Hi, I'm Joren. Welcome to my website. I'm a research software engineer in the field of Music Informatics and Digital Humanities. Here you can find a record of my research and projects I have been working on. Learn more »
Yesterday Tarsos was publicly presented at the symposium Perspectives for Computational Musicology in Amsterdam. The first public presentation of Tarsos, excluding this website. The symposium was organized by the Meertens Institute on the occasion of Peter van Kranenburg’s PhD defense.
The presentation included a live demo of a daily build of Tarsos (a Friday evening build) which worked, surprisingly, without hiccups. The presentation was done by Olmo Cornelis. This was the small introduction:
Tarsos - a Platform for Pitch Analysis of Ethnic Music \
Ethnic music is a vulnerable cultural heritage that has received only recently more attention within the Music Information Retrieval community. However, access to ethnic music remains problematic, as this music does not always correspond to the Western concepts of music and metadata that underlie the currently available content-based methods. During this lecture, we like to present our current research on pitch analysis of African music. TARSOS, a platform for analysis, will be presented as a powerful tool that can describe and compare scales with great detail.
Drag and drop works for scala tone scale files and different kinds of audio files. Audiofiles are transcoded automagically using an embedded ffmpeg binary which is platform dependend. It works on linux and windows, on other platforms only WAV files are supported.
Some of the current features:
Scala file extraction from audio
Real time pitch tracking
Real time pitch class histogram visualization
Alignment of pitch intervals with histogram using mouse dragging
Tarsos can be used to render MIDI files to audio (WAV) files using arbitrary tone scales. This functionallity can be used to (automatically) verify tone scale extraction from audio files. Since I could not find a dataset with audio and corresponding tone scales creating one using MIDI seemed a good idea.
MIDI files can be found in spades, tone scales on the other hand are harder to find. Luckily there is one massive source, the Scala Tone Scale Archive: A large collection of over 3700 tone scales.
Using Scala tone scale files and a midi files a Tone Scale - Audio dataset can be generated. The quality of the audio depends on the (software) synthesizer and the SoundFont used. Tarsos currently uses the Gervill synthesizer. Gervill is a pure Java software synthesizer with support for 24bit SoundFonts and the MIDI tuning standard.\
How To Render MIDI Using Arbitrary Tone Scales with Tarsos
A recent version of the JRE (Java Runtime Environment) needs to be installed on your system if you want to use Tarsos. Tarsos itself can be downloaded in the form of the “Tarsos JAR Package”:[tarsos.jar].
Currently Tarsos has a Command Line Interface. An example with the files you can find attached:
The result of this command should yield an audio file that sounds like “the cello suites of bach in a nonsensical tone scale with steps of 120 cents”:[bach_BWV_1007_120.mp3]. Executing tone scale extraction on the generated audo yields the expected result. In the pich class histogram every 120 cents a peak can be found.
To summarize: by rendering audio with MIDI and Scala tone scale files a dataset with tone scale - audio information can be generated and tone scale extraction algorithms can be tested on the fly.
This method also has some limitations. Because audio is rendered there is no (background) noise, no fluctuations in pitch and timbre,… all of which are present in recorded audio. So testing testing tone scale extraction algorithms on recorded audio remains advised.
Tarsos is now capable of reproducing speech using MIDI. The idea to convert speech into MIDI comes from the blog of Corban Brook where the following video can be found, actually a work by Peter Ablinger:
Another example of music inspired by speech is this interview with Louis Van Gaal:
Tarsos sends out midi data based on an FFT analysis of the signal. It maps the spectrogram to MIDI Messages and uses the power spectrum to calculate the velocity of each note on message.
The implementation can run in real-time but the output has some delay: the FFT calculation, constructing MIDI messages, calculating velocity, synthesizing sound, … is not instantaneous.
To use this capability Tarsos supports the following syntax. If a MIDI file is given the MIDI messages are written to the file. If an audio file is given Tarsos uses the audio as input. If the --pitch switch is used only the F0 is considered to construct MIDI messages instead of a complete FFT.
