TarsosDSP is a Java library for audio processing I have started working on more than 10 years ago. The aim of TarsosDSP is to provide an easy-to-use interface to practical music processing algorithms. Obviously, I have been using it myself over the years as my go-to library for audio-processing in Java. However, a number of gradual changes in the java ecosystem made TarsosDSP more and more difficult to use.
Since I have apparently not been the only one using it, there was a need to give it some attention. During the last couple of weeks I have found the time to give it this much needed attention. This resulted in a number of updates, some of the changes include:
Change of the build system from Apache Ant to Gradle
Make use of Java Modules to make TarsosDSP compatible with the ModulePath introduced in Java 9.
Packaged the software into a maven compatible format, which makes it easy to use as a dependency.
CI with GitHub actions to automatically build and test the software.
Updated some examples shipped with the TarsosDSP. I have still still some examples to verify.
Improved handling of errors on reading audio via ffmpeg
\
Fig: The updated TarsosDSP release contains many CLI and GUI example applications.
Notably the code of TarsosDSP has not changed much apart from some cosmetic changes. This backwards compatibility is one of the strong points of Java. With this update I am quite confident that TarsosDSP will also be usable during the next decade as well.
This post explains how to do real-time pitch-shifting and audio time-stretching in Java. It uses two components. The first component is a high quality software C library for audio time-stretching and pitch-shifting C called Rubber Band. The second component is a Java audio library called TarsosDSP. To bridge the gap between the two JNI (Java Native Interface) is used. Rubber Band provides a JNI interface and starting from the currently unreleased version 1.8.2, makefiles are provided that make compiling and subsequently using the JNI version of Rubber Band relatively straightforward.
However, it still requires some effort to control real-time pitch-shifting and audio time-stretching from java. To make it more easy some example code and documentation is available in a GitHub repository called RubberBandJNI. It documents some of the configuration steps needed to get things working. It also offers precompiled libraries and documents how to compile those for the following systems:
This post describes how to decode MP3’s using an already compiled ffmpeg binary on android. Using ffmpeg to decode audio on Android has advantages:
It supports about every audio format known to man. Three channel flac, vorbis with 32 bit samples, … do not pose a problem.
Extracting audio from video container formats is supported. Accessing the first audio stream from mkv, avi, mov,… just works.
Decoding audio frames is more efficient using native code than often buggy Java decoders.
Resampling and downmixing is supported. If you want to resample incoming audio to e.g. 44.1kHz and only want single channel audio this is easily achievable.
The main disadvantage is that you need an ffmpeg build for your Android device. Luckily some poor soul already managed to compile ffmeg for Android for several architectures. The precompiled ffmpeg binaries for Android are available for download and are mirrored here as well.
To bridge the ffmpeg binary and the java world TarsosDSP contains some glue code. The AndroidFFMPEGLocator is responsible to find and extract the correct binary for your Android device. It expects these ffmpeg binaries in the assets folder of your Android application. When the correct ffmpeg binary has been extracted and made executable the PipeDecoder is able to call it. The PipeDecoder calls ffmpeg so that decoded, downmixed and resampled PCM samples are streamed into the Java application via a pipe, which explains its name.
With the TarsosDSP Android library the following code plays an MP3 from external storage:
This code just works if the application has the READ_EXTERNAL_STORAGE permission, includes a recent TarsosDSP-Android.jar, is ran on one of the supported ffmpeg architectures and has these binaries available in the assets folder.
TarsosDSP, the is a real-time audio processing library written in Java, is featured in EFY (Electronics For Your) Plus Magazine of July 2015. It is a leading electronics magazine with a history going back more than 40 years and about 300 000 subscribers mainly in India. The index mentions this:
TarsosDSP: A Real-Time Audio Analysis and Processing Framework\
In last month’s EFY Plus, we discussed Essentia, a C library for audio analysis. In this issue we will discuss a Java based real-time audio analysis and processing framework known as TarsosDSP
To read the full article, buy a (digital) copy of the magazine.
TarsosDSP is a real-time audio processing library written in Java. Since version 2.0 it is compatible with Android. Judging by the number of forks of the TarsosDSP GitHub repository Android compatibility increased the popularity of the library. Now the first Android application which uses TarsosDSP has found its way to the Google Play store. Download and play with SINGmaster to see an application of the pitch tracking capabilities within TarsosDSP. The SINGmaster description:
“SING master is a smart phone app that helps you to learn how to sing. SING master presents a collection of practical exercises (on the most important building blocks of melodies). Colours and sounds guide you in the exercise. After recording, SING master gives visual feedback : you can see and hear your voice. This is important so that you can identify where your mistakes are.”
