Elektor, a hobby electronics magazine, recently featured an article on acoustic fingerprinting using the ESP32. It is included in a special edition on Espressive products like the ESP32. This article includes content previously published on this blog and other writings about Olaf.
Since the article is based on my writings, there was an agreement to allow one of their writers to compose the magazine article under my name. This was my first experience with having a ghostwriter – quite convenient, I must say. Although it’s somewhat apparent that the article is compiled from various sources, I am overall pleased with the outcome. It even made the front page!
Elektor has a rich history, dating back to the early 1960s when it was first published in Dutch as ‘Elektuur’. I have fond memories of browsing Elektuur at my nerdy uncle’s place. If anything, this article has certainly earned me some nerd credibility points in my uncle’s eyes.
The Web Audio API offers some great functionality for web based audio applications. The API also has a couple of quirks and is not always easy to use. One of those quirks is the limited support for resampling audio. When requesting a microphone stream of a certain sample rate the API only allows configurations your hardware supports. Ideally there should be an option to resample the incoming stream to a requested sample rate (and format) independent of hardware.
On macOS and Chrome the issue becomes even more confusing: when using multiple AudioContexts they can only have the same sample rate. E.g. starting a microphone on 16kHz by itself is possible but not when there is also audio playback on the same page, then everything switches over to 48kHz. There even seems to be an effect of different browser tabs. Other browsers and platforms have similar issues. This is problematic when you need audio in a fixed sample rate.
The solution is to resample audio incoming samples in your code or use the OfflineAudioContext as a resampler. The OfflineAudioContext way needs a lot of code and, crucially, only works on the main browser thread and not in an AudioWorklet. The AudioWorklet should be the place for computationally intensive audio processing like resampling. To solve the resampling problem I have glued together an AudioWorklet and libsamplerate-js to provide an easy to use audio resampling solution which is demo’d below:
The demo does not seem to do much but it reads incoming microphone data and uses a high quality audio resampling library to resample an audio stream into a requested audio sampling rate. The browser development console shows some info on this process. To get this working in an audio worklet, the libsamplerate-js needed to be recompiled and directly included in the AudioWorklet. To inspect the source, check the “Web Audio API AudioWorklet resampler”:[web-audio-api-resample.zip].
The recent version of the OLAF (Overly Lightweight Acoustic Fingerprinting) audio fingerprinting system also includes an updated WASM build which deserves a bit more attention.
The browser version of Olaf enables audio fingerprinting in the browser. This can be used to e.g. react to music playing in the environment, so called second screen applications or to synchronize several devices to an audio stream.
The goal of the demo below is to play music aloud - not using headphones - using the controls on the left. You can either play the reference track or an unrelated distractor. Next, the Olaf fingerpinter system needs to be started using the button on the right which captures the microphone of your device. Then Olaf tries match the incoming sound of the microphone and the reference track. Once a match is found the exact time in the match is displayed until the sound matches no more. Note that there is no direct information flowing between the left and right part. You can also play the reference on another device to be sure.
Reference:
\
Distractor:
To get this demo working with the Web Audio API and use AudioWorklet objects, to process audio in the background an not on the main browser thread. There is surprisingly little info to find on how to combine WASM libraries - I used both Olaf and libsamplerate-js - and the AudioWorklet environment. Thanks to one of the very few resources on combining WASM, emscripten and AudioWorklets led me in the right direction.
Getting MEMS microphones to work on microcontroller platforms as the ESP32 is challenging. In theory, the I2S protocol provides a standardised, easy way to receive audio from a microphone and send stereo audio to a DAC. In practice, the many parameters make I2S not straightforwards to use. As with most protocols and standards, the mismatch between limitations and quirks of specific hardware and software implementations can cause issues. To debug I2S microphones on ESP32 or the RP2040 I have prepared a small Arduino program.
