I’ve just pushed some updates to mot — a command-line application for working with OSC and MIDI messages. My LLM tells me that these are exciting updates but I am not entirely sure that this is the case. Let me know if this ticks your box and seek professional help.
1. Scriptable MIDI Processor via Lua
I have implemented a MIDI processor that lets you transform, filter, and generate MIDI messages using Lua scripts.
Why is this useful? MIDI processors act as middlemen between your input devices and output destinations.You can do the following on incoming MIDI messages:
Filter - Block unwanted messages - channels - or select specific ranges
Route - Send different notes to different channel
Generate - Create complex patterns from simple input
The processor reads incoming MIDI from a physical device, processes it through your Lua script, and outputs the modified messages to a virtual MIDI port that your DAW or synth can receive. Some examples:
# Generate chords from single notes
mot midi_processor --script scripts/chord_generator.lua 06666# Transpose notes up by one octave
mot midi_processor --script scripts/example_processor.lua 06666
2. Network Discovery via mDNS
OSC receivers now advertise themselves on the network using mDNS/Bonjour with the _osc._udp service type.
This makes mot compatible with the EMI-kit — the Embodied Music Interface Kit developed at IPEM, Ghent University. OSC-enabled devices can automatically discover mot receivers on your network, eliminating manual configuration if the OSC sources add this functionality.
I have been asked to give a guest lecture introducing Music Information Retrieval for the course ‘Foundations of Musical Acoustics and Sonology’ at Ghent University. The lecture slides include interactive demos with live sound visualization and can be found below.
As we delve into the intricacies of how machines can analyze and understand musical content, students will gain insights into the cutting-edge research field that underpins modern music technology. From the algorithms powering music recommendation systems to the challenges of extracting meaningful information from audio signals, the lecture aims to ignite curiosity and inspire the next generation of musicologists in both music and technology. Get ready for an engaging session that promises to unlock the doors to a world where the science of sound meets the art of music.
Thanks to ChatGTP for the slightly over-the-top intro text above. Anyway, here you can find my introduction to Music Information Retrieval slides . Especially the interactive slides are perhaps of interest. The lecture was given in the Art-Science Interaction Lab (ASIL) which has a seven meter wide screen, which affects the slide design a bit.
Fig: Click the screenshot to go to the 'Introduction to Music Information Retrieval' slides.
Both Ghent University’s research output tracking system and Flanders FWO academic profile do not allow to enter software as research output. The focus is still solely on papers, even when custom developed research software has become a fundamental aspect in many research areas. My role is somewhere between that of a ‘pure’ researcher and that of a research software engineer which makes this focus on papers quite relevant to me.
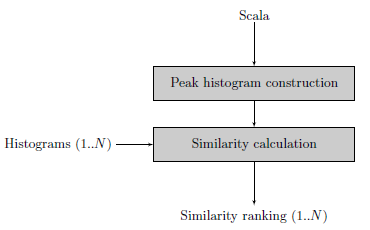
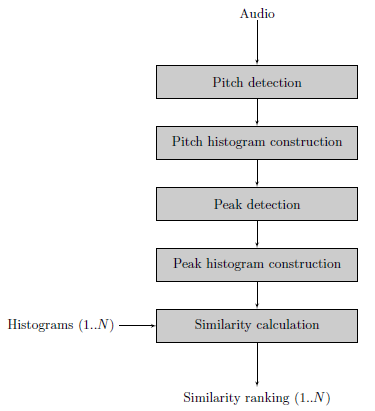
The paper aims to make the recent development on Olaf‘count’. Thanks to the JOSS review process the Olaf software was improved considerably: CI, unit tests, documentation, containerization,… The paper was a good reason to improve on all these areas which are all too easy to neglect. The paper itself is a short, rather general overview of Olaf:
“Olaf stands for Overly Lightweight Acoustic Fingerprinting and solves the problem of finding short audio fragments in large digital audio archives. The content-based audio search algorithm implemented in Olaf can identify a short audio query in a large database of thousands of hours of audio using an acoustic fingerprinting technique.”
This post details how I went about optimizing a C application. This is about an audio search system called Olaf which was made about 10 times faster but contains some generally applicable steps for optimizing C code or even other systems. Note that it is not the aim to provide a detailed how-to: I want to provide the reader with a more high-level understanding and enough keywords to find a good how-to for the specific tool you might want to use. I see a few general optimization steps:
The zeroth step of optimization is to properly **question the need** and balance the potential performance gains against added code complexity and maintainability.
Once ensured of the need, the first step is to **measure the systems performance**. Every optimization needs to be measured and compared with the original state, having automazation helps.
Thirdly, the second step is to **find performance bottle necks**, which should give you an idea where optimizations make sense.
The third step is to **implement and apply** an optimization and measuring its effect.
Lastly, **repeat** steps zero to three until optimization targets are reached.
More specifically, for the Olaf audio search system there is a need for optimization. Olaf indexes and searches through years of audio so a small speedup in indexing really adds up. So going for the next item on the list above: measure the performance. Olaf by default reports how quickly audio is indexed. It is expressed in the audio duration it can process in a single second: so if it reports 156 times realtime, it means that 156 seconds of audio can be indexed in a second.
The next step is to find performance bottlenecks. A profiler is a piece of software to find such bottle necks. There are many options gprof is a command line solution which is generally available. I am developing on macOS and have XCode available which includes the “Instruments - Time Profiler”. Whichever tool used, the result of a profiling session should yield the time it takes to run each functions. For Olaf it is very clear which function needs optimization:
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
The function is a max filter which is ran many, many times. The implementation is using a naive approach to max filtering. There are more efficient algorithms available. In this case looking into the literature and implementing a more efficient algorithm makes sense. A very practical paper by Lemire lists several contenders and the ‘van Herk’ algorithm hits the sweet spot between being easy to implement and needing only a tiny extra amount of memory. The Lemire paper even comes with example c max-filters. With only a slight change, the code fits in Olaf.
After implementing the change two checks need to be done: is the implementation correct and is it faster. Olaf comes with a number of functional and unit checks which provide some assurance of correctness and a built in performance indicator. Olaf improved from processing audio 156 times realtime to 583 times: a couple of times faster.
After running the profiler again, another method came up as the slowest:
//Naive implementationfloat olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
float max = -10000000;
for (size_t i = 0; i < array_size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
src: naive implementation of finding the max value of an array.
This is another part of the 2D max filter used in Olaf. Unfortunately here it is not easy to improve the algorithmic complexity: to find the maximum in a list, each value needs to be checked. It is however a good contender for SIMD optimization. With SIMD multiple data elements are processed in a single CPU instruction. With 32bit floats it can be possible to process 4 floats in a single step, potentially leading to a 4x speed increase - without including overhead by data loading.
Olaf targets microcontrollers which run an ARM instruction set. The SIMD version that makes most sense is the ARM Neon set of instructions. Apple Sillicon also provides support for ARM Neon which is a nice bonus. I asked ChatGPT to provide a ARM Neon improved version and it came up with the code below. Note that these type of simple functions are ideal for ChatGPT to generate since it is easily testable and there must be many similar functions in the ChatGPT training set. Also there are less ethical issues with ‘trivial’ functions: more involved code has a higher risk of plagiarization and improper attribution. The new average audio indexing speed is 832 times realtime.
src: a ARM Neon SIMD implementation of a function finding the max value of an array, generated by ChatGPT, licence unknown, informed consent unclear, correct attribution impossible.
Next, I asked ChatGPT for an SSE SIMD version targeting the x86 processors but this resulted in noticable slowdown. This might be related to the time it takes to load small vectors in SIMD registers. I did not pursue the SIMD SSE optimization since it is less relevant to Olaf and the first performance optimization was the most significant.
Finally, I went over the code again to see whether it would be possible exit a loop and simply skip calling olaf_ep_extractor_max_filter_time in most cases. I found a condition which prevents most of the calls without affecting the total results. This proved to be the most significant speedup: almost doubling the speed from about 800 times realtime to around 1500 times realtime. This is actually what I should have done before resorting to SIMD.
In the end Olaf was made about ten times faster with only two local, testable, targeted optimizations.
General takeways
Only think about optimization if there is a need and set a target: otherwise it is infinite.
Try to find a balance between complexity, maintainability and performance.
Changing a naive algorithm to a more intelligent one can have a significant performance increase. Check the literature for inspiration.
Check for conditions to skip hot code paths before trying fancy optimization techniques.
Profilers are crucial to identify where to optimize your code. Applying optimizations blindly is a waste of time.
Try to keep optimizations local and testable. Sprinkling your code with small, hard to test performance oriented improvements might not be worthwile.
SIMD generated by ChatGPT can be a very quick way to optimize critical, hot code paths. I would advise to only let ChatGPT generate small, common, easily testable code: e.g. finding the maximum in an array.
The NeXTcube is an influential machine in computing history. The NeXTcube, with an additional soundcard, was also one of the first off-the-shelf devices for high-quality, real-time music applications. I have restored a NeXTcube to run an early version of MAX, an environment for interactive music applications.
The NeXTcube context and the IRCAM Musical Workstation
In 1990 NeXT started selling the NeXTcube, a high-end workstation. It introduced or brought together many concepts (objective-c, the Mach kernel, postscript, an app store) which are still in use today. The NeXTcube’s influence is especially felt in the Apple ecosystem with Mac OS X, iPhones and iPads being direct decedents of NeXT’s line of computers.
Due to its high price, the NeXTcube was not a commercial success. It mainly ended up at companies or in the hands of researchers. Two of those researchers, Tim Berners-Lee and Robert Cailliau created the first http server and web browser at CERN on a NeXTcube. Coincidently, the http software was publicly released exactly 30 years ago today. Famously, the cube was also used to develop games like the original Doom and Quake. So yes, the NeXTcube runs Doom.
Fig: the NeXTcube's design stood out compared to the contemporary beige box PCs.
Less well known is the fact that the NeXTcube is also one of the first computing devices capable enough for real-time, high-quality interactive music applications. In the mid 1980s this was still a dream at IRCAM, a French research institute with the aim to ‘contribute to the renewal of musical expression through science and technology’. The bespoke hardware and software systems for music applications from the mid 80s were further developed and commercialised in the early 90s. Together these developments resulted in a commercially available version of the “IRCAM Musical Workstation (IMW)”, an early, if not the first, off-the-shelf computer for interactive music applications.
The IRCAM Musical Workstation (IMW), sometimes called the IRCAM Signal Processing Workstation (ISPW), consisted of several hard and software modules working together to enable interactive music applications. An important component was a ‘soundcard’ which had two beefy 40MHz i860 intel CPUs for DSP. When installed in the NeXTcube, the soundcard had more computing power than the rest of the computer. This is similar to modern computers where some graphics cards have more raw computing power than the main CPU. The soundcard was developed at IRCAM and commercialized by Ariel inc. under the name “Ariel ProPort”.
The IRCAM Ariel DSP coprocessor, soundcard.
