~ Optimizing C code with profiling, algorithmic optimizations and 'ChatGPT SIMD'
» By Joren on Monday 26 June 2023This post details how I went about optimizing a C application. This is about an audio search system called Olaf which was made about 10 times faster but contains some generally applicable steps for optimizing C code or even other systems. Note that it is not the aim to provide a detailed how-to: I want to provide the reader with a more high-level understanding and enough keywords to find a good how-to for the specific tool you might want to use. I see a few general optimization steps:
- The zeroth step of optimization is to properly **question the need** and balance the potential performance gains against added code complexity and maintainability.
- Once ensured of the need, the first step is to **measure the systems performance**. Every optimization needs to be measured and compared with the original state, having automazation helps.
- Thirdly, the second step is to **find performance bottle necks**, which should give you an idea where optimizations make sense.
- The third step is to **implement and apply** an optimization and measuring its effect.
- Lastly, **repeat** steps zero to three until optimization targets are reached.
More specifically, for the Olaf audio search system there is a need for optimization. Olaf indexes and searches through years of audio so a small speedup in indexing really adds up. So going for the next item on the list above: measure the performance. Olaf by default reports how quickly audio is indexed. It is expressed in the audio duration it can process in a single second: so if it reports 156 times realtime, it means that 156 seconds of audio can be indexed in a second.
The next step is to find performance bottlenecks. A profiler is a piece of software to find such bottle necks. There are many options gprof is a command line solution which is generally available. I am developing on macOS and have XCode available which includes the “Instruments - Time Profiler”. Whichever tool used, the result of a profiling session should yield the time it takes to run each functions. For Olaf it is very clear which function needs optimization:
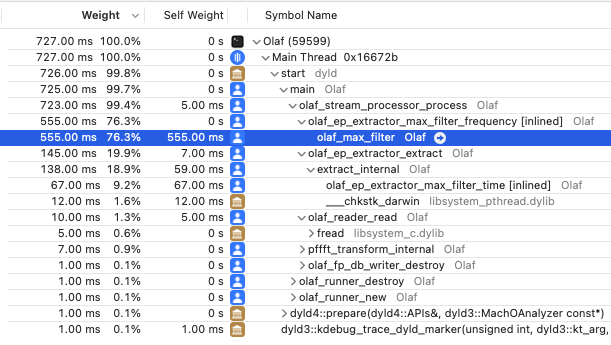 \
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
The function is a max filter which is ran many, many times. The implementation is using a naive approach to max filtering. There are more efficient algorithms available. In this case looking into the literature and implementing a more efficient algorithm makes sense. A very practical paper by Lemire lists several contenders and the ‘van Herk’ algorithm hits the sweet spot between being easy to implement and needing only a tiny extra amount of memory. The Lemire paper even comes with example c max-filters. With only a slight change, the code fits in Olaf.
After implementing the change two checks need to be done: is the implementation correct and is it faster. Olaf comes with a number of functional and unit checks which provide some assurance of correctness and a built in performance indicator. Olaf improved from processing audio 156 times realtime to 583 times: a couple of times faster.
After running the profiler again, another method came up as the slowest:
1
2
3
4
5
6
7
8
//Naive implementation
float olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
float max = -10000000;
for (size_t i = 0; i < array_size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
src: naive implementation of finding the max value of an array.
This is another part of the 2D max filter used in Olaf. Unfortunately here it is not easy to improve the algorithmic complexity: to find the maximum in a list, each value needs to be checked. It is however a good contender for SIMD optimization. With SIMD multiple data elements are processed in a single CPU instruction. With 32bit floats it can be possible to process 4 floats in a single step, potentially leading to a 4x speed increase - without including overhead by data loading.
Olaf targets microcontrollers which run an ARM instruction set. The SIMD version that makes most sense is the ARM Neon set of instructions. Apple Sillicon also provides support for ARM Neon which is a nice bonus. I asked ChatGPT to provide a ARM Neon improved version and it came up with the code below. Note that these type of simple functions are ideal for ChatGPT to generate since it is easily testable and there must be many similar functions in the ChatGPT training set. Also there are less ethical issues with ‘trivial’ functions: more involved code has a higher risk of plagiarization and improper attribution. The new average audio indexing speed is 832 times realtime.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#if defined(__ARM_NEON)
#include <arm_neon.h>
// ARM NEON implementation
float olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
assert(array_size % 4 == 0);
float32x4_t vec_max = vld1q_f32(array);
for (size_t j = 4; j < array_size; j += 4) {
float32x4_t vec = vld1q_f32(array + j);
vec_max = vmaxq_f32(vec_max, vec);
}
float32x2_t max_val = vpmax_f32(vget_low_f32(vec_max), vget_high_f32(vec_max));
max_val = vpmax_f32(max_val, max_val);
return vget_lane_f32(max_val, 0);
}
#else
//Naive implementation
#endif
src: a ARM Neon SIMD implementation of a function finding the max value of an array, generated by ChatGPT, licence unknown, informed consent unclear, correct attribution impossible.
Next, I asked ChatGPT for an SSE SIMD version targeting the x86 processors but this resulted in noticable slowdown. This might be related to the time it takes to load small vectors in SIMD registers. I did not pursue the SIMD SSE optimization since it is less relevant to Olaf and the first performance optimization was the most significant.
Finally, I went over the code again to see whether it would be possible exit a loop and simply skip calling olaf_ep_extractor_max_filter_time in most cases. I found a condition which prevents most of the calls without affecting the total results. This proved to be the most significant speedup: almost doubling the speed from about 800 times realtime to around 1500 times realtime. This is actually what I should have done before resorting to SIMD.
In the end Olaf was made about ten times faster with only two local, testable, targeted optimizations.
General takeways
-
Only think about optimization if there is a need and set a target: otherwise it is infinite.
-
Try to find a balance between complexity, maintainability and performance.
-
Changing a naive algorithm to a more intelligent one can have a significant performance increase. Check the literature for inspiration.
-
Check for conditions to skip hot code paths before trying fancy optimization techniques.
-
Profilers are crucial to identify where to optimize your code. Applying optimizations blindly is a waste of time.
-
Try to keep optimizations local and testable. Sprinkling your code with small, hard to test performance oriented improvements might not be worthwile.
-
SIMD generated by ChatGPT can be a very quick way to optimize critical, hot code paths. I would advise to only let ChatGPT generate small, common, easily testable code: e.g. finding the maximum in an array.
-
Having only localized ‘trivial’ ChatGPT parts means you can take them out once it is clear that you have copied code without proper attribution or licensing.
-
The use of SIMD can slow down your code if you are not careful, measure the effects of your ‘optimizations’!
-

Pre optimization, a single method takes most of the time. -

After optimization, a new method takes most time.

