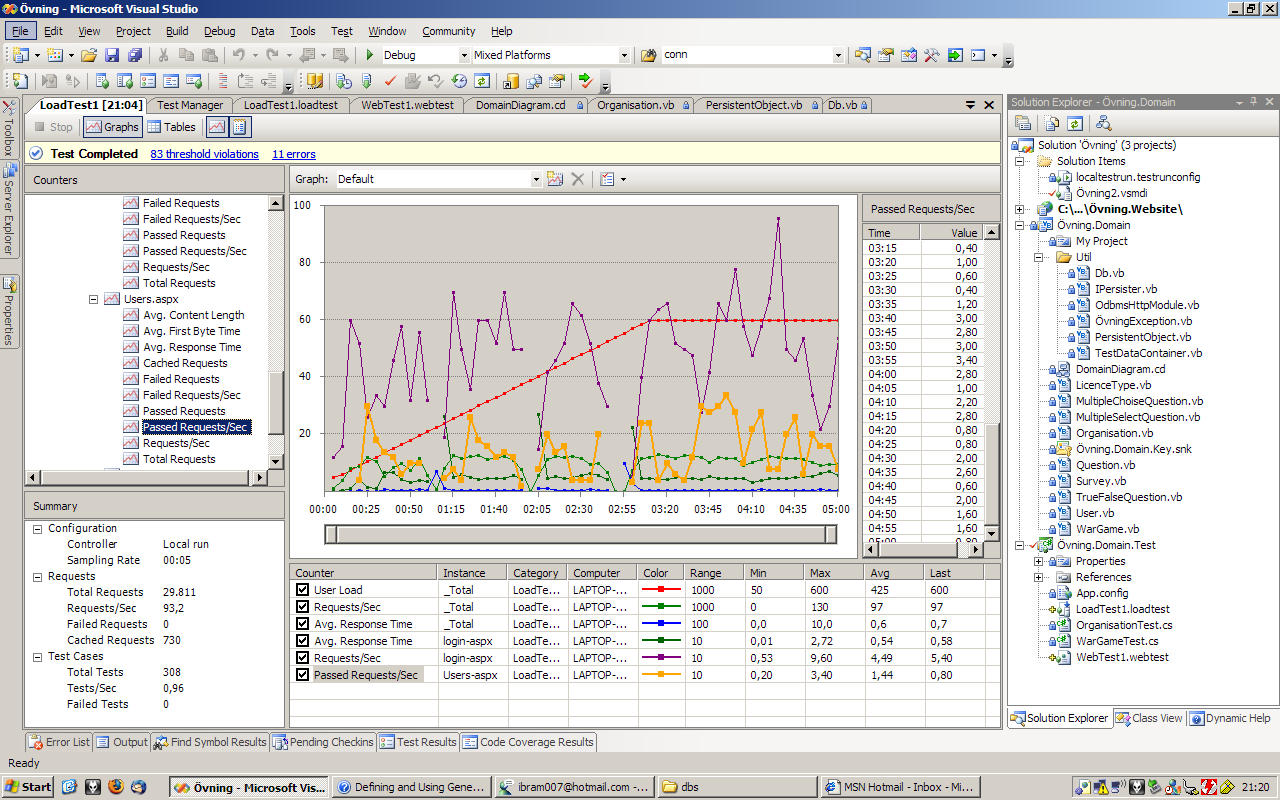{kind=link}