A few software environments were developed at IRCAM which made use of the new hardware. One was Animal, another, was the much more influential MAX. MAX provides a graphical programming environment specific for music applications. Descendants of MAX are still used today, see Ableton Max for Live and Pure Data. I consider the introduction of MAX as a pivotal point in electronic music history. Up until the introduction of MAX, creating a new electronic music instrument meant bespoke hardware development. With MAX, this is done purely in software. This made electronic sound or instrument design not only faster but also accessible to a much wider audience of composers, artists and thinkerers.
The NeXTcube at IPEM
IPEM was an early electronic music production studio embedded at Ghent University, Belgium. Now it is active as a internationally acclaimed research center for interdisciplinary music research. In the early 90s IPEM acquired a NeXTcube Turbo with an internal diskette drive, SCSI hard disk, NextDimension color graphics card and an Ariel ProPort DSP/ISPW module. The cube was preserved well and came with many of the original software, books and manuals. I have been trying to get this machine working and configure it as an “IRCAM Musical Workstation”.
IPEM's NeXTcube with IRCAM Ariel ProPort.
There were a few practical issues: the mouse was broken, the hard drive unreliable and the main system fan loud and full of dust. The mouse had a broken cable which was fixed, the hard drive was replaced by a SCSI2SD setup and the fan was replaced with a new one. On the software side of things, the Internet Archive hosts NeXTStep 3.3 which, after many attempts, was installed on the cube. Unfortunately there seemed to be a compatibility issue. The Ariel ProPort kernel module did not work. I started over installed NeXTStep 3.1, with the same result. Finally, I installed NeXTStep 3.0 which was compatible with the kernel module and MAX/FTS!
Vid: Max/FTS with a commercial Ariel soundcard running on a NeXTcube Turbo.
The restoration of the IRCAM Signal Processing Workstation instruments fits in a university project on living heritage The idea is to get key historic electronic music instruments into the hands of researchers and artists to pull the fading knowledge on these devices back into a living culture of interaction. This idea already resulted in an album: DEEWEE Sessions vol. 01. Currently the collection includes a 1960s reverb plate, an EMS Synti 100 analog synthesizer from the 70s, a Yamaha DX7 (80s) and finally the NeXTCube/ISPW represents the early 90s and the departure of physical instruments to immaterial software based systems.
Acknowledgements & Further reading
This project was made possible with the support of the Belgian Music Instrument Museum and IPEM, Ghent University. I was fortunate to get assistance by Ivan Schepers and Marc Leman at IPEM but also by the main developers of MAX: Miller Puckette. I would also like to thank Anthony Agnello formerly at Ariel Corp for additional image material and info. I also found the WinWorld and NeXTComputers communities and resources extremely helpful. Below a picture from the CERN public archives and Ghent University Archive is included. Thanks a lot!
I have presented DiscStitch at the MIR (Music Information Retrieval) get together at the Deezer headquarters in Paris.
DiscStitch is a solution to identify, align and mix digitized audio originating from (overlapping) laquer discs. The main contribution lays in the novel audio to audio alignment algorithm which is robust against some speed differences and variabilities.
I have updated Olaf - the Overly Lightweight Acoustic Fingerprinting system. Olaf is a piece of technology that uses digital signal processing to identify audio files by analyzing unique, robust, and compact audio characteristics - or “fingerprints”. The fingerprints are stored in a database for efficient comparison and matching. The database index allows for fast and accurate audio recognition, even in the presence of distortions, noise, and other variations.
Olaf is unique because it works on traditional computing devices, embedded microprocessors and in the browser. To this end tried to use ANSI C. C is a relatively small programming language but has very little safeguards and is full of exiting footguns. I enjoy the limitations of C: limitations foster creativity. I also made ample use of the many footguns C has to offer: buffer overflows, memory leaks, … However, with the current update I think most serious bugs have been found. Some of the changes to Olaf include:
Fixed a rather nasty array out of bounds bug. The bug remained elusive due to the fact that a segfault was rare on macOS. Linux seems to be more diligent in that regard.
Added a quick way to skip already indexed files. Which improves usability significantly when working with larger datasets.
Improved command line output and fixed incorrectly reported times. The reported start and stop time of a query was wrong and is now fixed.
Olaf now supports caching fingerprints in simple text files. This makes fingerprint extraction much faster since all cores of the system can be used to extract fingerprints and dump them to text files. Writing prints to the database from multiple threads is slow since they need to wait for access to the locked database. There is also a command to store all cashed fingerprints in a single go.
Added support for basic profiling with gprof. The profiler shows where optimizations can have the most impact.
Olaf now includes an algorithm for efficient max-filtering. The min-max filter algorithm by Daniel Lemire is implemented. The profiler showed that most time was spend during max-filtering: replacing the naive max-filter with the Lemire max-filter improved performance drastically.
CI with Github Actions which checks if checked in sources compile and tests some of the basic functionality automatically.
Updated the Zig build script for cross-compilation and updated the pre-build Windows version.
Tested the system with larger databases. The FMA-full datasets, which comprises almost a full year of audio was indexed and queried without problems on a single pc. The limits of Olaf with respect to indexed size is probably a few times larger.
Tested, fixed and improved the ‘memory database’ version. Also added documentation to the readme.
Made a basic web example to call the WASM version of Olaf.
Added an ESP32 example, showing how Olaf can run on this microprocessor. It runs without an external microphone but uses a test audio file. Previously some small changes were needed to Olaf to run on the ESP32, now the exact same code is used.
Anyhow, what originally started as a rather quick and dirty hack has been improved quite a bit. The takeaway message: in the world of software it does seem possible to polish a turd.
TarsosDSP is a Java library for audio processing I have started working on more than 10 years ago. The aim of TarsosDSP is to provide an easy-to-use interface to practical music processing algorithms. Obviously, I have been using it myself over the years as my go-to library for audio-processing in Java. However, a number of gradual changes in the java ecosystem made TarsosDSP more and more difficult to use.
Since I have apparently not been the only one using it, there was a need to give it some attention. During the last couple of weeks I have found the time to give it this much needed attention. This resulted in a number of updates, some of the changes include:
Change of the build system from Apache Ant to Gradle
Make use of Java Modules to make TarsosDSP compatible with the ModulePath introduced in Java 9.
Packaged the software into a maven compatible format, which makes it easy to use as a dependency.
CI with GitHub actions to automatically build and test the software.
Updated some examples shipped with the TarsosDSP. I have still still some examples to verify.
Improved handling of errors on reading audio via ffmpeg
\
Fig: The updated TarsosDSP release contains many CLI and GUI example applications.
Notably the code of TarsosDSP has not changed much apart from some cosmetic changes. This backwards compatibility is one of the strong points of Java. With this update I am quite confident that TarsosDSP will also be usable during the next decade as well.
JNI is a way to use C or C code from Java and allows developers to reuse and integrate C/C in Java software. In contrast to the Java code, C/C code is platform dependent and needs to be compiled for each platform/architecture. Also it is generally not a good idea to make users compile a C/C library: it is best provide precompiled libraries. As a developer it is, however, a pain to provide binaries for each platform.
With the dominance of x86 processors receding the problem of having to compile software for many platforms is becoming more pressing. It is not unthinkable to want to support, for example, intel and M1 macOS, ARM and x86_64 Linux and Windows. To support these platforms you would either need access to such a machine with a compiler or configure a cross-compiler for each system: both are unpractical. Typically setting up a cross-compiler can be time consuming and finicky and virtual machines can be tough to setup. There is however an alternative.
Zig is a programming language but, thanks to its support for C/C, it also ships with an easy-to-use cross-compiler which is of interest here even if you have no intention to write a single line of Zig code. The built-in cross-compiler allows to target many platforms easily.
Cross compilation of C code is possible by simply replacing the gcc command with zig cc and adding a target argument, e.g. for targeting a Windows. There is more general information on zig as a cross-compiler here.
Cross-compiling a JNI library is not different to compiling other libraries. To make things concrete we will cross-compile a library from a typical JNI project: JGaborator packs the C/C library gaborator. In this case the C/C code does a computationally intensive spectral transformation of time domain data. The commands below create an x86_64 Windows DLL from a macOS with zig installed:
{style="overflow-x:scroll"}
<code>
bash
#wget https://aka.ms/download-jdk/microsoft-jdk-17.0.5-windows-x64.zip#unzip microsoft-jdk-17.0.5-windows-x64.zip#export JAVA_HOME=`pwd`/jdk-17.0.5+8/
git clone --depth 1https://github.com/JorenSix/JGaborator
cd JGaborator/gaborator
echo $JAVA_HOMEJNI_INCLUDES=-I"$JAVA_HOME/include"\ -I"$JAVA_HOME/include/win32"
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC pffft/pffft.c -o pffft/pffft.o
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC -DFFTPACK_DOUBLE_PRECISION pffft/fftpack.c -o pffft/fftpack.o
zig c++ -target x86_64-windows-gnu -I"pffft" -I"gaborator-1.7"$JNI_INCLUDES -O3\
-ffast-math -DGABORATOR_USE_PFFFT -o jgaborator.dll jgaborator.cc pffft/pffft.o pffft/fftpack.o
file jgaborator.dll
# jgaborator.dll: PE32+ executable (console) x86-64, for MS Windows
</code>
Note that, when cross-compiling from macOS, to target Windows a Windows JDK is needed. The windows JDK has other header files like jni.h. Some commands to download and use the JDK are commented out in the example above. Also note that targeting Linux from macOS seems to work with the standard macOS JDK. This is probably due to shared conventions regarding compilation of libraries.
To target other platforms, e.g. ARM Linux, there are only two things that need to be changed: the -target switch should be changed to aarch64-linux-gnu and the name of the output library should be (by Linux convention) changed to libjgaborator.so. During the build step of JGaborator a list of target platforms it iterated and a total of 9 builds are packaged into a single Jar file. There is also a bit of supporting code to load the correct version of the library.
Using a GitHub action or similar CI tools this cross compilation with zig can be automated to run on a software release. For Github the Setup Zig action is practical.
Loading the correct library
In a first attempt I tried to detect the operating system and architecture of the environment to then load the library but eventually decided against this approach. Mainly because you then need to keep an exhaustive list of supporting platforms and this is difficult, error prone and decidedly not future-proof.
In my second attempt I simply try to load each precompiled library limited to the sensible ones - only dll’s on windows - until a matching one is loaded. The rationale here is that the system itself knows best which library works and failing to load a library is computationally cheap. There is some code to iterate all precompiled libraries in a JAR-file so supporting an additional platform amounts to adding a precompiled library in the JAR folder: there is no need to be explicit in the Java code about architectures or OSes.
Trying multiple libraries has an additional advantage: this allows to ship multiple versions targeting the same architecture: e.g. one with additional acceleration libraries enabled and one without. By sorting the libraries alphabetically the first, then, should be the one with acceleration and the fallback without. In the case of JGaborator for mac aarch64 there is one compiled with -framework Accelerate and one compiled by the Zig cross-compiler without.