Another application in the Play Store that uses TarsosDSP is CuePitcher.
It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the pdj~ object, which should be compatible with the Max/MSP implementation. This post demonstrates a patch that connects an oscillator with a pitch tracking algorithm implemented in TarsosDSP.
To the left you can see the finished patch. When it is working an audio stream is generated using an oscillator. The frequency of the oscillator can be controlled. Subsequently the stream is send to the Java environment with the pdj bridge. The Java environment receives an array of floats, representing the audio. A pitch estimation algorithm tries to find the pitch of the audio represented by the buffer. The detected pitch is returned to the pd environment by means of outlet. In pd, the detected pitch is shown and used for auditory feedback.
PitchDetectionResult result = yin.getPitch(audioBuffer);
pitch = result.getPitch();
outlet(0, Atom.newAtom(pitch));
Please note that the pitch detection algorithm can handle any audio stream, not only pure sines. The example here demonstrates the most straightforward case. Using this method all algorithms implemented in TarsosDSP can be used in Pure Data. These range from onset detection to filtering, from audio effects to wavelet compression. For a list of features, please see the TarsosDSP github page. Here, the source for this patch implementing pitch tracking in pd can be downloaded. To run it, extract it to a directory and simply run the pitch.pd patch. Pure Data should load pdj~ automatically together with the classes present in the classes directory.
This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies.
Since version 2.0 there are no more references to javax.sound.* in the TarsosDSP core codebase. This makes it easy to run TarsosDSP on Android. Audio Input/Output operations that depend on either the JVM or Dalvik runtime have been abstracted and removed from the core. For each runtime target a Jar file is provided in the TarsosDSP release directory.
The following example connects an AudioDispatcher to the microphone of an Android device. Subsequently, a real-time pitch detection algorithm is added to the processing chain. The detected pitch in Hertz is printed on a TextView element, if no pitch is present in the incoming sound, –1 is printed. To test the application download and install the /files/attachments/420/TarsosDSPAndroid.apk(/files/attachments/420/TarsosDSPAndroid.apk) application on your Android device. The source code is available as well.
The TarsosDSP Java library for audio processing now contains an implementation of the Haar Wavelet Transform. A discrete wavelet transform based on the Haar wavelet (depicted at the right). This reversible transform has some interesting properties and is practical in signal compression and for analyzing sudden transitions in a file. It can e.g. be used to detect edges in an image.
As an example use case of the Haar transform, a simple lossy audio compression algorithm is implemented in TarsosDSP. It compresses audio by dividing audio into bloks of 32 samples, transforming them using the Haar wavelet Transform and subsequently removing samples with the least difference between them. The last step is to reverse the transform and play the audio. The amount of compressed samples can be chosen between 0 (no compression) and 31 (no signal left). This crude lossy audio compression technique can save at least a tenth of samples without any noticeable effect. A way to store the audio and read it from disk is included as well.
The algorithm works in real time and an example application has been implemented which operates on an mp3 stream. To make this work immediately, the avconv tool needs to be on your system’s path. Also implemented is a bit depth compressor, which shows the effect of (extreme) bit depth compression.
The TarsosDSP Java library for audio processing now contains a module for spectral peak extraction. It calculates a short time Fourier transform and subsequently finds the frequency bins with most energy present using a median filter. The frequency estimation for each identified bin is significantly improved by taking phase information into account. A method described in “Sethares et al. 2009 - Spectral Tools for Dynamic Tonality and Audio Morphing”.
The noise floor, determined by the median filter, the spectral information itself and the estimated peak locations are returned for each FFT-frame. Below a visualization of a flute can be found. As expected, the peaks are harmonically spread over the complete spectrum up until the Nyquist frequency.
Spectral peaks of a flute. The first 10 harmonic are detected up until the Nyquist frequency.
