I have updated Olaf - the Overly Lightweight Acoustic Fingerprinting system. Olaf is a piece of technology that uses digital signal processing to identify audio files by analyzing unique, robust, and compact audio characteristics - or “fingerprints”. The fingerprints are stored in a database for efficient comparison and matching. The database index allows for fast and accurate audio recognition, even in the presence of distortions, noise, and other variations.
Olaf is unique because it works on traditional computing devices, embedded microprocessors and in the browser. To this end tried to use ANSI C. C is a relatively small programming language but has very little safeguards and is full of exiting footguns. I enjoy the limitations of C: limitations foster creativity. I also made ample use of the many footguns C has to offer: buffer overflows, memory leaks, … However, with the current update I think most serious bugs have been found. Some of the changes to Olaf include:
Fixed a rather nasty array out of bounds bug. The bug remained elusive due to the fact that a segfault was rare on macOS. Linux seems to be more diligent in that regard.
Added a quick way to skip already indexed files. Which improves usability significantly when working with larger datasets.
Improved command line output and fixed incorrectly reported times. The reported start and stop time of a query was wrong and is now fixed.
Olaf now supports caching fingerprints in simple text files. This makes fingerprint extraction much faster since all cores of the system can be used to extract fingerprints and dump them to text files. Writing prints to the database from multiple threads is slow since they need to wait for access to the locked database. There is also a command to store all cashed fingerprints in a single go.
Added support for basic profiling with gprof. The profiler shows where optimizations can have the most impact.
Olaf now includes an algorithm for efficient max-filtering. The min-max filter algorithm by Daniel Lemire is implemented. The profiler showed that most time was spend during max-filtering: replacing the naive max-filter with the Lemire max-filter improved performance drastically.
CI with Github Actions which checks if checked in sources compile and tests some of the basic functionality automatically.
Updated the Zig build script for cross-compilation and updated the pre-build Windows version.
Tested the system with larger databases. The FMA-full datasets, which comprises almost a full year of audio was indexed and queried without problems on a single pc. The limits of Olaf with respect to indexed size is probably a few times larger.
Tested, fixed and improved the ‘memory database’ version. Also added documentation to the readme.
Made a basic web example to call the WASM version of Olaf.
Added an ESP32 example, showing how Olaf can run on this microprocessor. It runs without an external microphone but uses a test audio file. Previously some small changes were needed to Olaf to run on the ESP32, now the exact same code is used.
Anyhow, what originally started as a rather quick and dirty hack has been improved quite a bit. The takeaway message: in the world of software it does seem possible to polish a turd.
As a way to get to know the Rust programming language I have developed a couple of practical tools for OSC and MIDI debugging. OSC and MIDI are protocols which are almost always used for applications dealing with music. In these applications latency should be kept in check. Languages with garbage collection (Java, Go) and scripting languages (Ruby, Python, …) are hard to tune for low-latency applications and do not really have real-time guarantees. Rust, as a modern alternative for C/C, is a better fit for cross platform CLI low-latency applications.
This opens a couple of possibilities which are discussed below.
Sending UDP messages from the browser
One of the ways to send OSC messages from a browser to a local network is by using the MIDI out capability of browsers and - using mot - translating MIDI to OSC an example can be seen below.
Fig: sending an UDP message to a network from a Browser using a the mot MIDI to OSC bridge, click the image for a better readable version.
Measuring UDP message latency
Both MIDI and OSC can be seen as rather general data encapsulation protocols with wide support in terms of libraries and cross platform support. Their value goes beyond mere musical applications. The same holds for mot. In this example we are using mot to measure UDP message latency between two hosts.
On the first host we send MIDI messages from MIDI device 0 over OSC to another host with e.g. mot midi_to_osc 192.168.1.12:3000 /m 0. At the other host we receive the OSC messages and send them to a virtual device: mot osc_to_midi 192.168.1.12:3000 /m 6666.
At the second host we return messages from the virtual device to the first host: mot midi_to_osc 192.168.1.4:5000 /m 1. Perhaps you first need to do mot midi_to_osc -l to find the index of the virtual device. As a final step the messages can be received at the first host and returned to the original midi device. On the first host: mot osc_to_midi 192.168.1.4:5000 /m 0.
If the original MIDI device is a Teensy running the “roundtrip patch” then finally the roundtrip time is accurately measured and shown in the serial console. I am sure the previous text is cromulent, totally not contrived and not confusing. Anyway, to make it more confusing: this is what happens when you use a single host to do midi to osc to midi to osc to midi and use the loopback networking device:
Fig: MIDI to OSC to MIDI to OSC to MIDI roundtrip latency.