Takehome messages
If you find yourself cross-compiling C or C for many platforms, consider the Zig cross-compiler. Even when you have no intention to write a single line of Zig code.
For JNI and Java the JGaborator source code might offer some inspiration to pre-compile and load libraries for many platforms with little effort.
CI tools can help to verify builds and automate Zig cross-compilation.
If you build for Windows make sure to include windows header-files even when there are no compilation errors using UNIX-header files.
This year the ISMIR 2022 conference is organized from 4 to 9 December 2022 in Bengaluru, India. ISMIR is the main music technology and music information retrieval (MIR) conference. It is a relief to experience a conference in physical form and not through a screen.
I have contributed to the following work which is in the main paper track of ISMIR 2022:
BAF: An Audio Fingerprinting Dataset For Broadcast Monitoring (version of record)\
Guillem Cortès, Alex Ciurana, Emilio Molina, Marius Miron, Owen Meyers, Joren Six, Xavier Serra\
Abstract: Audio Fingerprinting (AFP) is a well-studied problem in music information retrieval for various use-cases e.g. content-based copy detection, DJ-set monitoring, and music excerpt identification. However, AFP for continuous broadcast monitoring (e.g. for TV & Radio), where music is often in the background, has not received much attention despite its importance to the music industry. In this paper (1) we present BAF, the first public dataset for music monitoring in broadcast. It contains 74 hours of production music from Epidemic Sound and 57 hours of TV audio recordings. Furthermore, BAF provides cross-annotations with exact matching timestamps between Epidemic tracks and TV recordings. Approximately, 80% of the total annotated time is background music. (2) We benchmark BAF with public state-of-the-art AFP systems, together with our proposed baseline PeakFP: a simple, non-scalable AFP algorithm based on spectral peak matching. In this benchmark, none of the algorithms obtain a F1-score above 47%, pointing out that further research is needed to reach the AFP performance levels in other studied use cases. The dataset, baseline, and benchmark framework are open and available for research.
I have also presented a first version of DiscStitch, an audio-to-audio alignment algorithm. This contribution is in the ISMIR 2022 late breaking demo session:
DiscStitch: towards audio-to-audio alignment with robustness to playback speed variabilities (version of record)\
Joren Six\
Abstract: Before magnetic tape recording was common, acetate discs were the main audio storage medium for radio broadcasters. Acetate discs only had a capacity to record about ten minutes. Longer material was recorded on overlapping discs using (at least) two recorders. Unfortunately, the recorders used were not reliable in terms of recording speed, resulting in audio of variable speed. To make digitized audio originating from acetate discs fit for reuse, (1) overlapping parts need to be identified, (2) a precise alignment needs to be found and (3) a mixing point suggested. All three steps are challenging due to the audio speed variabilities. This paper introduces the ideas behind DiscStitch: which aims to reassemble audio from overlapping parts, even if variable speed is present. The main contribution is a fast and precise audio alignment strategy based on spectral peaks. The method is evaluated on a synthetic data set.
Next to my own contributions, the ISMIR conference program is the best overview of the state-of-the art of MIR.
This contribution was made possible thanks to travel funds by the FWO travel grant K1D2222N and the Ghent University BOF funded project PaPiOM.
I have just released a new version of SyncSink. SyncSink is a tool to synchronize media files with shared audio. It is ideal to synchronize video captured by multiple cameras or audio captured by many microphones. It finds a rough alignment between audio captured from the same event and subsequently refines that offset with a crosscorrelation step. Below you can see SyncSink in action or you can try out SyncSink (you will need ffmpeg and Java installed on your system).
SyncSink used to be part of the Panako acoustic fingerprinting system but I decided that it was better to keep the Panako package focused and made a separate repository for SyncSink. More information can be found at the SyncSink GiHub repo
SyncSink is a tool to synchronize media files with shared audio. SyncSink matches and aligns shared audio and determines offsets in seconds. With these precise offsets it becomes trivial to sync files. SyncSink is, for example, used to synchronize video files: when you have many video captures of the same event, the audio attached to these video captures is used to align and sync multiple (independently operated) cameras.
Evidently, SyncSink can also synchronize audio captured from many (independent) microphones if some environmental sound is shared (leaked in) the each recording.
I am currently in Birmingham, UK at the 2019 at the joint Analytical Approaches to World Music (AAWM) and Folk Music Conference (FMA). The opening concert by the RBC folk ensemble already provided the most lively and enthusiastic conference opening probably ever. Especially considering the early morning hour (9.30). At the conference, two studies will be presented on which I collaborated:
Automatic comparison of human music, speech, and bird song suggests uniqueness of human scales
“Automatic comparison of human music, speech, and bird song suggests uniqueness of human scales”:[FMA2019_paper_12.pdf] by Jiei Kuroyanagi, Shoichiro Sato, Meng-Jou Ho, Gakuto Chiba, Joren Six, Peter Pfordresher, Adam Tierney, Shinya Fujii and Patrick Savage
The uniqueness of human music relative to speech and animal song has been extensively debated, but rarely directly measured. We applied an automated scale analysis algorithm to a sample of 86 recordings of human music, human speech, and bird songs from around the world. We found that human music throughout the world uniquely emphasized scales with small-integer frequency ratios, particularly a perfect 5th (3:2 ratio), while human speech and bird song showed no clear evidence of consistent scale-like tunings. We speculate that the uniquely human tendency toward scales with small-integer ratios may relate to the evolution of synchronized group performance among humans.
Automatic comparison of global children’s and adult songs
“Automatic comparison of global children’s and adult songs”:[FMA2019_paper_13.pdf] by Shoichiro Sato, Joren Six, Peter Pfordresher, Shinya Fujii and Patrick Savage
Music throughout the world varies greatly, yet some musical features like scale structure display striking crosscultural similarities. Are there musical laws or biological constraints that underlie this diversity? The “vocal mistuning” hypothesis proposes that cross-cultural regularities in musical scales arise from imprecision in vocal tuning, while the integer-ratio hypothesis proposes that they arise from perceptual principles based on psychoacoustic consonance. In order to test these hypotheses, we conducted automatic comparative analysis of 100 children’s and adult songs from throughout the world. We found that children’s songs tend to have narrower melodic range, fewer scale degrees, and less precise intonation than adult songs, consistent with motor limitations due to their earlier developmental stage. On the other hand, adult and children’s songs share some common tuning intervals at small-integer ratios, particularly the perfect 5th (\~3:2 ratio). These results suggest that some widespread aspects of musical scales may be caused by motor constraints, but also suggest that perceptual preferences for simple integer ratios might contribute to cross-cultural regularities in scale structure. We propose a “sensorimotor hypothesis” to unify these competing theories.
Thanks to the support of a travel grant by the faculty of Arts and Philosophy of Ghent University I was able to attend the ISMIR 2018 conference. A conference on Music Information Retrieval. I am co author on a contribution for the the Late-Breaking / Demos session
The structure of musical scales has been proposed to reflect universal acoustic principles based on simple integer ratios. However, some studying tuning in small samples of non-Western cultures have argued that such ratios are not universal but specific to Western music. To address this debate, we applied an algorithm that could automatically analyze and cross-culturally compare scale tunings to a global sample of 50 music recordings, including both instrumental and vocal pieces. Although we found great cross-cultural diversity in most scale degrees, these preliminary results also suggest a strong tendency to include the simplest possible integer ratio within the octave (perfect fifth, 3:2 ratio, \~700 cents) in both Western and non-Western cultures. This suggests that cultural diversity in musical scales is not without limit, but is constrained by universal psycho-acoustic principles that may shed light on the evolution of human music.
Claims made in many Music Information Retrieval (MIR) publications are hard to verify due to the fact that (i) often only a textual description is made available and code remains unpublished – leaving many implementation issues uncovered; (ii) copyrights on music limit the sharing of datasets; and (iii) incentives to put effort into reproducible research – publishing and documenting code and specifics on data – is lacking. In this article the problems around reproducibility are illustrated by replicating an MIR work. The system and evaluation described in ‘A Highly Robust Audio Fingerprinting System’ is replicated as closely as possible. The replication is done with several goals in mind: to describe difficulties in replicating the work and subsequently reflect on guidelines around reproducible research. Added contributions are the verification of the reported work, a publicly available implementation and an evaluation method that is reproducible.
This weekend the University Hamburg - Institute for Systematic Musicology and more specifically Christian D. Koehn organized the International Symposium on Computational Ethnomusicological Archiving. The symposium featured a broad selection of research topics (physical modelling of instruments, MIR research, 3D scanning techniques, technology for (re)spacialisation of music, library sciences) which all had a relation with archiving musics of the world:
How could existing digital technologies in the field of music information retrieval, artificial intelligence, and data networking be efficiently implemented with regard to digital music archives? How might current and future developments in these fields benefit researchers in ethnomusicology? How can analytical data about musical sound and descriptive data about musical culture be more comprehensively integrated?
I was able to attend the symposium and contributed with a talk titled “Challenges and opportunities for computational analysis of wax cylinders”:[2017.12.Hamburg-Wax-presentation.pdf] and by chairing a panel discussion. The symposium was kindly sponsored by the VolkswagenStiftung. The talk had the following abstract:
In this presentation we describe our experience of working with computational analysis on digitized wax cylinder recordings. The audio quality of these recordings is limited which poses challenges for standard MIR tools. Unclear recording and playback speeds further hinder some types of audio analysis. Moreover, due to a lack of systematical meta-data notation it is often uncertain where a single recording originates or when exactly it was recorded. However, being the oldest available sound recordings, they are invaluable witnesses of various musical practices and they are opportunities to improve the understanding of these practices. Next to sketching these general concerns, we present results of the analysis of pitch content of 400 wax cylinder recordings from Indiana University (USA) and from the Royal Museum from Central Africa (Belgium). The scales of the 400 recordings are mapped and analyzed as a set. It is found that the fifth is almost always present and that scales with four and five pitch classes are organized similarly and differ from those with six and seven pitch classes, latter center around intervals of 170 cents, and former around 240 cents.
I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).
By Reinier de Valk (DANS), Anja Volk (Utrecht University), Andre Holzapfel (KTH Royal Institute of Technology) , Aggelos Pikrakis (University of Piraeus), Nadine Kroher (University of Seville - IMUS) and Joren Six (Ghent University - IPEM). Next to the version of record there is also an author version available of the contribution titled “MIRchiving: Challenges and opportunities of connecting MIR research and digital music archives”:[2017.DLfM.MIRchiving-author.pdf].
