The Web Audio API offers some great functionality for web based audio applications. The API also has a couple of quirks and is not always easy to use. One of those quirks is the limited support for resampling audio. When requesting a microphone stream of a certain sample rate the API only allows configurations your hardware supports. Ideally there should be an option to resample the incoming stream to a requested sample rate (and format) independent of hardware.
On macOS and Chrome the issue becomes even more confusing: when using multiple AudioContexts they can only have the same sample rate. E.g. starting a microphone on 16kHz by itself is possible but not when there is also audio playback on the same page, then everything switches over to 48kHz. There even seems to be an effect of different browser tabs. Other browsers and platforms have similar issues. This is problematic when you need audio in a fixed sample rate.
The solution is to resample audio incoming samples in your code or use the OfflineAudioContext as a resampler. The OfflineAudioContext way needs a lot of code and, crucially, only works on the main browser thread and not in an AudioWorklet. The AudioWorklet should be the place for computationally intensive audio processing like resampling. To solve the resampling problem I have glued together an AudioWorklet and libsamplerate-js to provide an easy to use audio resampling solution which is demo’d below:
The demo does not seem to do much but it reads incoming microphone data and uses a high quality audio resampling library to resample an audio stream into a requested audio sampling rate. The browser development console shows some info on this process. To get this working in an audio worklet, the libsamplerate-js needed to be recompiled and directly included in the AudioWorklet. To inspect the source, check the “Web Audio API AudioWorklet resampler”:[web-audio-api-resample.zip].
The recent version of the OLAF (Overly Lightweight Acoustic Fingerprinting) audio fingerprinting system also includes an updated WASM build which deserves a bit more attention.
The browser version of Olaf enables audio fingerprinting in the browser. This can be used to e.g. react to music playing in the environment, so called second screen applications or to synchronize several devices to an audio stream.
The goal of the demo below is to play music aloud - not using headphones - using the controls on the left. You can either play the reference track or an unrelated distractor. Next, the Olaf fingerpinter system needs to be started using the button on the right which captures the microphone of your device. Then Olaf tries match the incoming sound of the microphone and the reference track. Once a match is found the exact time in the match is displayed until the sound matches no more. Note that there is no direct information flowing between the left and right part. You can also play the reference on another device to be sure.
Reference:
\
Distractor:
To get this demo working with the Web Audio API and use AudioWorklet objects, to process audio in the background an not on the main browser thread. There is surprisingly little info to find on how to combine WASM libraries - I used both Olaf and libsamplerate-js - and the AudioWorklet environment. Thanks to one of the very few resources on combining WASM, emscripten and AudioWorklets led me in the right direction.
Olaf is an acoustic fingerprinting system designed with embedded devices in mind. It has a low memory use and computational requirements which are compatible with e.g. the ESP32 line of microcontrollers devices like the SparkFun ESP32 Thing or devices based on the RP2040 chip. Recently I have prepared a demo with the newest version of Olaf running on an ESP32 which deserves some attention.
To match audio, Olaf needs access to streaming audio. This can be audio read from an SD-card but, more likely, audio comes from a microphone. Digital microphones have some great features: a low-noise floor, great at picking up omnidirectional sound and they are inexpensive. I have prepared a demo of Olaf which shows how to use Olaf on an ESP32 with an INMP441 MEMS microphone. To test the MEMS microphone I also made a MEMS microphone to WiFi program which sends incoming sound on the ESP32 over WiFi to a computer where the sound quality can be verified.
The example provides a scaffold for embedded music-reactive applications. Once the microcontroller knows which song is playing and where in the song the match is found it can trigger LED’s (or explosions, fireworks, lyrics, other effects…) which should happen in sync with the music. See the example below to get the idea, this demo runs an older version of Olaf but the idea stays the same:
The main difference between the current and previous versions of Olaf is that now the ESP32 version, the browser version and the PC version are all running the exact same code. No hacks are needed any more to support a platform. This means that testing and debugging can be done on a computer and, if everything goes well, the code should work as expected on the embedded device (or browser).
Getting MEMS microphones to work on microcontroller platforms as the ESP32 is challenging. In theory, the I2S protocol provides a standardised, easy way to receive audio from a microphone and send stereo audio to a DAC. In practice, the many parameters make I2S not straightforwards to use. As with most protocols and standards, the mismatch between limitations and quirks of specific hardware and software implementations can cause issues. To debug I2S microphones on ESP32 or the RP2040 I have prepared a small Arduino program.