Tarsos can be used to search for music that uses a certain tone scale or tone interval(s). Tone scales can be defined by a Scala tone scale file or an exemplifying audio file. This text explains how you can use Tarsos for this task.
Search Using Scala Tone Scale Files
Scala files are text files with information about a tone scale. It is used to share and exchange tone scales. The file format originates from the Scala program :
Scala is a powerful software tool for experimentation with musical tunings, such as just intonation scales, equal and historical temperaments, microtonal and macrotonal scales, and non-Western scales. It supports scale creation, editing, comparison, analysis, …
Tarsos also understands Scala files. It is able to create a pitch class histogram using a gaussian mixture model. A technique described in A. C. Gedik, B.Bozkurt, 2010, “Pitch Frequency Histogram Based Music Information Retrieval for Turkish Music “, Signal Processing, vol.10, pp.1049-1063. (doi:10.106/j.sigpro.2009.06.017).
An example should make things clear. Lets search for an interval of 300 cents or exactly three semitones. A scala file with this interval is easy to define:
```ruby\
! example.scl\
! An example of a tone interval of 300 cents\
Tone interval of 300 cents\
2\
!\
900\
1200.0\
```
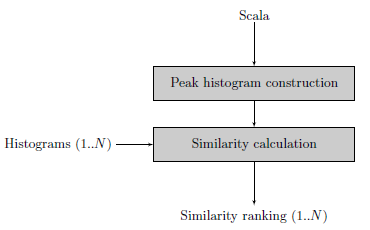
The next step is to create a histogram with an interval of 300 cents. In the block diagram this step is called “Peak histogram creation”. The Similarity calculation step expects a list of histograms to compare with the newly defined histogram. Feeding the similarity calculation with the western12ET tone scale and a pentatonic Indonesian Slendro tone scale shows that a 300 cents interval is used in the western tone scale but is not available in the Slendro tone scale.
This example only uses scala files, creating histograms is actually not needed: calculating intervals can be done using the scala file itself. This changes when audio files are compared with each other or with scala files.
Search Using Audio Files
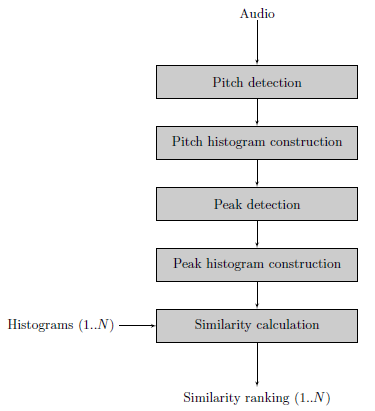
When audio files are fed to the algorithm additional steps need to be taken.
First of all pitch detection is executed on the audio file. Currently two pitch extractors are implemented in pure Java, it is also possible to use an external pitch extractor such as aubio
Using pitch annotations a Pitch Histogram is created.
Peak detection on the Pitch Histogram results in a number of peaks, these should represent the distinct pitch classes used in the musical piece.
With the pitch classes a clean peak histogram is created during the Peak Histogram construction phase.
Finally the Peak histogram is matched with other histograms.
The last two steps are the same for audio files or scala files.
Using real audio files can cause dirty histograms. Determining how many distinct pitch classes are used is no trivial task, even for an expert (human) listener. Tarsos should provide a semi-automatic way of peak extraction: a best guess by an algorithm that can easily be corrected by a user. For the moment Tarsos does not allow manual intervention.
Tarsos
To use tarsos you need a recent java runtime (1.6) and the following command line arguments:
This post is about the tools I use to keep the source code of Tarsos reasonably clean, consistent and readable. Static code analysis can be of great help if you want to maintain strict coding standards and follow language idioms. Some of the patterns they can detect for you:
Dead code - unused variables, parameters, methods
Suboptimal code - wasteful resource usage
Overcomplicated expressions - unnecessary if statements, for loops that could be while loops
Duplicate code - copied/pasted code is a code smell.