The IS2 WiFi microphone program sends audio from the microphone over WiFi to a computer which listen to the microphone: this make sure that the microphone works as expected and audio samples are correctly interpreted. It validates the I2S settings like buffer sizes, sample rates, audio formats, stereo or mono settings, … After configuring an SSID, password and IP-address it becomes possible to listen — in real-time — to the microphone which also allows the listener to sense the microphone quality.
size_t bytesIn = 0;
esp_err_t result = i2s_read(I2S_PORT, &sBuffer, bufferLen, &bytesIn, portMAX_DELAY);
int16_t *sample_buffer = (int16_t *)sBuffer;
int16_t samples_read = bytesIn / 2;
float audio_block_float[samples_read];
for (size_t i = 0; i < samples_read; i++) {
sample_buffer[i] = gain_factor * sample_buffer[i];
// Max for signed int16_t is 2^15
audio_block_float[i] = sample_buffer[i] / 32768.f;
}
// Send raw audio 32bit float samples over UDP
Udp.beginPacket(outIp, outPort);
Udp.write((const uint8_t *)audio_block_float, bytesIn * 2);
Udp.endPacket();
Fig: The main part of reading i2s audio from a microphone and sending an UDP packet.
To listen to the incoming audio an UDP port needs to be captured and subsequently send to a program that can interpret and play or store audio. With netcat UDP data can be captured. With ffmpeg and ffplay audio can be payed or stored. In practice the receiving computer might run the following commands to decode UDP packages and hear the microphone:
# for playback, receive UDP packages and interpret raw audio
nc -l -u 3000 | ffplay -f f32le -ar 16000 -ac 1 -
# for playback, receive UDP packages and store in a wav file
nc -l -u 3000 | ffmpeg -f f32le -ar 16000 -ac 1 -i pipe: microphone.wav
Olaf is an acoustic fingerprinting system designed with embedded devices in mind. It has a low memory use and computational requirements which are compatible with e.g. the ESP32 line of microcontrollers devices like the SparkFun ESP32 Thing or devices based on the RP2040 chip. Recently I have prepared a demo with the newest version of Olaf running on an ESP32 which deserves some attention.
To match audio, Olaf needs access to streaming audio. This can be audio read from an SD-card but, more likely, audio comes from a microphone. Digital microphones have some great features: a low-noise floor, great at picking up omnidirectional sound and they are inexpensive. I have prepared a demo of Olaf which shows how to use Olaf on an ESP32 with an INMP441 MEMS microphone. To test the MEMS microphone I also made a MEMS microphone to WiFi program which sends incoming sound on the ESP32 over WiFi to a computer where the sound quality can be verified.
The example provides a scaffold for embedded music-reactive applications. Once the microcontroller knows which song is playing and where in the song the match is found it can trigger LED’s (or explosions, fireworks, lyrics, other effects…) which should happen in sync with the music. See the example below to get the idea, this demo runs an older version of Olaf but the idea stays the same:
The main difference between the current and previous versions of Olaf is that now the ESP32 version, the browser version and the PC version are all running the exact same code. No hacks are needed any more to support a platform. This means that testing and debugging can be done on a computer and, if everything goes well, the code should work as expected on the embedded device (or browser).
I have just released a Python wrapper for the Olaf acoustic fingerprinting library. Olaf is a scalable audio search system based on indexing . Olaf is programmed in C but a wrapper now makes its functionality available in Python.
The python wrapper should make it more accessible for developers to get started with it and makes it compatible with other Python libraries. A few notable libraries are the librosa python package for music and audio analysis,nnAudio, A fast GPU audio processing toolbox and other more general plotting, data processing and machine learning libraries. Despite Python’s many flaws, its rich library ecosystem is unmatched.