This study is a call for action for the music information retrieval (MIR) community to pay more attention to collaboration with digital music archives. The study, which resulted from an interdisciplinary workshop and subsequent discussion, matches the demand for MIR technologies from various archives with what is already supplied by the MIR community. We conclude that the expressed demands can only be served sustainably through closer collaborations. Whereas MIR systems are described in scientific publications, usable implementations are often absent. If there is a runnable system, user documentation is often sparse—-posing a huge hurdle for archivists to employ it. This study sheds light on the current limitations and opportunities of MIR research in the context of music archives by means of examples, and highlights available tools. As a basic guideline for collaboration, we propose to interpret MIR research as part of a value chain. We identify the following benefits of collaboration between MIR researchers and music archives: new perspectives for content access in archives, more diverse evaluation data and methods, and a more application-oriented MIR research workflow.
By Federica Bressan, Joren Six and Marc Leman (Ghent University - IPEM). Next to the version of record there is also an author version available of the contribution titled “Applications of duplicate detection: linking meta-data and merging music archives: The experience of the IPEM historical archive of electronic music”:[2017.dlfm_duplicates-author.pdf].
This work focuses on applications of duplicate detection for managing digital music archives. It aims to make this mature music information retrieval (MIR) technology better known to archivists and provide clear suggestions on how this technology can be used in practice. More specifically applications are discussed to complement meta-data, to link or merge digital music archives, to improve listening experiences and to re-use segmentation data. The IPEM archive, a digitized music archive containing early electronic music, provides a case study.
The 2017 AES international conference on semantic audio was organized at ISS Fraunhofer, Erlangen, Germany. As the birthplace of the MP3 codec, it is holy ground, a stop that can not be skipped on the itinerary of an audio engineers pilgrimage of life. At the conference I presented “ A framework to provide fine-grained time-dependent context for active listening experiences”:[2017.author.aes.pdf] with a poster (“pdf”:[aes_2017_poster.pdf], “inkscape svg”:[aes_2017_poster_2.svg]).
The “active listening demo movie”:[active_listening_demo_movie.mp4] above should explain the aim system succinctly. It shows two different ways to provide ‘context’ to audio playing in the room. In the first instance beats information is used to synchronize smartphones and flash the screen, the second demo shows a tactile feedback device responding to beats. The device is a soundbrenner pulse tactile metronome and was kindly sponsored by the company that sells these.
The article titled “Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment” by Joren Six and Marc Leman has been accepted for publication in the Journal on Multimodal User Interfaces. The article will be published later this year. It describes and tests a method to synchronize data-streams. Below you can find the abstract, pointers to the software under discussion and an author version of the article itself.
Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment An Application of Acoustic Fingerprinting to Facilitate Music Interaction Research
Abstract:Research on the interaction between movement and music often involves analysis of multi-track audio, video streams and sensor data. To facilitate such research a framework is presented here that allows synchronization of multimodal data. A low cost approach is proposed to synchronize streams by embedding ambient audio into each data-stream. This effectively reduces the synchronization problem to audio-to-audio alignment. As a part of the framework a robust, computationally efficient audio-to-audio alignment algorithm is presented for reliable synchronization of embedded audio streams of varying quality. The algorithm uses audio fingerprinting techniques to measure offsets. It also identifies drift and dropped samples, which makes it possible to find a synchronization solution under such circumstances as well. The framework is evaluated with synthetic signals and a case study, showing millisecond accurate synchronization.
The algorithm under discussion is included in Panako an audio fingerprinting system but is also available for download here. The SyncSink application has been packaged separately for ease of use.
To use the application start it with double click the downloaded SyncSink JAR-file. Subsequently add various audio or video files using drag and drop. If the same audio is found in the various media files a time-box plot appears, as in the screenshot below. To add corresponding data-files click one of the boxes on the timeline and choose a data file that is synchronized with the audio. The data-file should be a CSV-file. The separator should be ‘,’ and the first column should contain a time-stamp in fractional seconds. After pressing Sync a new CSV-file is created with the first column containing correctly shifted time stamps. If this is done for multiple files, a synchronized sensor-stream is created. Also, ffmpeg commands to synchronize the media files themselves are printed to the command line.
This work was supported by funding by a Methusalem grant from the Flemish Government, Belgium. Special thanks goes to Ivan Schepers for building the balance boards used in the case study. If you want to cite the article, use the following BiBTeX:
@article{six2015multimodal,
author = {Joren Six and Marc Leman},
title = {{Synchronizing Multimodal Recordings Using Audio-To-Audio Alignment}},
issn = {1783-7677},
volume = {9},
number = {3},
pages = {223-229},
doi = {10.1007/s12193-015-0196-1},
journal = {{Journal of Multimodal User Interfaces}},
publisher = {Springer Berlin Heidelberg},
year = 2015
}
A microcontroller fitted with an electret microphone and a microSD card slot. It can record audio in real-time together with sensor data.
Conceptual drawing used as a basis for the SyncSync application. A reference stream (blue) can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).
SyncSink Synchronize media files. A user-friendly interface to synchronize media and data files. First a reference media-file is added using drag-and-drop. The audio steam of the reference is extracted and plotted on a timeline as the topmost box. Subsequently other media-files are added. The offsets with respect to the reference are calculated and plotted. CSV-files with timestamps and data recorded in sync with a stream can be attached to a respective audio stream. Finally, after pressing Sync!, the data and media files are modified to be exactly in sync with the reference.
Multimodal recording system diagram. Each webcam has a microphone and is connected to the pc via USB. The dashed arrows represent analog signals. The balance board has four analog sensors but these are simplified to one connection in the schematic. The analog output of the microphones is also recorded through the DAQ. An analog accelerometer is connected with a microcontroller which also records audio.
Two streams of audio with fingerprints marked. Some fingerprints are present in both streams (green, O) while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.
Synchronized streams in Sonic Visualizer. Here you can see two channel audio synchronized with accelerometer data (top, green) and balanceboard data (bottom, purple).
The synchronized data from the two webcams, accelerometer and balanceboard in ELAN. From top to bottom the synchronized streams are two video-streams, balance-board data (red), accelerometer-data (green) and audio (black).
The 27th of November, 2014 a lecture on audio fingerprinting and its applications for digital musicology will be given at IPEM. The lecture introduces audio fingerprinting, explains an audio fingerprinting technique and then goes on to explain how such algorithm offers opportunities for large scale digital musicological applications. Here you can download the slides about audio fingerprinting and its opportunities for digital musicology.
With the explained audio fingerprinting technique a specific form of very reliable musical structure analysis can be done. Below, in the figure section, an example of repetitive structure in the song Ribs Out is shown. Another example is comparing edits or versions of songs. Below, also in the figure section, the radio edit of Daft Punk’s Get Lucky is compared with the original version. Audio synchronization using fingerprinting is another application that is actively used in the field of digital musicology to align audio with extracted features.
Since acoustic fingerprinting makes structure analysis very efficiently it can be applied on a large scale (20k songs). The figure below shows that identical repetition is something that has been used more and more since the mid 1970’s. The trend probably aligns with the amount of technical knowledge needed to ‘copy and paste’ a snippet of music.
\
Fig: How much identical repetition is used in music, over the years.
At ISMIR 2014 i will present a paper on a fingerprinting system. ISMIR is the annual conference of the International Society for Music Information Retrieval is the world’s leading interdisciplinary forum on accessing, analyzing, and organizing digital music of all sorts. This years instalment takes place in Taipei, Taiwan. My contribution is a paper titled Panako - A Scalable Acoustic Fingerprinting System Handling Time-Scale and Pitch Modification, it will be presented during a poster session the 27th of October.
This paper presents a scalable granular acoustic fingerprinting system. An acoustic fingerprinting system uses condensed representation of audio signals, acoustic fingerprints, to identify short audio fragments in large audio databases. A robust fingerprinting system generates similar fingerprints for perceptually similar audio signals. The system presented here is designed to handle time-scale and pitch modifications. The open source implementation of the system is called Panako and is evaluated on commodity hardware using a freely available reference database with fingerprints of over 30,000 songs. The results show that the system responds quickly and reliably on queries, while handling time-scale and pitch modifications of up to ten percent.
The system is also shown to handle GSM-compression, several audio effects and band-pass filtering. After a query, the system returns the start time in the reference audio and how much the query has been pitch-shifted or time-stretched with respect to the reference audio. The design of the system that offers this combination of features is the main contribution of this paper.
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a Constant-Q Transform (as of version 1.6). The Constant-Q transform does essentially the same thing as an FFT, but has the advantage that each octave has the same amount of bins. This makes the Constant-Q transform practical for applications processing music. If, for example, 12 bins per octave are chosen, these can correspond with the western musical scale.
Also included in the newest release (version 1.7) is a way to visualize the transform, or other musical features. The visualization implementation is done together with Thomas Stubbe.
The example application below shows the Constant-Q transform with an overlay of pitch estimations. The corresponding waveform is also shown.
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of the Journal of New Music Research (JNMR) on the 20th of august 2013. Below you can find the abstract for the article, and pointers to audio examples, the Tarsos software, and the author version of the article itself.
Abstract: This paper presents Tarsos, a modular software platform used to extract and analyze pitch organization in music. With Tarsos pitch estimations are generated from an audio signal and those estimations are processed in order to form musicologically meaningful representations. Tarsos aims to offer a flexible system for pitch analysis through the combination of an interactive user interface, several pitch estimation algorithms, filtering options, immediate auditory feedback and data output modalities for every step. To study the most frequently used pitches, a fine-grained histogram that allows up to 1200 values per octave is constructed. This allows Tarsos to analyze deviations in Western music, or to analyze specific tone scales that differ from the 12 tone equal temperament, common in many non-Western musics. Tarsos has a graphical user interface or can be launched using an API - as a batch script. Therefore, it is fit for both the analysis of individual songs and the analysis of large music corpora. The interface allows several visual representations, and can indicate the scale of the piece under analysis. The extracted scale can be used immediately to tune a MIDI keyboard that can be played in the discovered scale. These features make Tarsos an interesting tool that can be used for musicological analysis, teaching and even artistic productions.
Ladrang Kandamanyura (slendro pathet manyura), is the name of the piece used in the article throughout section 2. The album on which the piece can be found is available at wergo. Below a thirty second fragment is embedded. You can also “download”:[08._Ladrang_Kandamanyura_10s-20s_up.wav] the thirty second fragment to analyse it yourself.
Below the BibTex entry for the article is embedded.
```ruby\
\@article{six2013tarsos_jnmr,\
author = {Six, Joren and Cornelis, Olmo and Leman, Marc},\
title = {Tarsos, a Modular Platform for Precise Pitch Analysis\
of Western and Non-Western Music},\
journal = {Journal of New Music Research},\
volume = {42},\
number = {2},\
pages = {113-129},\
year = {2013},\
doi = {10.1080/09298215.2013.797999},\
URL = {http://www.tandfonline.com/doi/abs/10.1080/09298215.2013.797999}\
}\
```
Today marks the reslease of Tarsos 1.0 . The new Tarsos release contains practical transcription features. As can be seen in the screenshot below, a time stretching feature makes it easy to loop a certain audio fragment while it is playing in a slow tempo. The next loop can be played with by pressing the n key, the one before by pressing b.