TarsosDSP will be presented at the AES 53rd International conference on Semantic Audio in London . During the conference both a presentation and demonstration of the paper “TarsosDSP, a Real-Time Audio Processing Framework in Java”:[aes53_tarsos_dsp.pdf], by Joren Six, Olmo Cornelis and Marc Leman, in Proceedings of the 53rd AES Conference (AES 53rd), 2014. From their website:
Semantic Audio is concerned with content-based management of digital audio recordings. The rapid evolution of digital audio technologies, e.g. audio data compression and streaming, the availability of large audio libraries online and offline, and recent developments in content-based audio retrieval have significantly changed the way digital audio is created, processed, and consumed. New audio content can be produced at lower cost, while also large audio archives at libraries or record labels are opening to the public. Thus the sheer amount of available audio data grows more and more each day. Semantic analysis of audio resulting in high-level metadata descriptors such as musical chords and tempo, or the identification of speakers facilitate content-based management of audio recordings. Aside from audio retrieval and recommendation technologies, the semantics of audio signals are also becoming increasingly important, for instance, in object-based audio coding, as well as intelligent audio editing, and processing. Recent product releases already demonstrate this to a great extent, however, more innovative functionalities relying on semantic audio analysis and management are imminent. These functionalities may utilise, for instance, (informed) audio source separation, speaker segmentation and identification, structural music segmentation, or social and Semantic Web technologies, including ontologies and linked open data.
This conference will give a broad overview of the state of the art and address many of the new scientific disciplines involved in this still-emerging field. Our purpose is to continue fostering this line of interdisciplinary research. This is reflected by the wide variety of invited speakers presenting at the conference.
The paper presents TarsosDSP, a framework for real-time audio analysis and processing. Most libraries and frameworks offer either audio analysis and feature extraction or audio synthesis and processing. TarsosDSP is one of a only a few frameworks that offers both analysis, processing and feature extraction in real-time, a unique feature in the Java ecosystem. The framework contains practical audio processing algorithms, it can be extended easily, and has no external dependencies. Each algorithm is implemented as simple as possible thanks to a straightforward processing pipeline. TarsosDSP’s features include a resampling algorithm, onset detectors, a number of pitch estimation algorithms, a time stretch algorithm, a pitch shifting algorithm, and an algorithm to calculate the Constant-Q. The framework also allows simple audio synthesis, some audio effects, and several filters. The Open Source framework is a valuable contribution to the MIR-Community and ideal fit for interactive MIR-applications on Android. The full paper can be downloaded “TarsosDSP, a Real-Time Audio Processing Framework in Java”:[aes53_tarsos_dsp.pdf]
A BibTeX entry for the paper can be found below.
```ruby\
\@inproceedings{six2014tarsosdsp,\
author = {Joren Six and Olmo Cornelis and Marc Leman},\
title = {{TarsosDSP, a Real-Time Audio Processing Framework in Java}},\
booktitle = {{Proceedings of the 53rd AES Conference (AES 53rd)}},\
year = 2014\
}\
```
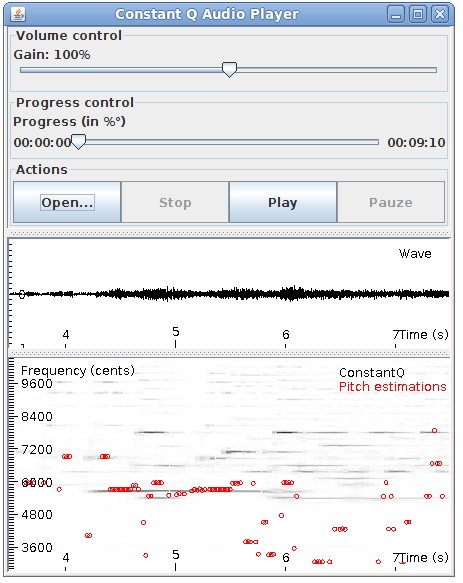
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a Constant-Q Transform (as of version 1.6). The Constant-Q transform does essentially the same thing as an FFT, but has the advantage that each octave has the same amount of bins. This makes the Constant-Q transform practical for applications processing music. If, for example, 12 bins per octave are chosen, these can correspond with the western musical scale.
Also included in the newest release (version 1.7) is a way to visualize the transform, or other musical features. The visualization implementation is done together with Thomas Stubbe.
The example application below shows the Constant-Q transform with an overlay of pitch estimations. The corresponding waveform is also shown.
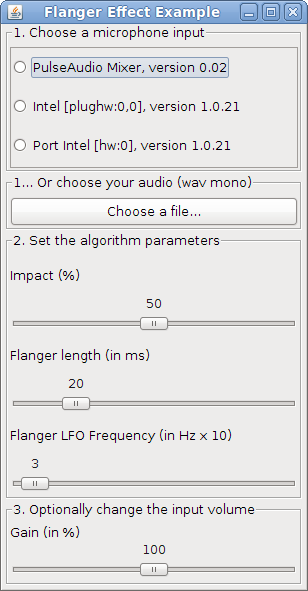
The DSP library for Taros, aptly named TarsosDSP, now includes an example demonstrating the flanging audio effect. Flanging, essentialy mixing the signal with a varying delay of itself, produces an interesting interference pattern.