The IS2 WiFi microphone program sends audio from the microphone over WiFi to a computer which listen to the microphone: this make sure that the microphone works as expected and audio samples are correctly interpreted. It validates the I2S settings like buffer sizes, sample rates, audio formats, stereo or mono settings, … After configuring an SSID, password and IP-address it becomes possible to listen — in real-time — to the microphone which also allows the listener to sense the microphone quality.
size_t bytesIn = 0;
esp_err_t result = i2s_read(I2S_PORT, &sBuffer, bufferLen, &bytesIn, portMAX_DELAY);
int16_t *sample_buffer = (int16_t *)sBuffer;
int16_t samples_read = bytesIn / 2;
float audio_block_float[samples_read];
for (size_t i = 0; i < samples_read; i++) {
sample_buffer[i] = gain_factor * sample_buffer[i];
// Max for signed int16_t is 2^15
audio_block_float[i] = sample_buffer[i] / 32768.f;
}
// Send raw audio 32bit float samples over UDP
Udp.beginPacket(outIp, outPort);
Udp.write((const uint8_t *)audio_block_float, bytesIn * 2);
Udp.endPacket();
Fig: The main part of reading i2s audio from a microphone and sending an UDP packet.
To listen to the incoming audio an UDP port needs to be captured and subsequently send to a program that can interpret and play or store audio. With netcat UDP data can be captured. With ffmpeg and ffplay audio can be payed or stored. In practice the receiving computer might run the following commands to decode UDP packages and hear the microphone:
# for playback, receive UDP packages and interpret raw audio
nc -l -u 3000 | ffplay -f f32le -ar 16000 -ac 1 -
# for playback, receive UDP packages and store in a wav file
nc -l -u 3000 | ffmpeg -f f32le -ar 16000 -ac 1 -i pipe: microphone.wav
I have just released a Python wrapper for the Olaf acoustic fingerprinting library. Olaf is a scalable audio search system based on indexing . Olaf is programmed in C but a wrapper now makes its functionality available in Python.
The python wrapper should make it more accessible for developers to get started with it and makes it compatible with other Python libraries. A few notable libraries are the librosa python package for music and audio analysis,nnAudio, A fast GPU audio processing toolbox and other more general plotting, data processing and machine learning libraries. Despite Python’s many flaws, its rich library ecosystem is unmatched.
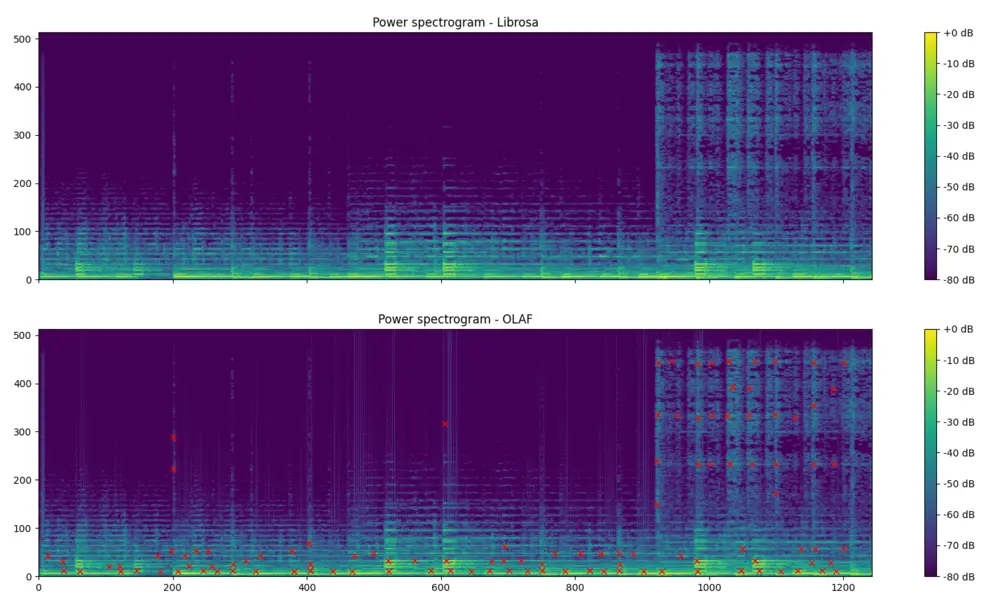
The associated GitHub repository contains documentation on how to use the Olaf python wrapper and also contains examples. The first shows how to index a song into the database and subsequently query the database. The second visualises the event points extracted by Olaf. The figure below shows shows the resulting event points, extracted with Olaf, plotted on a magnitude spectrogram, calculated with Olaf. The spectrogram on top is calculated using librosa and is meant to be very similar to Olaf.
\
Fig: *A power spectrum from librosa and one from Olaf, with event points marked*.