Since the pitch classes can be found in a song, and there is a feature that lets you play a MIDI keyboard in the tone scale of the song under analysis, transcription of ethnic music is made a lot easier.
The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The ISMIR 2012 is described as follows:
The annual Conference of the International Society for Music Information Retrieval (ISMIR) is the world’s leading research forum on processing, searching, organizing and accessing music-related data. The revolution in music distribution and storage brought about by digital technology has fueled tremendous research activities and interests in academia as well as in industry. The ISMIR Conference reflects this rapid development by providing a meeting place for the discussion of MIR-related research, developments, methods, tools and experimental results. Its main goal is to foster multidisciplinary exchange by bringing together researchers and developers, educators and librarians, as well as students and professional users.
Tutorials
I saw an interesting tutorial on Jazz music and a tutorial on source separation. After an introduction, which detailed the experimental basis of the system, a source separator was introduced. The REPET source separator is a relatively simple system that yields reasonable results to split accompaniment from foreground melody.
The ongoing work by Ceril Bohak and Matija Marolt on segmentation of folk music could be very useful to apply on Afican musics. The paper is called Finding Repeating Stanzas in Folk Songs.
What follows is about the Conference on Interdisciplinary Musicology (CIM2012) and the 15th international Conference of the Gesellschaft fur Musikfoschung. First this text will give information about our contribution to CIM2012: Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means and then a number of highlights of the conference follow. The joint conference took place from the 4th to the 8th of september 2012.
In 2012, CIM will tackle the subject of History. Hosted by the University of Göttingen, whose one time music director Johann Nikolaus Forkel is widely regarded as one of the founders of modern music historiography, CIM12 aims to promote collaborations that provoke and explore new methods and methodologies for establishing, evaluating, preserving and communicating knowledge of music and musical practices of past societies and the factors implicated in both the preservation and transformation of such practices over time.
### Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means
Our contribution ton CIM 2012 is titled “Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means”:[CIM12_Submission.pdf]. The aim was to show how tone scales of the past, e.g. organ tuning, can be extracted and sonified. During the demo special attention was given to historic Central African tuning systems. The presentation I gave is included below and or available for “download”:[2012.09.05-Revealing_and_listening_to_scales_from_the_past__tone_scale_analysis_of_archived_Central-African_music_using_computational_means..ppt]
The work presented by Rytis Ambrazevicius et al. Modal changes in traditional Lithuanian singing: Diachronic aspect has a lot in common with our research, it was interesting to see their approach. Another highlight of the conference was the whole session organized by Klaus-Peter Brenner around Mbira music.
Rainer Polak gave a talk titled ‘Swing, Groove and Metre. Asymmetric Feels, Metric Ambiguity and Metric Transformation in African Musics’. He showed how research about rhythm in jazz research, music theory and empirical musicology ( amongst others) could be bridged and applied to ethnic music.
The overview Eleanore Selfridge-Field gave during her talk Between an Analogue Past and a Digital Future: The Evolving Digital Present was refreshing. She had a really clear view on all the different ways musicology and digital media can benifit from each-other.
From the concert programme I found two especially interesting: the lecture-performance by Margarete Maierhofer-Lischka and Frauke Aulbert of Lotofagos, a piece by Beat Furrer and Burdocks composed and performed by Christian Wolff and a bunch of enthusiastic students.
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
Tarsos contains a couple of useful command line applications. They can be used to execute common tasks on lots of files. Dowload Tarsos and call the applications using the following format:
The first part java -jar tarsos.jar tells the Java Runtime to start the correct application. The first argument for Tarsos defines the command line application to execute. Depending on the command, required arguments and options can follow.
To get a list of available commands, type java -jar tarsos.jar -h. If you want more information about a command type java -jar tarsos.jar command -h
Detect Pitch
Detects pitch for one or more input audio files using a pitch detector. If a directory is given it traverses the directory recursively. It writes CSV data to standard out with five columns. The first is the start of the analyzed window (seconds), the second the estimated pitch, the third the saillence of the pitch. The name of the algorithm follows and the last column shows the original filename.
Friday the second of December I presented a talk about software for music analysis. The aim was to make clear which type of research topics can benefit from measurements by software for music analysis. Different types of digital music representations and examples of software packages were explained.
Following presentation was used during the talk. (“ppt”:[2011.12.02.software_for_music_analysis.ppt], “odp”:[2011.12.02.software_for_music_analysis.odp]):
Sonic Visualizer: As its name suggests Sonic Visualizer contains a lot different visualisations for audio. It can be used for analysis (pitch,beat,chroma,…) with VAMP-plugins. To quote “The aim of Sonic Visualiser is to be the first program you reach for when want to study a musical recording rather than simply listen to it”. It is the swiss army knife of audio analysis.
BeatRoot is designed specifically for one goal: beat tracking. It can be used for e.g. comparing tempi of different performances of the same piece or to track tempo deviation within one piece.
Tartini is capable to do real-time pitch analysis of sound. You can e.g. play into a microphone with a violin and see the harmonics you produce and adapt you playing style based on visual feedback. It also contains a pitch deviation measuring apparatus to analyse vibrato.
Tarsos is software for tone scale analysis. It is useful to extract tone scales from audio. Different tuning systems can be seen, extracted and compared. It also contains the ability to play along with the original song with a tuned midi keyboard .
To show the different digital representations of music one example (Liebestraum 3 by Liszt) was used in different formats:
The aim of acoustic fingerprinting is to generate a small representation of an audio signal that can be used to identify or recognize similar audio samples in a large audio set. A robust fingerprint generates similar fingerprints for perceptually similar audio signals. A piece of music with a bit of noise added should generate an almost identical fingerprint as the original. The use cases for audio fingerprinting or acoustic fingerprinting are myriad: detection of duplicates, identifying songs, recognizing copyrighted material,…
Using a pitch class histogram as a fingerprint seems like a good idea: it is unique for a song and it is reasonably robust to changes of the underlying audio (length, tempo, pitch, noise). The idea has probably been found a couple of times independently, but there is also a reference to it in the literature, by Tzanetakis, 2003: Pitch Histograms in Audio and Symbolic Music Information Retrieval:
Although mainly designed for genre classification it is possible that features derived from Pitch Histograms might also be applicable to the problem of content-based audio identification or audio fingerprinting (for an example of such a system see (Allamanche et al., 2001)). We are planning to explore this possibility in the future.
Unfortunately they never, as far as I know, did explore this possibility, and I also do not know if anybody else did. I found it worthwhile to implement a fingerprinting scheme on top of the Tarsos software foundation. Most elements are already available in the Tarsos API: a way to detect pitch, construct a pitch class histogram, correlate pitch class histograms with a pitch shift,… I created a GUI application which is presented here. It is, probably, the first open source acoustic / “audio fingerprinting system based on pitch class histograms”:[AudioFingerprinter.jar].
It works using drag and drop and the idea is to find a needle (an audio file) in a hay stack (a large amount of audio files). For every audio file in the haystack and for the needle pitch is detected using an optimized, for speed, Yin implementation. A pitch class histogram is created for each file, the histogram for the needle is compared with each histogram in the hay stack and, hopefully, the needle is found in the hay stack.
Unfortunately I do not have time for rigorous testing (by building a large acoustic fingerprinting data set, or an other decent test bench) but the idea seems to work. With the following modifications, done with audacity effects the needle was still found a hay stack of 836 files :
A 10% speedup
15 and 30 seconds removed form the needle (a song of 4 minutes 12 seconds)
White noise added
Reversed the audio (This is, I believe, a rather unique property of this fingerprinting technique)
GSM reencoded
The following modifications failed to identify the correct song:
A one semitone pitch shift
A two semitone pitch shift
60 seconds removed from the needle
The original was also found. No failure analysis was done. The hay stack consists of about 100 hours of western pop, the needle is also a western pop song. If somebody wants to pick up this work or has an acoustic fingerprinting data set or drop me a line at
The live demo we gave went well and we got a lot of positive, interesting feedback. The presentation about Tarsos is available here.
It was the first time in the history of ISMIR that there was a session with oral presentations about Non-Western Music. We were pleased to be part of this.
The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the Late Breaking and Demo Session) or read the paper: “Peachnote Piano: Making MIDI instruments social and smart using Arduino, Android and Node.js”:[PeachNote_Piano_ISMIR_Demo.pdf]. What follows here is the introduction of the extended abstract:
Playing music instruments can bring a lot of joy and satisfaction, but not all apsects of music practice are always enjoyable. In this contribution we are addressing two such sometimes unwelcome aspects: the solitude of practicing and the "dumbness" of instruments.
The process of practicing and mastering of music instruments often takes place behind closed doors. A student of piano spends most of her time alone with the piano. Sounds of her playing get lost, and she can't always get feedback from friends, teachers, or, most importantly, random Internet users. Analysing her practicing sessions is also not easy. The technical possibility to record herself and put the recordings online is there, but the needed effort is relatively high, and so one does it only occasionally, if at all.
Instruments themselves usually do not exhibit any signs of intelligence. They are practically mechanic devices, even when implemented digitally. Usually they react only to direct actions of a player, and the player is solely responsible for the music coming out of the insturment and its quality. There is no middle ground between passive listening to music recordings and active music making for someone who is alone with an instrument.
We have built a prototype of a system that strives to offer a practical solution to the above problems for digital pianos. From ground up, we have built a system which is capable of transmitting MIDI data from a MIDI instrument to a web service and back, exposing it in real-time to the world and optionally enriching it.
A previous post about PeachNote Piano has more technical details together with a video showing the core functionality (quasi-instantaneous USB-BlueTooth-MIDI communication). Some photos can be found below.
This article describes how to do makam recognition with a script that uses the Tarsos API.
The task we want to do is to find the tone scales most similar to the one used in recorded music. To complete this task you need a small set of theoretical scales and a large set of music, each brought in one of the scales. To make it more concrete, an example of Turkish classical music is used.
In an article by Bozkurt pitch histograms are used for - amongst other tasks - makam recognition. A maqam defines rules for a composition or performance of classical Turkish music. It specifies melodic shapes and pitch intervals, the scale. The task is to identify which of nine makams is used in a specific song. A simplified, generalized implementation of this task is shown here. In our implementation there is no tonic detection step. Also here we use only theoretical descriptions of the tone scales as a template and do not construct a template using the audio itself, as is done by Bozkurt. Ioannidis Leonidas wrote an interesting master thesis about makam recognition. Since no knowledge of the music itself is used the approach is generally applicable.
The following is an implementation in Scala a general purpose programming language that is interoperable with Jave . The first step is to write the Scala header. This is just some boilerplate code to be able to run the script from the command line - it assumes a UNIX-like environment and tarsos.jar in the same directory:
The second step constructs the templates the capability of Tarsos to create\
theoretical tone scale templates using Gaussian kernels is used, line 8. See the attached images for some examples.