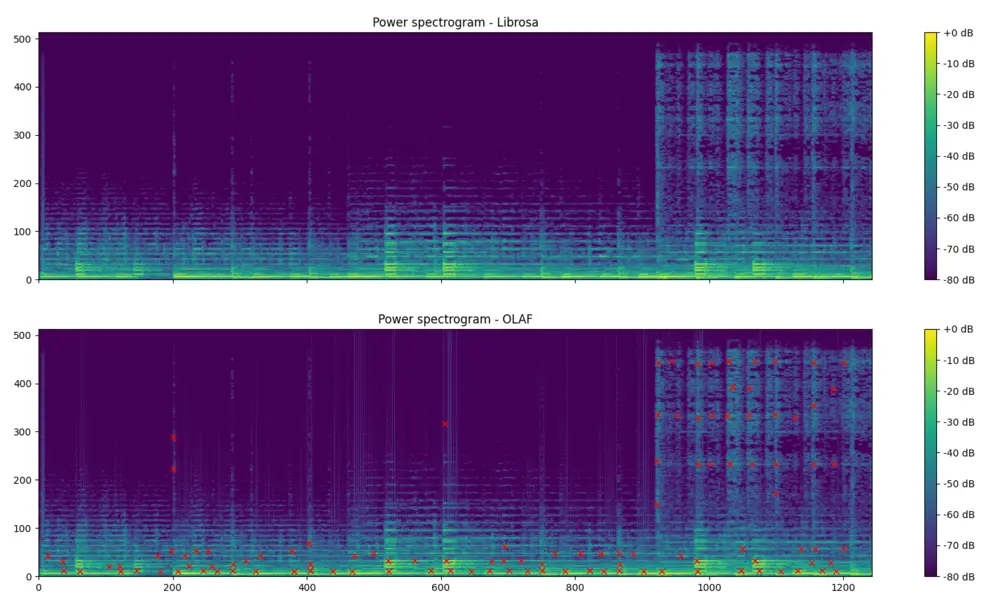
The associated GitHub repository contains documentation on how to use the Olaf python wrapper and also contains examples. The first shows how to index a song into the database and subsequently query the database. The second visualises the event points extracted by Olaf. The figure below shows shows the resulting event points, extracted with Olaf, plotted on a magnitude spectrogram, calculated with Olaf. The spectrogram on top is calculated using librosa and is meant to be very similar to Olaf.
\
Fig: *A power spectrum from librosa and one from Olaf, with event points marked*.
The wrapper was made with Python CFFI which works reasonably well. The automatically generated wrapper library support a large part of the C language but it needs a compilation step for each platform. Currently, the instructions assume a POSIX-like system, but technically, the wrapper can also function on Windows, albeit with the potential need for Windows-equivalent instructions in place of certain POSIX ones. The wrapper is wrapped in an easy to use python class called Olaf.py:
```python\
from olaf import Olaf, OlafCommand\
import librosa
Store the first ten seconds of an audio file\
audio_file = librosa.ex(‘choice’)\
Olaf(OlafCommand.STORE,audio_file).do(duration=10.0)
Query for a part of the same file (with an offset of 7 seconds), but change volume\
y, sr = librosa.load(audio_file,mono=True, sr=16000,duration=10,offset=7.0)\
y = y * 0.8 #change the volume\
results = Olaf(OlafCommand.QUERY,audio_file).do(y=y)
We expect a match between the stored and partially overlapping query\
print(results)\
```
The Wall Street Journal made a video on the internals Shazam fingerprinter. The visuals and technical explanation serves as a very good introduction in spectral-peak-based audio fingerprinting. For those who want a more in depth view or want to try out such systems: I have implemented extensions on the Shazam technique in two open-source systems.
Olaf is a spectral-peak based fingerprinter aimed at embedded systems, traditional computers and browsers. Panako is implemented in Java and has robustness against pitch-shifting and time-stretching which is briefly mentioned in the video below as well:
Both Ghent University’s research output tracking system and Flanders FWO academic profile do not allow to enter software as research output. The focus is still solely on papers, even when custom developed research software has become a fundamental aspect in many research areas. My role is somewhere between that of a ‘pure’ researcher and that of a research software engineer which makes this focus on papers quite relevant to me.