Visualizing sensor data in the browser
Fig: Sensor data as MIDI.
When capturing sensor data on microcontrollers, data can be encoded into MIDI. This makes almost any sensor practically useful in Ableton Live or similar environments. It also makes it compatible with all other MIDI supporting devices. With mot it becomes trivial to send MIDI encoded sensor data over OSC e.g. to a central place to log that data.
Another use case is to visualize the incoming data in real-time. A single web page which reads and visualizes incoming MIDI-sensor data becomes much more useful if streams from other devices can be visualized as well with the mot midi_to_osc and mot osc_to_midi commands.
Cross-platform support
With the Rust compiler it is relatively easy to cross-compile for different targets. There is however an important limitation in mot. Windows has no support for virtual MIDI ports which limits the usefulness of mot on that platform.
Fig: Advances in Speech and Music Technology book cover.
I have recently published an chapter in an academic book published by Springer. The topic of the book is of interest to me but can be perceived as rather dry: Advances in Speech and Music Technology.
The chapter I co-authored presented two case studies on detecting duplicates in music archives. The fist case study deals with segmentation reuse in an archive of early electronic music. The second with meta-data reuse in an archive of a public broadcaster containing digitized commercial shellac disc recordings with many duplicates.
Duplicate detection being the main topic, I decided to title the article Duplicate Detection for for Digital Audio Archive Management. It is easy to miss, and not much is lost if you do, but there is a duplicate‘for’ in the title. If you did detect the duplicate you have detected the duplicate in the duplicate detection article. Since I have fathered two kids I see it as an hard earned right to make dad-jokes like that. Even in academic writing.
It was surprisingly difficult to get the title published as-is. At every step of the academic publishing process (review, editorial, typesetting, lay-outing) I was asked about it and had to send an email like the one below. Every email and every explanation made my second-guess my sense of humor but I do stand by it.
From: Joren \
To: Editors ASMT \
\
Dear Editors, \
\
I have updated my submission on easychair in...\
\
I would like to keep the title however as is an attempt at word-play. These things tend to have less impact when explained but the article is about duplicate detection and is titled 'Duplicate detection for for digital audio archive management'. The reviewer, attentively, detected the duplicate 'for' but unfortunately failed to see my attempt at humor. To me, it is a rather harmless witticism.
Regards
Joren
</pre>
Anyway, I do think that humor can serve as a gateway to direct attention to rather dry, academic material. Also the message and the form of the message should not be confused. John Oliver, for example, made his whole career on delivering serious sometimes dry messages with heaps of humor: which does not make the topics less serious. I think there are a couple of things to be learned there. Anyway, now that I have your attention, please do read the author version of Duplicate Detection for for Digital Audio Archive Management: Two Case Studies.
TarsosDSP is a Java library for audio processing I have started working on more than 10 years ago. The aim of TarsosDSP is to provide an easy-to-use interface to practical music processing algorithms. Obviously, I have been using it myself over the years as my go-to library for audio-processing in Java. However, a number of gradual changes in the java ecosystem made TarsosDSP more and more difficult to use.
Since I have apparently not been the only one using it, there was a need to give it some attention. During the last couple of weeks I have found the time to give it this much needed attention. This resulted in a number of updates, some of the changes include:
Change of the build system from Apache Ant to Gradle
Make use of Java Modules to make TarsosDSP compatible with the ModulePath introduced in Java 9.
Packaged the software into a maven compatible format, which makes it easy to use as a dependency.
CI with GitHub actions to automatically build and test the software.
Updated some examples shipped with the TarsosDSP. I have still still some examples to verify.