The flanging example works on wav-files or on input from microphone. Try it yourself, download\
Flanging.jar, the executable jar file. Below you can check what flanging sounds like with various parameters.
The source code of the Java implementation can be found on the TarsosDSP github page.
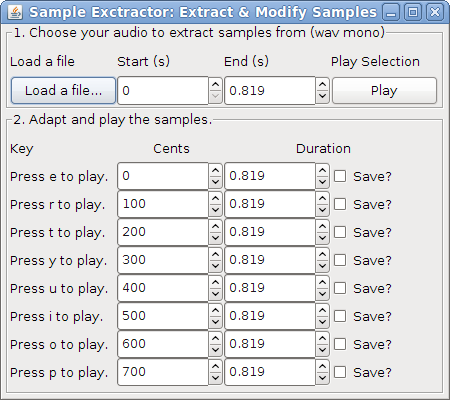
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize pitch estimations. The goal of the example is to show which errors are made by different pitch detectors.
To test the application, download and execute the Resynthesizer.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To hear what exactly it does, compare the following two audio fragments:
There is also a command line interface, the following command does pitch tracking, and follows the envelope of in.wav and immediately plays it on the default audio device. If you want to save the audio, see the command line options. The “flute example”:[flute.wav] is provided for your convenience.
\
java -jar Resynthesizer-latest.jar in.wav\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP resynthesizer
----------------------------------------------------
Synopsis:
java -jar CommandLineResynthesizer.jar [--detector DETECTOR] [--output out.wav] [--combined combined.wav] input.wav
----------------------------------------------------
Description:
Extracts pitch and loudnes from audio and resynthesises the audio with that information.
The result is either played back our written in an output file.
There is als an option to combine source and synthezized material
in the left and right channels of a stereo audio file.
input.wav a readable wav file.
--output out.wav a writable file.
--combined combined.wav a writable output file. One channel original, other synthesized.
--detector DETECTOR defaults to FFT_YIN or one of these:
YIN
MPM
FFT_YIN
DYNAMIC_WAVELET
AMDF
The source code of the Java implementation of the synthesizer can be found on the TarsosDSP github page.
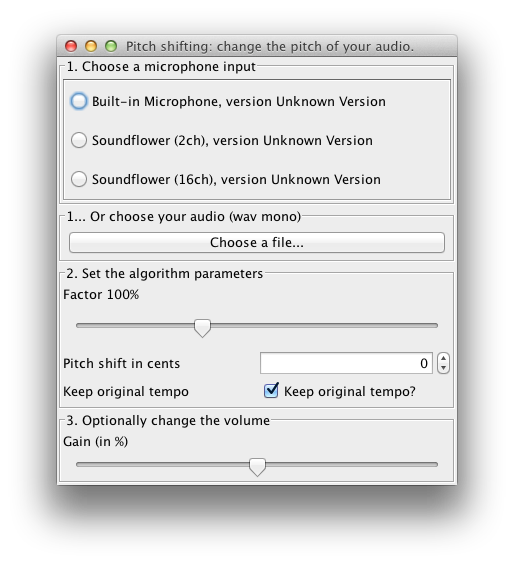
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4) and a time stretching algorithm. Combined, the two can be used for something like phase vocoding. With a phase vocoder you can load an audio snippet, change the pitch and duration and e.g. create a library of snippets. E.g. by recording one piano key stroke, it is possible to generate two octaves of samples of different lengths, and use those in stead of synthesized samples. The following example application shows exactly that, implemented in the java programming language.
The example application below shows how to pitch shift and time stretch a sample to create a sample library with the TarsosDSP library.
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4). The goal of pitch shifting is to change the pitch of a piece of audio without affecting the duration. The algorithm implemented is a combination of resampling and time stretching. Resampling changes the pitch of the audio, but affects the total duration. Consecutively, the duration of the audio is stretched to the original (without affecting pitch) with time stretching. The result is very similar to phase vocoding.
The example application below shows how to pitch shift input from the microphone in real-time, or pitch shift a recorded track with the TarsosDSP library.