The paper aims to make the recent development on Olaf‘count’. Thanks to the JOSS review process the Olaf software was improved considerably: CI, unit tests, documentation, containerization,… The paper was a good reason to improve on all these areas which are all too easy to neglect. The paper itself is a short, rather general overview of Olaf:
“Olaf stands for Overly Lightweight Acoustic Fingerprinting and solves the problem of finding short audio fragments in large digital audio archives. The content-based audio search algorithm implemented in Olaf can identify a short audio query in a large database of thousands of hours of audio using an acoustic fingerprinting technique.”
The C programming language is deceptively simple. The syntax is straightforward, C has a limited amount of keywords and a small standard library. The first edition of the classic book ‘The C Programming Language’ is only about 200 pages. And yet, when programming in C, it is hard to avoid the many exiting footguns: integer type conversions, unchecked indexes and memory leaks can all cause subtle problems. This is part of the appeal of C: shooting yourself in the foot does make you feel alive. Here I want to focus on ways to check for memory leaks for C programs.
Memory leaks come about when memory is claimed but is never released again. If this is done in a loop or during a long running program, the claimed memory adds up and eventually the system may run out of memory. A memory leak is less a problem if a program forgets to free a small amount of memory it only claims once: after program shut down, the operating system reclaims all memory anyhow. However, it does feels very dirty to not clean up after oneself. And I for one, am not a dirty boy.
Another reason to look for memory use and leaks is when you are programming for embedded devices. For these systems memory is very limited: in that world 500kB RAM is considered a massive amount of memory. I have been busy programming a scalable audio search system called Olaf which targets both traditional computers, embedded systems and browsers (via WebAssembly). It is clear that memory use — and memory leaks — need to be kept in check to pull this of.
Now, these memory leaks might not be easy to spot by inspecting the code. There are tools which help to spot memory management problems. One of these is valgrind which is currently not easy to use on Apple system with ARM processors. Luckily there is an alternative which is probably already installed on macOS via the XCode Command Line Tools a command line tool aptly called leaks. To quote the apple documentation on leaks, leaks reports:
the address of the leaked memory
the size of the leak (in bytes)
the contents of the leaked buffer
The most straightforward use of leaks is to run a program and generate a report after program shutdown. See below to run a memory leak inspection, in this case for the bin/olaf_c program which indexes an audio file in a key-value store. For CI purposes it is practical to know that leaks has an exit status of zero only when no leaks have been found. The exit status can be used in an automated test script to break a build if a leak is detected. The --quiet option can be practical in such setting.
leaks --atExit -- bin/olaf_c store audio.raw audio
In the case of Olaf I made a classic mistake: I had called free() on hash table but I needed to call the hash table destructor: hash_table_destroy() which freed not only the hash table itself but also all memory associated with the hash table entries. After a quick fix the leaks command showed no more leaks!
Output of the `leaks` command which shows where a memory leak can be found.
General takaways
leaks is an easy to use memory leak inspector provided by Apple. It is an alternative for valgrind.
Memory leaks can be checked automatically using the leaks exit status in a CI-script. This makes spotting leaks timely and more straightforward to fix.
Programmers should at least once try to target embedded devices. It makes you conscious of the wealth of resources available when targeting modern computing devices.
This post details how I went about optimizing a C application. This is about an audio search system called Olaf which was made about 10 times faster but contains some generally applicable steps for optimizing C code or even other systems. Note that it is not the aim to provide a detailed how-to: I want to provide the reader with a more high-level understanding and enough keywords to find a good how-to for the specific tool you might want to use. I see a few general optimization steps:
The zeroth step of optimization is to properly **question the need** and balance the potential performance gains against added code complexity and maintainability.
Once ensured of the need, the first step is to **measure the systems performance**. Every optimization needs to be measured and compared with the original state, having automazation helps.