Improved handling of errors on reading audio via ffmpeg
\
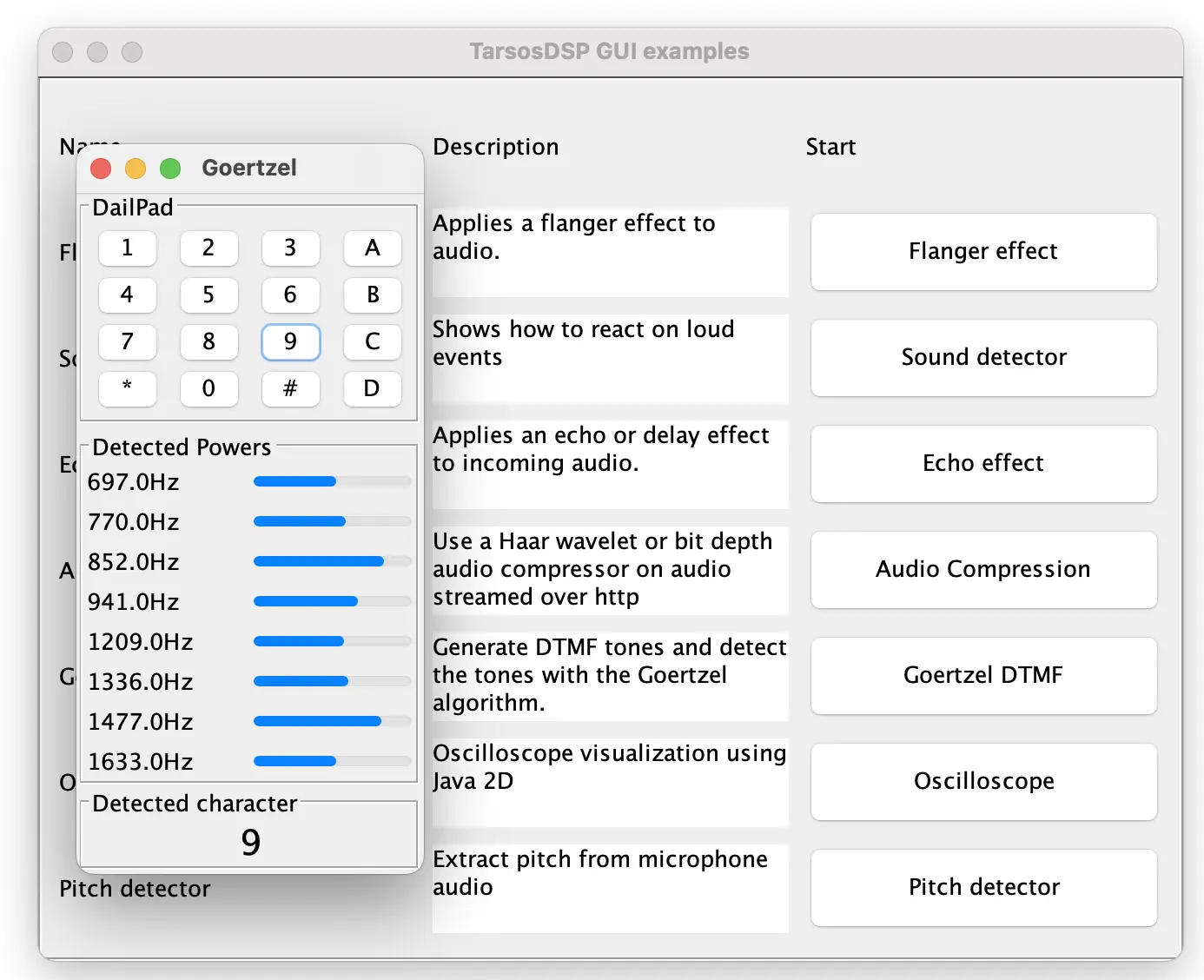
Fig: The updated TarsosDSP release contains many CLI and GUI example applications.
Notably the code of TarsosDSP has not changed much apart from some cosmetic changes. This backwards compatibility is one of the strong points of Java. With this update I am quite confident that TarsosDSP will also be usable during the next decade as well.
This blog has been running on Caddy for the last couple of months. Caddy is a http server with support for reverse proxies and automatic https. The automatic https feature takes care of requesting, installing and updating SSL certificates which means that you need much less configuration settings or maintenance compared with e.g. lighttpd or Nginx. The underlying certmagic ACME client is responsible for requesting these certificates.
Before, it was using lighttpd but the during the last decade the development of lighttpd has stalled. lighttpd version 2 has been in development for 7 years and the bump from 1.4 to 1.5 has been taking even longer. lighttpd started showing its age with limited or no support for modern features like websockets, http/3 and finicky configuration for e.g. https with virtual domains.
Caddy with Ruby on Rails
I really like Caddy’s sensible defaults and the limited lines of configuration needed to get things working. Below you can find e.g. a reusable https enabled configuration for a Ruby on Rails application. This configuration does file caching, compression, http to https redirection and load balancing for two local application servers. It also serves static files directly and only passes non-file requests to the application servers.
If you are self-hosting I think Caddy is a great match in all but the most exotic or demanding setups. I definitely am kicking myself for not checking out caddy sooner: it could have saved me countless hours installing and maintaining https certs or configuring lighttpd in general.
JNI is a way to use C or C code from Java and allows developers to reuse and integrate C/C in Java software. In contrast to the Java code, C/C code is platform dependent and needs to be compiled for each platform/architecture. Also it is generally not a good idea to make users compile a C/C library: it is best provide precompiled libraries. As a developer it is, however, a pain to provide binaries for each platform.