To test the application, download and execute the PitchShift.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command lowers the pitch of in.wav by two semitones.
java -jar in.wav out.wav -200
----------------------------------------------------
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Pitch shifting utility.
----------------------------------------------------
Synopsis:
java -jar PitchShift.jar source.wav target.wav cents
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the pitch shifted file.
cents Pitch shifting in cents: 100 means one semitone up,
-100 one down, 0 is no change. 1200 is one octave up.
The resampling feature was implemented with libresample4j by Laszlo Systems. libresample4j is a Java port of Dominic Mazzoni’s libresample 0.1.3, which is in turn based on Julius Smith’s Resample 1.7 library.
Today a new version of the TarsosDSP library was released. TarsosDSP is a small library to do audio processing in Java. It features two new pitch detectors. An AMDF (Average Magnitude Difference Function) pitch detector, contributed by Eder Souza of Brazil and a faster implementation of YIN kindly provided by Matthias Mauch of Queen Mary University, London.
[](/releases/TarsosDSP/TarsosDSP-1.2/TarsosDSP-1.2-Examples/PitchDetector-1.2.jar)
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
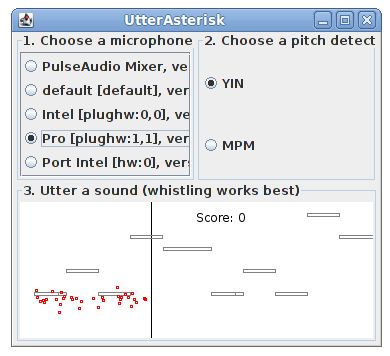
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
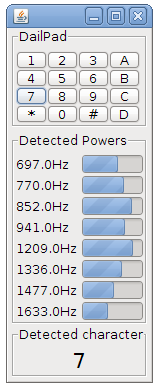
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
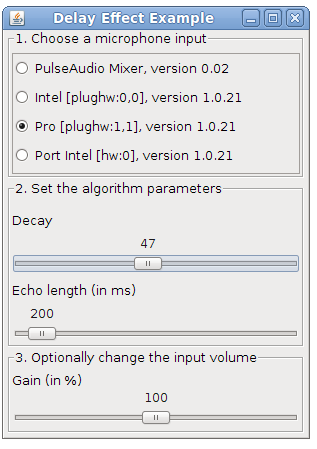
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of an audio echo effect. An echo effect is very simple to implement digitally and can serve as a good example of a DSP operation.
"":\[Delay.jar\]
The implementation of the effect can be seen below. As can be seen, to achieve an echo one simply needs to mix the current sample i with a delayed sample present in echoBuffer with a certain decay factor. The length of the buffer and the decay are the defining parameters for the sound of the echo. To fill the echo buffer the current sample is stored (line 4). Looping through the echo buffer is done by incrementing the position pointer and resetting it at the correct time (lines 6-9).
```java\
//output is the input added with the decayed echo\
audioFloatBuffer[i] = audioFloatBuffer[i] + echoBuffer[position] * decay;\
//store the sample in the buffer;\
echoBuffer[position] = audioFloatBuffer[i];\
//increment the echo buffer position\
position;\
//loop in the echo buffer\
if(position == echoBuffer.length)\
position = 0;\
```
To test the application, download and execute the “Delay.jar”:[Delay.jar] file and start singing in a microphone.
The source code of the Java implementation can be found on the TarsosDSP github page.
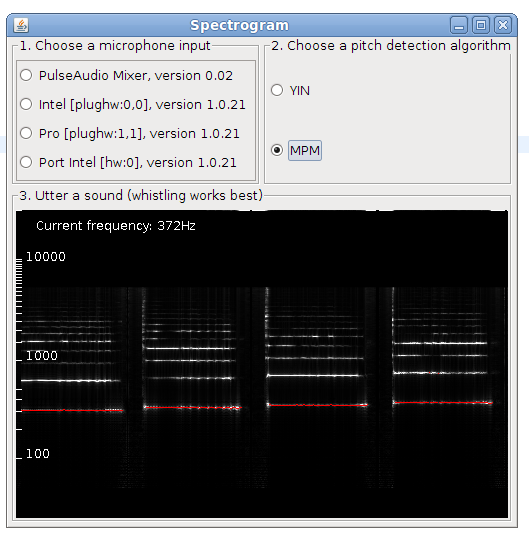
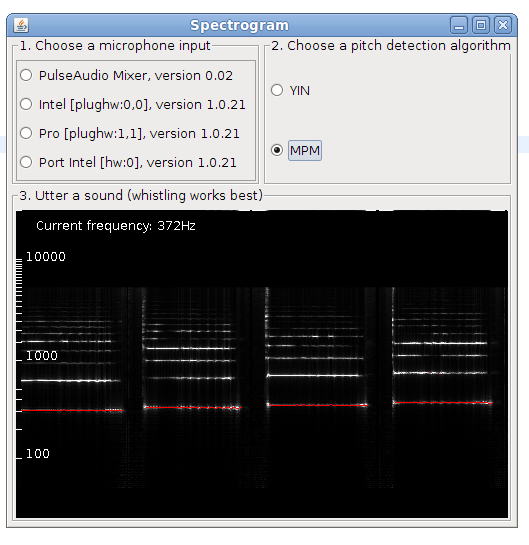
This is post presents a better version of the spectrogram implementation. Now it is included as an example in TarsosDSP, a small java audio processing library. The application show a live spectrogram, calculated using an FFT and the detected fundamental frequency (in red).