```ruby\
val makams = List( “hicaz”,”huseyni”,”huzzam”,”kurdili_hicazar”,\
“nihavend”,”rast”,”saba”,”segah”,”ussak”)
var theoreticKDEs = Map[java.lang.String,KernelDensityEstimate]()\
makams.foreach{ makam =>\
val scalaFile = makam + “.scl”\
val scalaObject = new ScalaFile(scalaFile);\
val kde = HistogramFactory.createPichClassKDE(scalaObject,35)\
kde.normalize\
theoreticKDEs = theoreticKDEs + (makam -> kde)\
}\
```
The third and last step is matching. First a list of audio\
files is created by recursively iterating a directory and matching each file to\
a regular expression. Next, starting from line 4, each audio file is processed.\
The internal implementation of the YIN pitch detection\
algorithm is used on the audio file and a pitch class histogram is created\
(line 6,7). On line 10 normalization of the histogram is done, to\
make the correlation calculation meaningful. Line 11 until 15 compare the\
created histogram from the audio file with the templates calculated beforehand.\
The results are stored, ordered and eventually printed on line 19.
```ruby\
val directory = “/home/joren/turkish_makams/”\
val audio_pattern = “.*.(mp3|wav|ogg|flac)”\
val audioFiles = FileUtils.glob(directory,audio_pattern,true).toList
audioFiles.foreach{ file =>\
val audioFile = new AudioFile(file)\
val detectorYin = PitchDetectionMode.TARSOS_YIN.getPitchDetector(audioFile)\
val annotations = detectorYin.executePitchDetection()\
val actualKDE = HistogramFactory.createPichClassKDE(annotations,15);\
actualKDE.normalize\
var resultList = List[Tuple2[java.lang.String,Double]]()\
for ((name, theoreticKDE) <- theoreticKDEs){\
val shift = actualKDE.shiftForOptimalCorrelation(theoreticKDE)\
val currentCorrelation = actualKDE.correlation(theoreticKDE,shift)\
resultList = (name -> currentCorrelation) :: resultList\
}\
//order by correlation\
resultList = resultList.sortBy{_._2}.reverse\
Console.println(file + “ is brought in tone scale “ + resultList(0)._1)\
}\
```
A complete version of this script can is available: “Tone scale matching script”:[guess_makam.scala] Results of the script when ran on Bozkurt’s dataset can be seen in the attached spreadsheet (“openoffice format”:[makam_recognition_results.ods] or “excel format”:[makam_recognition_results.xls]).
Theoretical template
Other theoretical template
Actual Hicaz song overlayed with a theoretical template
A paper about Tarsos was submitted for review at the 12th International Society for Music Information Retrieval Conference which will be held in Miami. The paper “Tarsos - a Platform to Explore Pitch Scales in Non-Western and Western Music”:[tarsos_ismir_2011.pdf] was reviewed and accepted, it will be published in this year’s proceedings of the ISMIR conference. It can be read below as well.
An oral presentation about Tarsos is going to take place Tuesday, the 25 of October during the afternoon, as can be seen on the ISMIR preliminary program schedule.
If you want to cite our work, please use the following data:
```ruby\
\@inproceedings{six2011tarsos,\
author = {Joren Six and Olmo Cornelis},\
title = {Tarsos - a Platform to Explore Pitch Scales\
in Non-Western and Western Music},\
booktitle = {Proceedings of the 12th International\
Society for Music Information Retrieval Conference,\
ISMIR 2011},\
year = {2011},\
publisher = {International Society for Music Information Retrieval}\
}\
```
Tarsos, a software package to analyse pitch organization in music, contains a new output modality. Now it is possible to export resynthesized pitch annotations, detected by a pitch detection algorithm and compare those with the original sound. This can be interesting to see which errors a pitch detection algorithm makes.
Below you can listen to an example of synthesized pitch detection results compared with the original flute piece. The file starts with only the original flute sound (on the right channel) and gradually changes so only the synthesized annotations (on the left channel) can be heard.
Naar jaarlijkse gewoonte wordt er in het Orpheus instituut de Dag van het Artistiek onderzoek georganiseerd. Hieronder volgt een tekstje over het onderzoeksproject rond Tarsos dat in het jaarboek komt. Het jaarboek is een boekje met daarin een overzicht van artistieke onderzoeksprojecten aan Vlaamse instituten. Het wordt gepubliceerd naar aanleiding van de eerder aangehaalde “Dag van het Artistiek Onderzoek”.
Het doel van dit onderzoeksproject is het ontwikkelen van een methode om een cultuuronafhankelijke kijk op muzikale parameters te verkrijgen. Meer concreet worden er technieken aangewend uit Music Information Retrieval om toonhoogte, tempo en timbre te bestuderen. Aanpassing van bestaande, meestal westers georiënteerde, MIR-methodes moet leiden tot een gestructureerde documentatie van verschillende klankkleuren, toonschalen, metrische verhoudingen en muzikale vormen. Die beschrijving kan dienen als inspiratie voor de ontwikkeling van een artistieke compsitionele taal of kan gebruikt worden als bronmateriaal voor wetenschappelijk onderzoek rond ethnische muziek. Bijvoorbeeld om (de eventuele\
teloorgang van) de eigenheid van orale muziekculturen objectief aan te tonen.
In de eerste fase van het onderzoek ligt de focus van het onderzoek op één van de meer tastbare parameters: toonhoogte. In etnische muziek is het gebruik van toonhoogte vaak radicaal anders dan westerse muziek die meestal gebaseerd is op de onderverdeling van een octaaf in twaalf gelijke delen. Om toonladders uit\
muziek te extraheren en weer te geven werd het software platform Tarsos ontwikkeld. Met Tarsos is het mogelijk om automatische toonladderanlyse uit te voeren op een grote dataset of om manueel een gedetailleerde analyse te verkrijgen van enkele muziekstukken. De cultuuronafhankelijke analysemethode waarvan Tarsos gebruik maakt kan even goed toegepast worden op Indonesische, Westerse of Afrikaanse muziek.
Onze bedoeling is om Tarsos te gebruiken om evoluties in toonladdergebruik te ontdekken in de enorme dataset van het Koninklijk Museum voor Midden-Afrika. Is toonladderdiversiteit in Afrika aan het wegkwijnen onder invloed van Westerse muziek? Zijn er specifieke kenmerken te vinden over eventueel 'uitgestorven' muziekculturen? Dit zijn vragen die kaderen in het overkoepelende onderzoeksproject van Olmo Cornelis en waar we met behulp van Tarsos een antwoord op proberen te vinden.
Later krijgen de twee overige muzikale parameters, tempo en timbre, een gelijkaardige behandeling. In de laatste fase van dit toch wel ambitieuze onderzoekproject wordt de relatie tussen de parameters onderzocht.
This post contains links to genuinely useful software to do signal based audio analysis.
Sonic Visualizer: As its name suggests Sonic Visualizer contains a lot different visualisations for audio. It can be used for analysis (pitch,beat,chroma,…) with VAMP-plugins. To quote “The aim of Sonic Visualiser is to be the first program you reach for when want to study a musical recording rather than simply listen to it”. It is the swiss army knife of audio analysis.
BeatRoot is designed specifically for one goal: beat tracking. It can be used for e.g. comparing tempi of different performances of the same piece or to track tempo deviation within one piece.
Tartini is capable to do real-time pitch analysis of sound. You can e.g. play into a microphone with a violin and see the harmonics you produce and adapt you playing style based on visual feedback. It also contains a pitch deviation measuring apparatus to analyse vibrato.
Tarsos is software for tone scale analysis. It is useful to extract tone scales from audio. Different tuning systems can be seen, extracted and compared. It also contains the ability to play along with the original song with a tuned midi keyboard .
Melodic Match is a different beast. It does not work on signal level but processes symbolic audio. More to the point it searches through MusicXML files - which can be created from MIDI-files. See its website for use cases. Melodic Match is only available for Windows.
During a lecture at the University College Gent, Faculty of Music these tools were presented with some examples. “The slides (Slides in Dutch)”:[presentatie.pdf] and “a zip-file with audio samples, slides and software”:[Tarsos-presentatie.zip] are available for reference. Most of the time was given to Tarsos, the software we developed.
Olmo Cornelis also gave a lecture about his own research and how Tarsos fits in the bigger picture. “His presentation (Slides in English)”:[lezing_Olmo_Cornelis_zonder_audio.ppt] and “the presentation with audio”:[lezing_Olmo_Cornelis_met_audio.zip] are also available here.
Yesterday Tarsos was publicly presented at the symposium Perspectives for Computational Musicology in Amsterdam. The first public presentation of Tarsos, excluding this website. The symposium was organized by the Meertens Institute on the occasion of Peter van Kranenburg’s PhD defense.
The presentation included a live demo of a daily build of Tarsos (a Friday evening build) which worked, surprisingly, without hiccups. The presentation was done by Olmo Cornelis. This was the small introduction:
Tarsos - a Platform for Pitch Analysis of Ethnic Music \
Ethnic music is a vulnerable cultural heritage that has received only recently more attention within the Music Information Retrieval community. However, access to ethnic music remains problematic, as this music does not always correspond to the Western concepts of music and metadata that underlie the currently available content-based methods. During this lecture, we like to present our current research on pitch analysis of African music. TARSOS, a platform for analysis, will be presented as a powerful tool that can describe and compare scales with great detail.
Tarsos can be used to render MIDI files to audio (WAV) files using arbitrary tone scales. This functionallity can be used to (automatically) verify tone scale extraction from audio files. Since I could not find a dataset with audio and corresponding tone scales creating one using MIDI seemed a good idea.
MIDI files can be found in spades, tone scales on the other hand are harder to find. Luckily there is one massive source, the Scala Tone Scale Archive: A large collection of over 3700 tone scales.
Using Scala tone scale files and a midi files a Tone Scale - Audio dataset can be generated. The quality of the audio depends on the (software) synthesizer and the SoundFont used. Tarsos currently uses the Gervill synthesizer. Gervill is a pure Java software synthesizer with support for 24bit SoundFonts and the MIDI tuning standard.\
How To Render MIDI Using Arbitrary Tone Scales with Tarsos
A recent version of the JRE (Java Runtime Environment) needs to be installed on your system if you want to use Tarsos. Tarsos itself can be downloaded in the form of the “Tarsos JAR Package”:[tarsos.jar].
Currently Tarsos has a Command Line Interface. An example with the files you can find attached:
The result of this command should yield an audio file that sounds like “the cello suites of bach in a nonsensical tone scale with steps of 120 cents”:[bach_BWV_1007_120.mp3]. Executing tone scale extraction on the generated audo yields the expected result. In the pich class histogram every 120 cents a peak can be found.
To summarize: by rendering audio with MIDI and Scala tone scale files a dataset with tone scale - audio information can be generated and tone scale extraction algorithms can be tested on the fly.
This method also has some limitations. Because audio is rendered there is no (background) noise, no fluctuations in pitch and timbre,… all of which are present in recorded audio. So testing testing tone scale extraction algorithms on recorded audio remains advised.