With the dominance of x86 processors receding the problem of having to compile software for many platforms is becoming more pressing. It is not unthinkable to want to support, for example, intel and M1 macOS, ARM and x86_64 Linux and Windows. To support these platforms you would either need access to such a machine with a compiler or configure a cross-compiler for each system: both are unpractical. Typically setting up a cross-compiler can be time consuming and finicky and virtual machines can be tough to setup. There is however an alternative.
Zig is a programming language but, thanks to its support for C/C, it also ships with an easy-to-use cross-compiler which is of interest here even if you have no intention to write a single line of Zig code. The built-in cross-compiler allows to target many platforms easily.
Cross compilation of C code is possible by simply replacing the gcc command with zig cc and adding a target argument, e.g. for targeting a Windows. There is more general information on zig as a cross-compiler here.
Cross-compiling a JNI library is not different to compiling other libraries. To make things concrete we will cross-compile a library from a typical JNI project: JGaborator packs the C/C library gaborator. In this case the C/C code does a computationally intensive spectral transformation of time domain data. The commands below create an x86_64 Windows DLL from a macOS with zig installed:
{style="overflow-x:scroll"}
<code>
bash
#wget https://aka.ms/download-jdk/microsoft-jdk-17.0.5-windows-x64.zip#unzip microsoft-jdk-17.0.5-windows-x64.zip#export JAVA_HOME=`pwd`/jdk-17.0.5+8/
git clone --depth 1https://github.com/JorenSix/JGaborator
cd JGaborator/gaborator
echo $JAVA_HOMEJNI_INCLUDES=-I"$JAVA_HOME/include"\ -I"$JAVA_HOME/include/win32"
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC pffft/pffft.c -o pffft/pffft.o
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC -DFFTPACK_DOUBLE_PRECISION pffft/fftpack.c -o pffft/fftpack.o
zig c++ -target x86_64-windows-gnu -I"pffft" -I"gaborator-1.7"$JNI_INCLUDES -O3\
-ffast-math -DGABORATOR_USE_PFFFT -o jgaborator.dll jgaborator.cc pffft/pffft.o pffft/fftpack.o
file jgaborator.dll
# jgaborator.dll: PE32+ executable (console) x86-64, for MS Windows
</code>
Note that, when cross-compiling from macOS, to target Windows a Windows JDK is needed. The windows JDK has other header files like jni.h. Some commands to download and use the JDK are commented out in the example above. Also note that targeting Linux from macOS seems to work with the standard macOS JDK. This is probably due to shared conventions regarding compilation of libraries.
To target other platforms, e.g. ARM Linux, there are only two things that need to be changed: the -target switch should be changed to aarch64-linux-gnu and the name of the output library should be (by Linux convention) changed to libjgaborator.so. During the build step of JGaborator a list of target platforms it iterated and a total of 9 builds are packaged into a single Jar file. There is also a bit of supporting code to load the correct version of the library.
Using a GitHub action or similar CI tools this cross compilation with zig can be automated to run on a software release. For Github the Setup Zig action is practical.
Loading the correct library
In a first attempt I tried to detect the operating system and architecture of the environment to then load the library but eventually decided against this approach. Mainly because you then need to keep an exhaustive list of supporting platforms and this is difficult, error prone and decidedly not future-proof.
In my second attempt I simply try to load each precompiled library limited to the sensible ones - only dll’s on windows - until a matching one is loaded. The rationale here is that the system itself knows best which library works and failing to load a library is computationally cheap. There is some code to iterate all precompiled libraries in a JAR-file so supporting an additional platform amounts to adding a precompiled library in the JAR folder: there is no need to be explicit in the Java code about architectures or OSes.
Trying multiple libraries has an additional advantage: this allows to ship multiple versions targeting the same architecture: e.g. one with additional acceleration libraries enabled and one without. By sorting the libraries alphabetically the first, then, should be the one with acceleration and the fallback without. In the case of JGaborator for mac aarch64 there is one compiled with -framework Accelerate and one compiled by the Zig cross-compiler without.
Takehome messages
If you find yourself cross-compiling C or C for many platforms, consider the Zig cross-compiler. Even when you have no intention to write a single line of Zig code.
For JNI and Java the JGaborator source code might offer some inspiration to pre-compile and load libraries for many platforms with little effort.
CI tools can help to verify builds and automate Zig cross-compilation.
If you build for Windows make sure to include windows header-files even when there are no compilation errors using UNIX-header files.