The research output tracking system of Ghent University (biblio) and Flanders FWO’s academic profile are not built to track software as research output. The focus is still solely on papers, even when custom developed research software has become a fundamental aspect in many research areas. My role is somewhere between that of a ‘pure’ researcher and that of a research software engineer which makes this focus on papers quite relevant to me.
The paper aims to make the recent development on Panako‘count’. Thanks to the JOSS review process the Panako software was improved considerably: CI, unit tests, documentation, containerization,… The paper was a good reason to improve on all these areas which are all too easy to neglect. The paper itself is a short, rather general overview of Panako:
“Panako solves the problem of finding short audio fragments in large digital audio archives. The content based audio search algorithm implemented in Panako is able to identify a short audio query in a large database of thousands of hours of audio using an acoustic fingerprinting technique.”
This work presents updates to Panako, an acoustic fingerprinting system that was introduced at ISMIR 2014. The notable feature of Panako is that it matches queries even after a speedup, time-stretch or pitch-shift. It is freely available and has no problems indexing and querying 100k sea shanties. The updates presented here improve query performance significantly and allow a wider range of time-stretch, pitch-shift and speed-up factors: e.g. the top 1 true positive rate for 20s query that were sped up by 10 percent increased from 18% to 83% from the 2014 version of Panako to the new version. The aim of this short write-up is to reintroduce Panako, evaluate the improvements and highlight two techniques with wider applicability. The first of the two techniques is the use of a constant-Q non-stationary Gabor transform: a fast, reversible, fine-grained spectral transform which can be used as a front-end for many MIR tasks. The second is how near-exact hashing is used in combination with a persistent B-Tree to allow some margin of error while maintaining reasonable query speeds.
Together with the paper there is also a poster and a short video presentation which explains the work:
I have just released a new version of SyncSink. SyncSink is a tool to synchronize media files with shared audio. It is ideal to synchronize video captured by multiple cameras or audio captured by many microphones. It finds a rough alignment between audio captured from the same event and subsequently refines that offset with a crosscorrelation step. Below you can see SyncSink in action or you can try out SyncSink (you will need ffmpeg and Java installed on your system).
SyncSink used to be part of the Panako acoustic fingerprinting system but I decided that it was better to keep the Panako package focused and made a separate repository for SyncSink. More information can be found at the SyncSink GiHub repo
SyncSink is a tool to synchronize media files with shared audio. SyncSink matches and aligns shared audio and determines offsets in seconds. With these precise offsets it becomes trivial to sync files. SyncSink is, for example, used to synchronize video files: when you have many video captures of the same event, the audio attached to these video captures is used to align and sync multiple (independently operated) cameras.
Evidently, SyncSink can also synchronize audio captured from many (independent) microphones if some environmental sound is shared (leaked in) the each recording.
I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).
By Reinier de Valk (DANS), Anja Volk (Utrecht University), Andre Holzapfel (KTH Royal Institute of Technology) , Aggelos Pikrakis (University of Piraeus), Nadine Kroher (University of Seville - IMUS) and Joren Six (Ghent University - IPEM). Next to the version of record there is also an author version available of the contribution titled “MIRchiving: Challenges and opportunities of connecting MIR research and digital music archives”:[2017.DLfM.MIRchiving-author.pdf].
This study is a call for action for the music information retrieval (MIR) community to pay more attention to collaboration with digital music archives. The study, which resulted from an interdisciplinary workshop and subsequent discussion, matches the demand for MIR technologies from various archives with what is already supplied by the MIR community. We conclude that the expressed demands can only be served sustainably through closer collaborations. Whereas MIR systems are described in scientific publications, usable implementations are often absent. If there is a runnable system, user documentation is often sparse—-posing a huge hurdle for archivists to employ it. This study sheds light on the current limitations and opportunities of MIR research in the context of music archives by means of examples, and highlights available tools. As a basic guideline for collaboration, we propose to interpret MIR research as part of a value chain. We identify the following benefits of collaboration between MIR researchers and music archives: new perspectives for content access in archives, more diverse evaluation data and methods, and a more application-oriented MIR research workflow.
By Federica Bressan, Joren Six and Marc Leman (Ghent University - IPEM). Next to the version of record there is also an author version available of the contribution titled “Applications of duplicate detection: linking meta-data and merging music archives: The experience of the IPEM historical archive of electronic music”:[2017.dlfm_duplicates-author.pdf].
This work focuses on applications of duplicate detection for managing digital music archives. It aims to make this mature music information retrieval (MIR) technology better known to archivists and provide clear suggestions on how this technology can be used in practice. More specifically applications are discussed to complement meta-data, to link or merge digital music archives, to improve listening experiences and to re-use segmentation data. The IPEM archive, a digitized music archive containing early electronic music, provides a case study.
The article titled “Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment” by Joren Six and Marc Leman has been accepted for publication in the Journal on Multimodal User Interfaces. The article will be published later this year. It describes and tests a method to synchronize data-streams. Below you can find the abstract, pointers to the software under discussion and an author version of the article itself.
Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment An Application of Acoustic Fingerprinting to Facilitate Music Interaction Research
Abstract:Research on the interaction between movement and music often involves analysis of multi-track audio, video streams and sensor data. To facilitate such research a framework is presented here that allows synchronization of multimodal data. A low cost approach is proposed to synchronize streams by embedding ambient audio into each data-stream. This effectively reduces the synchronization problem to audio-to-audio alignment. As a part of the framework a robust, computationally efficient audio-to-audio alignment algorithm is presented for reliable synchronization of embedded audio streams of varying quality. The algorithm uses audio fingerprinting techniques to measure offsets. It also identifies drift and dropped samples, which makes it possible to find a synchronization solution under such circumstances as well. The framework is evaluated with synthetic signals and a case study, showing millisecond accurate synchronization.
The algorithm under discussion is included in Panako an audio fingerprinting system but is also available for download here. The SyncSink application has been packaged separately for ease of use.
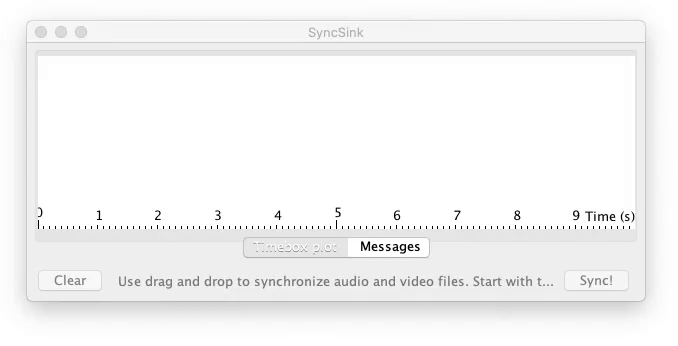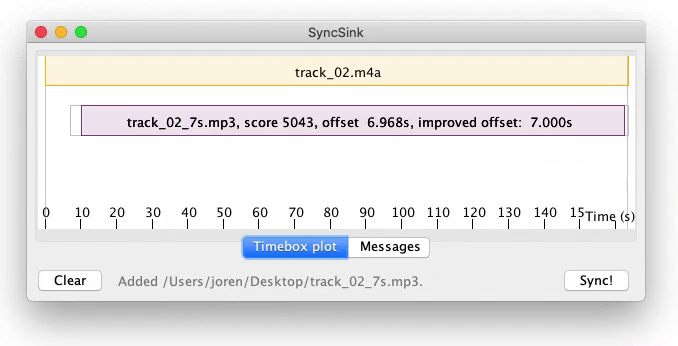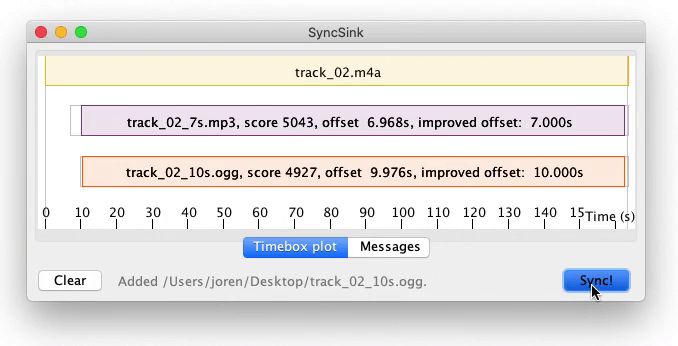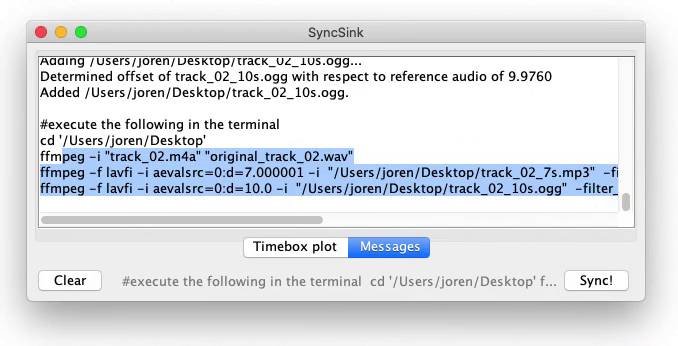
To use the application start it with double click the downloaded SyncSink JAR-file. Subsequently add various audio or video files using drag and drop. If the same audio is found in the various media files a time-box plot appears, as in the screenshot below. To add corresponding data-files click one of the boxes on the timeline and choose a data file that is synchronized with the audio. The data-file should be a CSV-file. The separator should be ‘,’ and the first column should contain a time-stamp in fractional seconds. After pressing Sync a new CSV-file is created with the first column containing correctly shifted time stamps. If this is done for multiple files, a synchronized sensor-stream is created. Also, ffmpeg commands to synchronize the media files themselves are printed to the command line.