Tarsos can be used to search for music that uses a certain tone scale or tone interval(s). Tone scales can be defined by a Scala tone scale file or an exemplifying audio file. This text explains how you can use Tarsos for this task.
Search Using Scala Tone Scale Files
Scala files are text files with information about a tone scale. It is used to share and exchange tone scales. The file format originates from the Scala program :
Scala is a powerful software tool for experimentation with musical tunings, such as just intonation scales, equal and historical temperaments, microtonal and macrotonal scales, and non-Western scales. It supports scale creation, editing, comparison, analysis, …
Tarsos also understands Scala files. It is able to create a pitch class histogram using a gaussian mixture model. A technique described in A. C. Gedik, B.Bozkurt, 2010, “Pitch Frequency Histogram Based Music Information Retrieval for Turkish Music “, Signal Processing, vol.10, pp.1049-1063. (doi:10.106/j.sigpro.2009.06.017).
An example should make things clear. Lets search for an interval of 300 cents or exactly three semitones. A scala file with this interval is easy to define:
```ruby\
! example.scl\
! An example of a tone interval of 300 cents\
Tone interval of 300 cents\
2\
!\
900\
1200.0\
```
The next step is to create a histogram with an interval of 300 cents. In the block diagram this step is called “Peak histogram creation”. The Similarity calculation step expects a list of histograms to compare with the newly defined histogram. Feeding the similarity calculation with the western12ET tone scale and a pentatonic Indonesian Slendro tone scale shows that a 300 cents interval is used in the western tone scale but is not available in the Slendro tone scale.
This example only uses scala files, creating histograms is actually not needed: calculating intervals can be done using the scala file itself. This changes when audio files are compared with each other or with scala files.
Search Using Audio Files
When audio files are fed to the algorithm additional steps need to be taken.
First of all pitch detection is executed on the audio file. Currently two pitch extractors are implemented in pure Java, it is also possible to use an external pitch extractor such as aubio
Using pitch annotations a Pitch Histogram is created.
Peak detection on the Pitch Histogram results in a number of peaks, these should represent the distinct pitch classes used in the musical piece.
With the pitch classes a clean peak histogram is created during the Peak Histogram construction phase.
Finally the Peak histogram is matched with other histograms.
The last two steps are the same for audio files or scala files.
Using real audio files can cause dirty histograms. Determining how many distinct pitch classes are used is no trivial task, even for an expert (human) listener. Tarsos should provide a semi-automatic way of peak extraction: a best guess by an algorithm that can easily be corrected by a user. For the moment Tarsos does not allow manual intervention.
Tarsos
To use tarsos you need a recent java runtime (1.6) and the following command line arguments:
I just finished creating a first release of Tarsos. The release contains several demo applications, some more usefull than other. Tarsos is a work in progress: not all functionality is exposed with the CLI (Command Line Interface) demo applications. The demos should however give a taste of the possibilities. All demo applications follow this pattern:
Today I created a spectrogram application using Tarsos. The application listens to an audio input, computes an FFT and at the same time calculates pitch. The expected pitch is overlaid on the spectrogram. All this happens real-time and is implemented using JAVA.
The aim of this research project is to gain novel musicological insights into a large dataset of music from Central Africa. While practising ethnomusicological research on this dataset, we to develop and publish useful software and methodologies for the (ethno)musicological research community.
From November 2009 until November 2013 this research project was organised at the School of Arts, University College Ghent, under supervision by Olmo Cornelis. Later, from November 2013 onwards, the project turned into a 2 year doctoral research project hosted at IPEM, University Ghent under the supervision of Marc Leman.
Partners
University Ghent, IPEM: The Institute for Psychoacoustics and Electronic Music is part of the Music department at the Faculty of Arts and Philosophy, at Ghent University.

 Fig: Some AI imagining audio search.
Fig: Some AI imagining audio search.
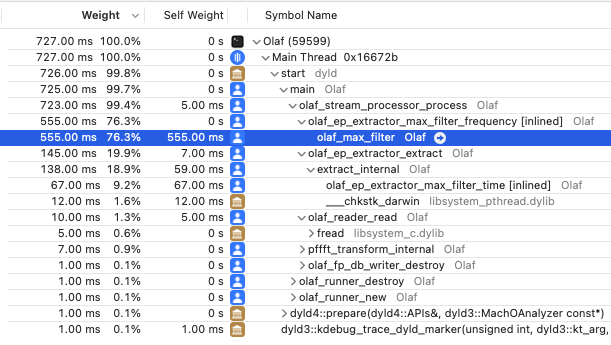 \
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.




















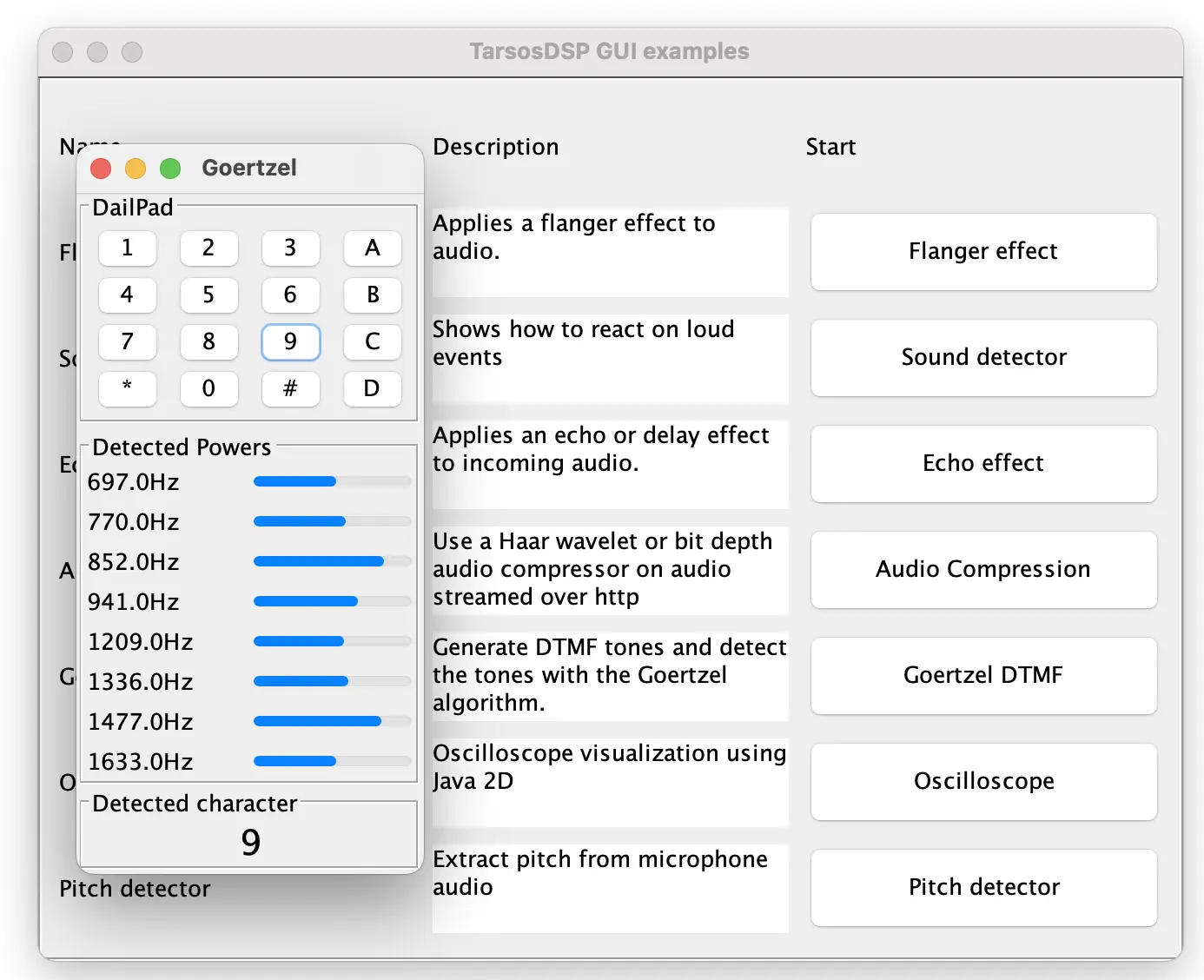




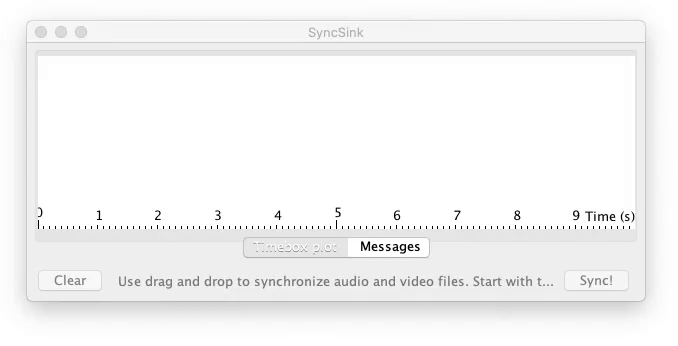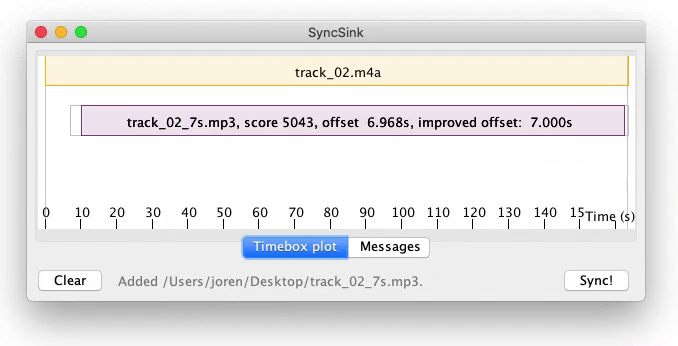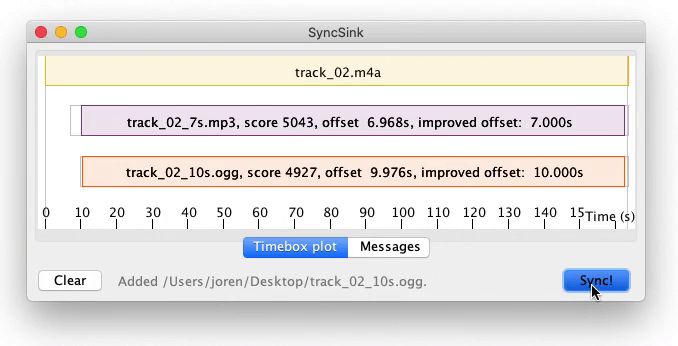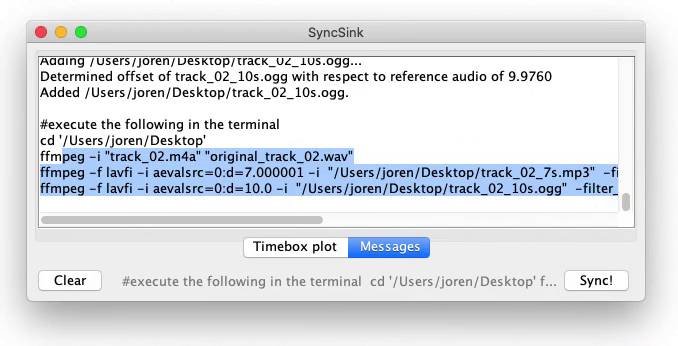


 As an extension of the ISMIR conferences the International Society for Music Information Retrievel started a new journal: TISMIR. The first issue contains an article of mine:\
As an extension of the ISMIR conferences the International Society for Music Information Retrievel started a new journal: TISMIR. The first issue contains an article of mine:\
 I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).