Formatting inconsistencies, e.g. variable modifier order
And even more subtle, but equally important:
Resource management: is a resource handled (closed) correctly on all possible code paths?
Abstraction level: is it needed to expose the concrete type of an object or could an (abstract) supertype or even an interface be used instead?
…
In a previous life I used .NET and the static code analysis tools FxCop & StyleCop. FxCop operates on bytecode (or intermediate language in .NET parlance) level, StyleCop analyses the source code itself. Tarsos uses JAVA so I looked for JAVA alternatives and found a few.
PMD & Checkstyle both operate on source code level.
FindBugs operates on bytecode level.
On freesoftwaremagazine.com there is an article series on JAVA static code analysis software. It covers PMD and FixBugs and integration in Eclipse. It does not cover Checkstyle. Checkstyle is essentialy the same as PMD but it is better integrated in eclipse: it checks code on save and uses the standard ‘Problems’ interface, PMD does not.
Continuous testing is also a really nice thing to have: detecting unexpected behavior while refactoring/programming can prevent unnecessary bug hunts. A video about immediate feedback using continuous testing makes this clear.
Another tip is a more philosophical one: making your code and code revisions publicly available makes you think twice before implementing (and subsequently publishing) a quick and dirty hack. Tarsos is available on github.
I just finished creating a first release of Tarsos. The release contains several demo applications, some more usefull than other. Tarsos is a work in progress: not all functionality is exposed with the CLI (Command Line Interface) demo applications. The demos should however give a taste of the possibilities. All demo applications follow this pattern:
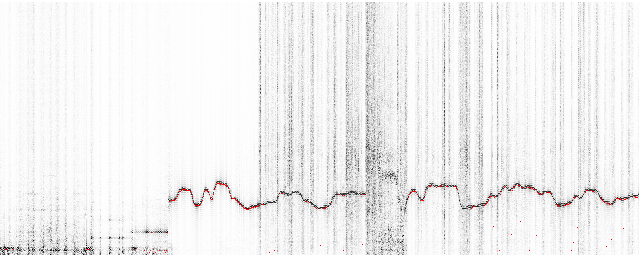
Today I created a spectrogram application using Tarsos. The application listens to an audio input, computes an FFT and at the same time calculates pitch. The expected pitch is overlaid on the spectrogram. All this happens real-time and is implemented using JAVA.
The JAVA software program we are developing is called Tarsos and can now be found on GitHub. GitHub is a web-based hosting service for projects that use the Git version control system.
Currently Tarsos is a collection of Java classes to create, compare and process pitch-frequency data using histograms. In it’s current state it is not usable for end-users.
The dataset we use is the sound archive of the department of Ethnomusicology of the Royal Museum for Central Africa at Tervuren, Belgium. The archive was digitized during the DEKKMMA (Digitization of the Ethnomusicological Sound Archive of the Royal Museum for Central Africa - it works better in Dutch) project. More information about the dataset can be foun on the website of the DEKKMMA project:
The archive is a collection of sound recordings of traditional music from Central Africa, with a particular focus on Congo and Rwanda. The sound archive contains about 3,000 hours of music recordings, the oldest of which date from 1910: Edison cylinders recorded by Hutereau in the Uele-province in Congo.
The archive contains several sound carriers (Edison cylinders, Sonofil wire, magnetic tapes, audiocassettes, disks, CD's ...) with associated metadata (paper files) and contextual data (photographs, films, video's, books, documents of all kind).
The collection was created during and after the colonial era of the Belgian Kingdom in Central Africa. The RMCA collection forms for an important part the musical memory of Central Africa and in terms of size, documentation and musical quality, it is -- without any doubt -- the world's most important sound archive for this region.
Using the meta data we did a rough geocoding of each recording to create an “interactive map of the dataset”:[dataset_geocodes.html].