This work was supported by funding by a Methusalem grant from the Flemish Government, Belgium. Special thanks goes to Ivan Schepers for building the balance boards used in the case study. If you want to cite the article, use the following BiBTeX:
@article{six2015multimodal,
author = {Joren Six and Marc Leman},
title = {{Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment}},
issn = {1783-7677},
volume = {9},
number = {3},
pages = {223-229},
doi = {10.1007/s12193-015-0196-1},
journal = {{Journal of Multimodal User Interfaces}},
publisher = {Springer Berlin Heidelberg},
year = 2015
}
A microcontroller fitted with an electret microphone and a microSD card slot. It can record audio in real-time together with sensor data.
Conceptual drawing used as a basis for the SyncSync application. A reference stream (blue) can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).
SyncSink Synchronize media files. A user-friendly interface to synchronize media and data files. First a reference media-file is added using drag-and-drop. The audio steam of the reference is extracted and plotted on a timeline as the topmost box. Subsequently other media-files are added. The offsets with respect to the reference are calculated and plotted. CSV-files with timestamps and data recorded in sync with a stream can be attached to a respective audio stream. Finally, after pressing Sync!, the data and media files are modified to be exactly in sync with the reference.
Multimodal recording system diagram. Each webcam has a microphone and is connected to the pc via USB. The dashed arrows represent analog signals. The balance board has four analog sensors but these are simplified to one connection in the schematic. The analog output of the microphones is also recorded through the DAQ. An analog accelerometer is connected with a microcontroller which also records audio.
Two streams of audio with fingerprints marked. Some fingerprints are present in both streams (green, O) while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.
Synchronized streams in Sonic Visualizer. Here you can see two channel audio synchronized with accelerometer data (top, green) and balanceboard data (bottom, purple).
The synchronized data from the two webcams, accelerometer and balanceboard in ELAN. From top to bottom the synchronized streams are two video-streams, balance-board data (red), accelerometer-data (green) and audio (black).
The 27th of November, 2014 a lecture on audio fingerprinting and its applications for digital musicology will be given at IPEM. The lecture introduces audio fingerprinting, explains an audio fingerprinting technique and then goes on to explain how such algorithm offers opportunities for large scale digital musicological applications. Here you can download the slides about audio fingerprinting and its opportunities for digital musicology.
With the explained audio fingerprinting technique a specific form of very reliable musical structure analysis can be done. Below, in the figure section, an example of repetitive structure in the song Ribs Out is shown. Another example is comparing edits or versions of songs. Below, also in the figure section, the radio edit of Daft Punk’s Get Lucky is compared with the original version. Audio synchronization using fingerprinting is another application that is actively used in the field of digital musicology to align audio with extracted features.
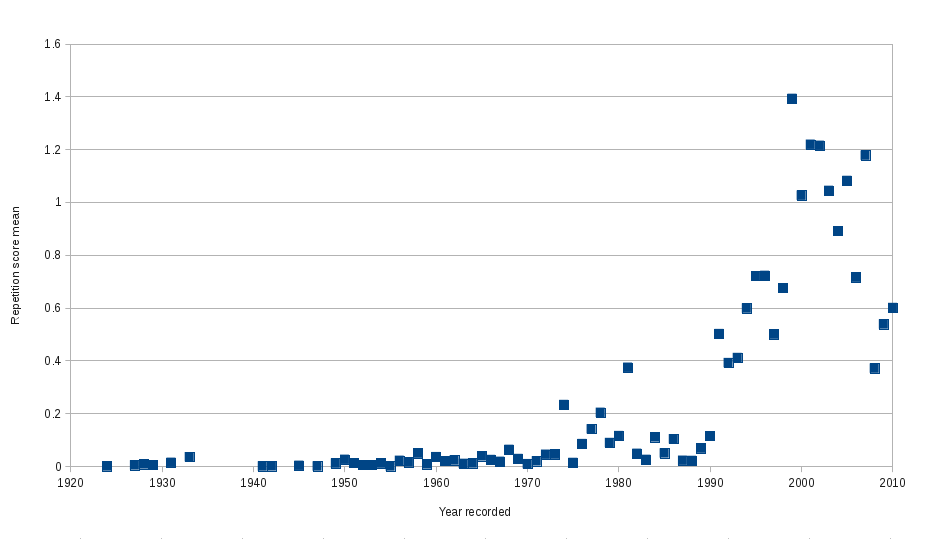
Since acoustic fingerprinting makes structure analysis very efficiently it can be applied on a large scale (20k songs). The figure below shows that identical repetition is something that has been used more and more since the mid 1970’s. The trend probably aligns with the amount of technical knowledge needed to ‘copy and paste’ a snippet of music.
\
Fig: How much identical repetition is used in music, over the years.
 Fig: DALL.E 2 imagining a fight between papers and software.
Fig: DALL.E 2 imagining a fight between papers and software.
 I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).
I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).
 can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).")


 while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.")
 and balanceboard data (bottom, purple).")
, accelerometer-data (green) and audio (black).")
 \
\