To test the application, download and execute the “Spectrogram.jar”:[Spectrogram.jar] file and start singing in a microphone.
There is also a command line interface, the following command shows the spectrum for in.wav:
\
java -jar Spectrogram.jar in.wav\
The source code of the Java implementation can be found on the TarsosDSP github page.
To test the application, download and execute the “WSOLA jar”:[TimeStretch.jar] file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command doubles the speed of in.wav:
\
java -jar TimeStretch.jar in.wav out.wav 2.0\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Time stretch utility.
----------------------------------------------------
Synopsis:
java -jar TimeStretch.jar source.wav target.wav factor
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the time stretched file.
factor Time stretching factor: 2.0 means double the length, 0.5 half. 1.0 is no change.
The source code of the Java implementation of WSOLA can be found on the TarsosDSP github page.
The DSP library of Tarsos, aptly named TarsosDSP, contains an implementation of a game that bares some resemblance to SingStar. It is called UtterAsterisk. It is meant to be a technical demonstration showing real-time pitch detection in pure java using a YIN -implementation.
“Download Utter Asterisk”:[UtterAsterisk.jar] and try to sing (utter) as close to the melody as possible. The souce code for Utter Asterisk is available on github.
The goal of the thesis was to develop an automatic transcription system for monophonic music. You can download the latest version of jAM - Java Automatic Music Transcription.
The DSP library of Tarsos, aptly named TarsosDSP, now contains an implementation of the Goertzel Algorithm. It is implemented using pure Java.
The Goertzel algorithm can be used to detect if one or more predefined frequencies are present in a signal and it does this very efficiently. One of the classic applications of the Goertzel algorithm is decoding the tones generated on by touch tone telephones. These use DTMF (Dual tone multi frequency)-signaling.
To make the algorithm visually appealing a Java Swing interface has been created(visible right). You can try this application by running the “Goertzel DTMF Jar-file”:[GoertzelDTMF.jar]. The souce code is included in the jar and is avaliable as a separate “zip file”:[GoertzelDTMF_src.zip]. The TarsosDSP github page also contains the source for the Goertzel algorithm Java implementation.
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method.
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in JAVA.
To make some of the possibilities clear I coded some examples.
“TarsosDSP UtterAsterisk”:[UtterAsterisk.jar] a game that shows real-time pitch detection with YIN.
“TarsosDSP Sound Detector”:[SoundDetector.jar] is simply to show how to react when (loud) sound is available.
“TarsosDSP Percussion Detector”:[PercussionDetector.jar] is capable of detecting percussion onsets using the method described here. It plays a sound from freesound.org when percussion is detected.
Saturday the 25th of March TarsosDSP was presented at Newline, a small conference organized by whitespace. Here you can download “the slides I used to present TarsosDSP”:[tarsosDSP_presentation.pdf], I also created “an introductory text on sound and Java”:[sound_and_java.pdf].







 TarsosDSP, the is a real-time audio processing library written in Java, is featured in
TarsosDSP, the is a real-time audio processing library written in Java, is featured in 

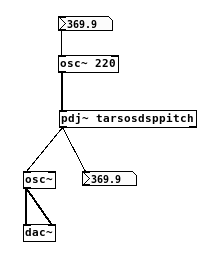 It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the
It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the  This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies.
This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies. The TarsosDSP Java library for audio processing now contains an implementation of the
The TarsosDSP Java library for audio processing now contains an implementation of the 







 </a>
</a>