The wrapper was made with Python CFFI which works reasonably well. The automatically generated wrapper library support a large part of the C language but it needs a compilation step for each platform. Currently, the instructions assume a POSIX-like system, but technically, the wrapper can also function on Windows, albeit with the potential need for Windows-equivalent instructions in place of certain POSIX ones. The wrapper is wrapped in an easy to use python class called Olaf.py:
```python\
from olaf import Olaf, OlafCommand\
import librosa
Store the first ten seconds of an audio file\
audio_file = librosa.ex(‘choice’)\
Olaf(OlafCommand.STORE,audio_file).do(duration=10.0)
Query for a part of the same file (with an offset of 7 seconds), but change volume\
y, sr = librosa.load(audio_file,mono=True, sr=16000,duration=10,offset=7.0)\
y = y * 0.8 #change the volume\
results = Olaf(OlafCommand.QUERY,audio_file).do(y=y)
We expect a match between the stored and partially overlapping query\
print(results)\
```
I have been using a couple of UniFi devices in my home network for a couple of years. These devices proved to be reliable and full-featured, especially considering the relatively low price point. To manage UniFi devices a self-hosted instance of the UniFi network server is practical, especially when you already have a home server.
Unfortunately, the official installation instructions for UniFi miss a crucial step for installation on Debian 11. The network manager is not compatible with newer versions of mongodb. To install a version of mongodb compatible with UniFi on Debian 11, use the following commands:
The Wall Street Journal made a video on the internals Shazam fingerprinter. The visuals and technical explanation serves as a very good introduction in spectral-peak-based audio fingerprinting. For those who want a more in depth view or want to try out such systems: I have implemented extensions on the Shazam technique in two open-source systems.
Olaf is a spectral-peak based fingerprinter aimed at embedded systems, traditional computers and browsers. Panako is implemented in Java and has robustness against pitch-shifting and time-stretching which is briefly mentioned in the video below as well:
I often play board games with my kids. One of them is an absolute board game fan while the other is a sore loser and only wants to play collaborative games. These games are played ‘against the board’ and you win, or lose, together. I myself also still have problems losing games so I do understand this predicament. Genetics…
Rock & Troll is one of those games. It is a chance based game where you collaboratively try to build a path to a treasure before the dragon reaches it. Every player has to flip a tile which is either a part of the path (good) or a dragon (very bad). To increase engagement during play I often add sound effects. I was thinking: this can be improved and automated. For example, by doing this when a dragon tile is flipped:
The idea is to unobtrusively detect game state and add sound effects at critical moments. The sound effect should be playing without too much lag, ideally within about 200ms, so it feels immediate and connected to the game event. To implement this a camera based system with robust, fast object detection seemed like the way to go.
Dragon detection
To detect dragons in a video stream I want to retrain an existing object-detection system. So two things need to happen: first a realistic, labeled dataset needs to be created. Then a system needs to be trained to detect the dragons. We do not want to label a massive dataset so we will use transfer learning to retrain an existing network. This existing network should already have learned basic features like edges, colors, geometries and other basic patterns. With the hope that this would result in robust detection, even with a limited dataset.
To create the dataset I wrote a small script which took a webcam picture every few seconds while I was manipulating the board and tiles. This resulted in about 130 pictures, some with no dragons and some with six, 300 labels in total. For annotating the dataset I used the free roboflow web-app which also hosts the final dragon dataset. After augmentation, the size of the dataset can be tripled. The command to extract images from a webcam looks like this on my system:
After some consideration for alternatives I landed on the YOLOv8 object-detection system: a robust and fast object-detection system. Additionally, it is well-documented, pytorch-based, easy-to-use and it has support for video streams. The annotated roboflow dataset can be downloaded in a YOLOv8 compatible format as well. Transfer learning, was based on the yolov8s.pt weights, which are downloaded automatically. With the system installed correctly and the dataset dowloaded, a local GPU based training command might look like this:
Once the system was trained - download the “model wheights here”:[dragons.pt] - a bit of “glue code”:[rock_n_troll_v8.py] is needed. The python script needs to stream images from a camera, here via open cv, and detect dragons in each image. Every time a new dragon is found, the sound effect is played. Note that the Roboflow website automatically trains a model as well which can be tried out with a webcam.
There are a few ways improve the robustness of the system. During a game there are only more and more dragons: if the script detects less dragons than before it is probably a false negative or there is occlusion. Additionally, the dragon tiles remain in the same location once they are placed on the board. This means that new dragons are expected only in certain regions of the image. Both heuristics can be used to together to improve robustness.
Notes
One of the reasons I bought a M1 mac with unified memory is for exactly these types of AI applications. After installing pytorch 2.0, the GPU acceleration resulted in a 10x training speed improvement. Training on a GeForce 1080 GTX from 2016 was still quite a bit faster, probably thanks to years of performance tuning targeting CUDA. It is clear that the mac GPU acceleration software ecosystem can use more effort, even system tools in macOS are limited: e.g. in the macOS activity monitor, GPU activity is very much an afterthought.
I am and hesitant to use cloud based GPU computing due to lack of control and privacy. I am not willing to send pictures from my kids to e.g. Google Cloud GPUs. The dependency on hardware of others might also limit the longevity of systems.
The ease-of-use, performance and accessibility of these deep-learning systems is great. Only a couple of years ago it would take months of hard work to maybe only approach similar detection performance. Adapting this idea for other board games and more types of tiles or board game events should be very possible.



 \
\