I have contributed to the 4th International Digital Libraries for Musicology workshop (DLfM 2017) which was organized in Shanghai, China. It was a satellite event of the ISMIR 2017 conference. Unfortunately I did not mange to find funding to attend the workshop, I did however contribute as co-author to two proceeding papers. Both were presented by Reinier de Valk (thanks again).



 can be synchronized with streams one and two. It allows a workflow where streams are started and stopped (red) or start before the reference stream (green).")


 while others are not (red, x). Matching fingerprints have the same offset, indicated by the dotted lines.")
 and balanceboard data (bottom, purple).")
, accelerometer-data (green) and audio (black).")
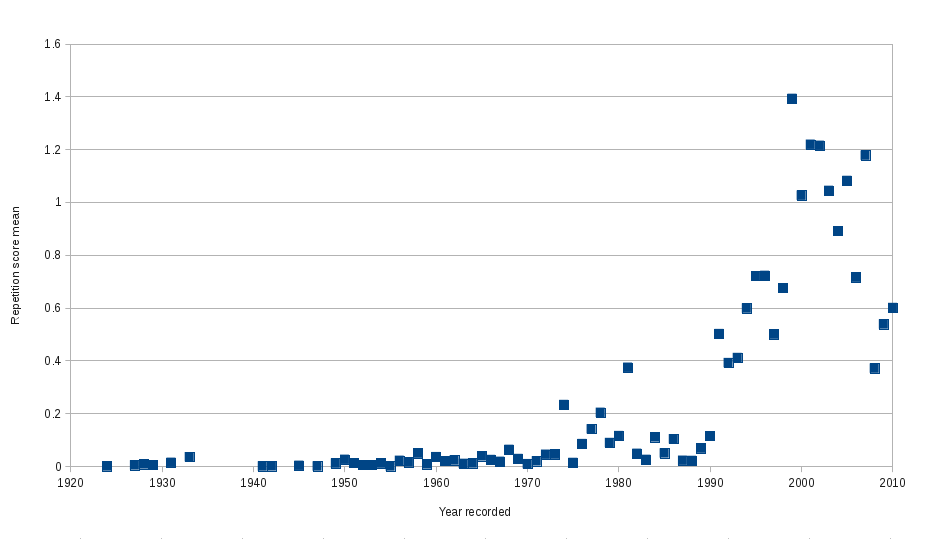 \
\













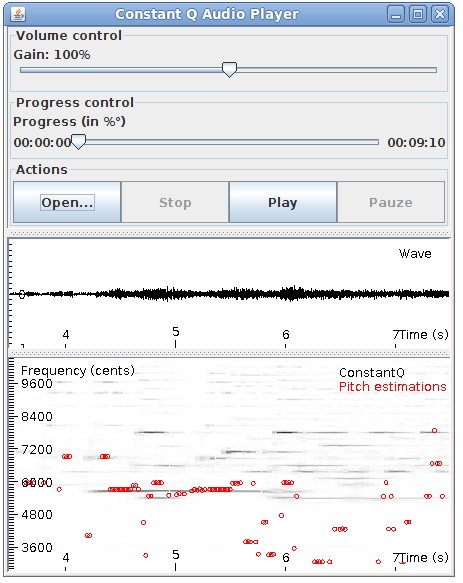
 The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of 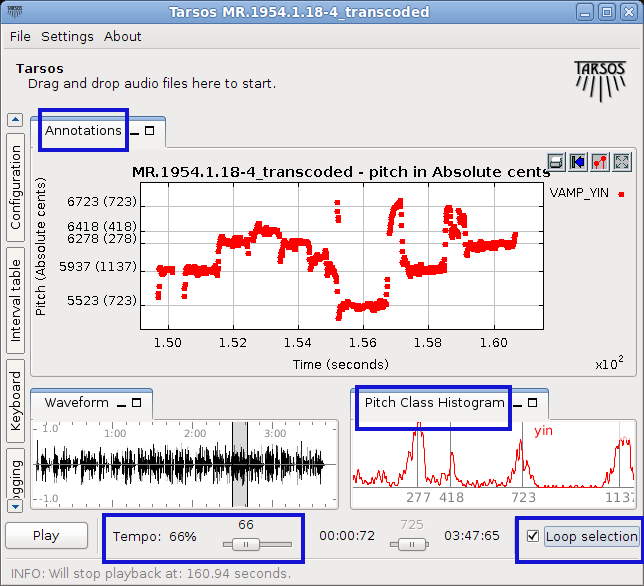 \
\
 The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The
The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The  What follows is about the
What follows is about the 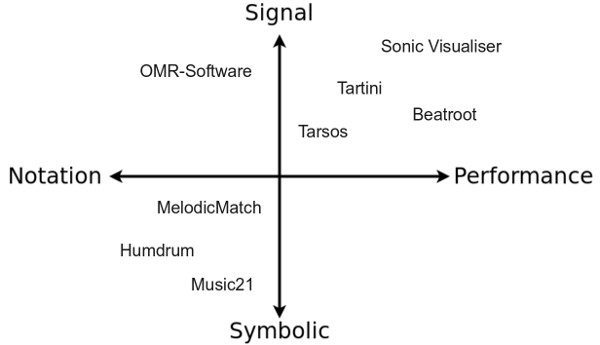






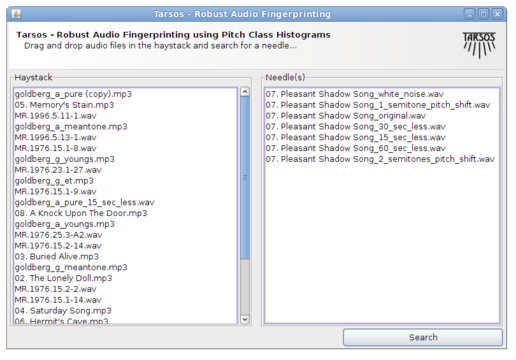



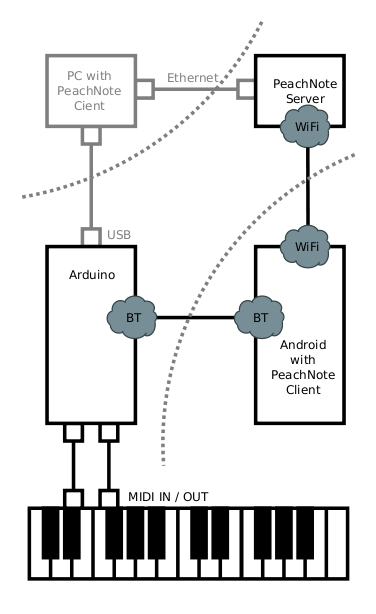 The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the
The extended abstract about PeachNote Piano has been accepted as a demonstration presentation to appear at the ISMIR (International Society for Music Information Retrieval) 2011 conference in Miami. To know more about PeachNote Piano come see us at our demo stand (during the 







 In de eerste fase van het onderzoek ligt de focus van het onderzoek op één van de meer tastbare parameters: toonhoogte. In etnische muziek is het gebruik van toonhoogte vaak radicaal anders dan westerse muziek die meestal gebaseerd is op de onderverdeling van een octaaf in twaalf gelijke delen. Om toonladders uit\
muziek te extraheren en weer te geven werd het software platform Tarsos ontwikkeld. Met Tarsos is het mogelijk om automatische toonladderanlyse uit te voeren op een grote dataset of om manueel een gedetailleerde analyse te verkrijgen van enkele muziekstukken. De cultuuronafhankelijke analysemethode waarvan Tarsos gebruik maakt kan even goed toegepast worden op Indonesische, Westerse of Afrikaanse muziek.
Onze bedoeling is om Tarsos te gebruiken om evoluties in toonladdergebruik te ontdekken in de enorme dataset van het Koninklijk Museum voor Midden-Afrika. Is toonladderdiversiteit in Afrika aan het wegkwijnen onder invloed van Westerse muziek? Zijn er specifieke kenmerken te vinden over eventueel 'uitgestorven' muziekculturen? Dit zijn vragen die kaderen in het overkoepelende onderzoeksproject van Olmo Cornelis en waar we met behulp van Tarsos een antwoord op proberen te vinden.
Later krijgen de twee overige muzikale parameters, tempo en timbre, een gelijkaardige behandeling. In de laatste fase van dit toch wel ambitieuze onderzoekproject wordt de relatie tussen de parameters onderzocht.
In de eerste fase van het onderzoek ligt de focus van het onderzoek op één van de meer tastbare parameters: toonhoogte. In etnische muziek is het gebruik van toonhoogte vaak radicaal anders dan westerse muziek die meestal gebaseerd is op de onderverdeling van een octaaf in twaalf gelijke delen. Om toonladders uit\
muziek te extraheren en weer te geven werd het software platform Tarsos ontwikkeld. Met Tarsos is het mogelijk om automatische toonladderanlyse uit te voeren op een grote dataset of om manueel een gedetailleerde analyse te verkrijgen van enkele muziekstukken. De cultuuronafhankelijke analysemethode waarvan Tarsos gebruik maakt kan even goed toegepast worden op Indonesische, Westerse of Afrikaanse muziek.
Onze bedoeling is om Tarsos te gebruiken om evoluties in toonladdergebruik te ontdekken in de enorme dataset van het Koninklijk Museum voor Midden-Afrika. Is toonladderdiversiteit in Afrika aan het wegkwijnen onder invloed van Westerse muziek? Zijn er specifieke kenmerken te vinden over eventueel 'uitgestorven' muziekculturen? Dit zijn vragen die kaderen in het overkoepelende onderzoeksproject van Olmo Cornelis en waar we met behulp van Tarsos een antwoord op proberen te vinden.
Later krijgen de twee overige muzikale parameters, tempo en timbre, een gelijkaardige behandeling. In de laatste fase van dit toch wel ambitieuze onderzoekproject wordt de relatie tussen de parameters onderzocht.