\
\
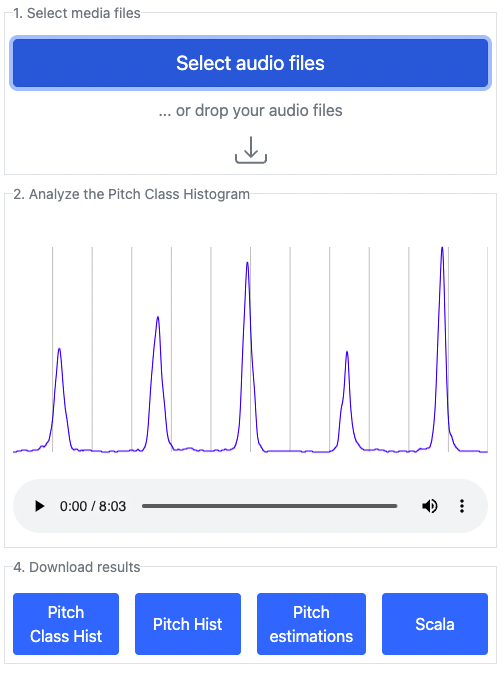
Fig: Screenshot of *Emotopa*: a browser based tool to extract pitch organization from audio.
A couple of days ago I participated in the Music Hack Day - India. The event was organized the 10th and 11th of December in Bangaluru, India. During the event a representative of Smule suggested a task to evaluate the performance of karaoke-singers in terms of intonation. The idea was to employ pitch histogram like features to estimate pitch use of singers.
I offered to build a browser based application to extract pitch histograms from audio. At the end of the hack day I presented the first release of Emotopa with some limited functionality:
Next, a pitch detector runs on the audio and returns a list of pitch estimates.
Finally a histogram (technically a kernel density estimate) is constructed using the pitch estimates.
The user can export the pitch histogram, the pitch class histogram and the pitch annotations. These features successfully show the intonation quality of singers but the applications are much broader. Some potential applications have been described in (amongst others) the Tarsos article.
The Emotopa name alludes to the Apotome browser based app where, starting from a scale you can make music. With Emotopa you do the reverse. Also very much of interest are Leimma and the rationale behind both Apotome and Leimma
This year the ISMIR 2022 conference is organized from 4 to 9 December 2022 in Bengaluru, India. ISMIR is the main music technology and music information retrieval (MIR) conference. It is a relief to experience a conference in physical form and not through a screen.
I have contributed to the following work which is in the main paper track of ISMIR 2022:
BAF: An Audio Fingerprinting Dataset For Broadcast Monitoring (version of record)\
Guillem Cortès, Alex Ciurana, Emilio Molina, Marius Miron, Owen Meyers, Joren Six, Xavier Serra\
Abstract: Audio Fingerprinting (AFP) is a well-studied problem in music information retrieval for various use-cases e.g. content-based copy detection, DJ-set monitoring, and music excerpt identification. However, AFP for continuous broadcast monitoring (e.g. for TV & Radio), where music is often in the background, has not received much attention despite its importance to the music industry. In this paper (1) we present BAF, the first public dataset for music monitoring in broadcast. It contains 74 hours of production music from Epidemic Sound and 57 hours of TV audio recordings. Furthermore, BAF provides cross-annotations with exact matching timestamps between Epidemic tracks and TV recordings. Approximately, 80% of the total annotated time is background music. (2) We benchmark BAF with public state-of-the-art AFP systems, together with our proposed baseline PeakFP: a simple, non-scalable AFP algorithm based on spectral peak matching. In this benchmark, none of the algorithms obtain a F1-score above 47%, pointing out that further research is needed to reach the AFP performance levels in other studied use cases. The dataset, baseline, and benchmark framework are open and available for research.
I have also presented a first version of DiscStitch, an audio-to-audio alignment algorithm. This contribution is in the ISMIR 2022 late breaking demo session:
DiscStitch: towards audio-to-audio alignment with robustness to playback speed variabilities (version of record)\
Joren Six\
Abstract: Before magnetic tape recording was common, acetate discs were the main audio storage medium for radio broadcasters. Acetate discs only had a capacity to record about ten minutes. Longer material was recorded on overlapping discs using (at least) two recorders. Unfortunately, the recorders used were not reliable in terms of recording speed, resulting in audio of variable speed. To make digitized audio originating from acetate discs fit for reuse, (1) overlapping parts need to be identified, (2) a precise alignment needs to be found and (3) a mixing point suggested. All three steps are challenging due to the audio speed variabilities. This paper introduces the ideas behind DiscStitch: which aims to reassemble audio from overlapping parts, even if variable speed is present. The main contribution is a fast and precise audio alignment strategy based on spectral peaks. The method is evaluated on a synthetic data set.
Next to my own contributions, the ISMIR conference program is the best overview of the state-of-the art of MIR.
This contribution was made possible thanks to travel funds by the FWO travel grant K1D2222N and the Ghent University BOF funded project PaPiOM.