Thirdly, the second step is to **find performance bottle necks**, which should give you an idea where optimizations make sense.
The third step is to **implement and apply** an optimization and measuring its effect.
Lastly, **repeat** steps zero to three until optimization targets are reached.
More specifically, for the Olaf audio search system there is a need for optimization. Olaf indexes and searches through years of audio so a small speedup in indexing really adds up. So going for the next item on the list above: measure the performance. Olaf by default reports how quickly audio is indexed. It is expressed in the audio duration it can process in a single second: so if it reports 156 times realtime, it means that 156 seconds of audio can be indexed in a second.
The next step is to find performance bottlenecks. A profiler is a piece of software to find such bottle necks. There are many options gprof is a command line solution which is generally available. I am developing on macOS and have XCode available which includes the “Instruments - Time Profiler”. Whichever tool used, the result of a profiling session should yield the time it takes to run each functions. For Olaf it is very clear which function needs optimization:
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
The function is a max filter which is ran many, many times. The implementation is using a naive approach to max filtering. There are more efficient algorithms available. In this case looking into the literature and implementing a more efficient algorithm makes sense. A very practical paper by Lemire lists several contenders and the ‘van Herk’ algorithm hits the sweet spot between being easy to implement and needing only a tiny extra amount of memory. The Lemire paper even comes with example c max-filters. With only a slight change, the code fits in Olaf.
After implementing the change two checks need to be done: is the implementation correct and is it faster. Olaf comes with a number of functional and unit checks which provide some assurance of correctness and a built in performance indicator. Olaf improved from processing audio 156 times realtime to 583 times: a couple of times faster.
After running the profiler again, another method came up as the slowest:
//Naive implementationfloat olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
float max = -10000000;
for (size_t i = 0; i < array_size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
src: naive implementation of finding the max value of an array.
This is another part of the 2D max filter used in Olaf. Unfortunately here it is not easy to improve the algorithmic complexity: to find the maximum in a list, each value needs to be checked. It is however a good contender for SIMD optimization. With SIMD multiple data elements are processed in a single CPU instruction. With 32bit floats it can be possible to process 4 floats in a single step, potentially leading to a 4x speed increase - without including overhead by data loading.
Olaf targets microcontrollers which run an ARM instruction set. The SIMD version that makes most sense is the ARM Neon set of instructions. Apple Sillicon also provides support for ARM Neon which is a nice bonus. I asked ChatGPT to provide a ARM Neon improved version and it came up with the code below. Note that these type of simple functions are ideal for ChatGPT to generate since it is easily testable and there must be many similar functions in the ChatGPT training set. Also there are less ethical issues with ‘trivial’ functions: more involved code has a higher risk of plagiarization and improper attribution. The new average audio indexing speed is 832 times realtime.
src: a ARM Neon SIMD implementation of a function finding the max value of an array, generated by ChatGPT, licence unknown, informed consent unclear, correct attribution impossible.
Next, I asked ChatGPT for an SSE SIMD version targeting the x86 processors but this resulted in noticable slowdown. This might be related to the time it takes to load small vectors in SIMD registers. I did not pursue the SIMD SSE optimization since it is less relevant to Olaf and the first performance optimization was the most significant.
Finally, I went over the code again to see whether it would be possible exit a loop and simply skip calling olaf_ep_extractor_max_filter_time in most cases. I found a condition which prevents most of the calls without affecting the total results. This proved to be the most significant speedup: almost doubling the speed from about 800 times realtime to around 1500 times realtime. This is actually what I should have done before resorting to SIMD.
In the end Olaf was made about ten times faster with only two local, testable, targeted optimizations.
General takeways
Only think about optimization if there is a need and set a target: otherwise it is infinite.
Try to find a balance between complexity, maintainability and performance.
Changing a naive algorithm to a more intelligent one can have a significant performance increase. Check the literature for inspiration.
Check for conditions to skip hot code paths before trying fancy optimization techniques.
Profilers are crucial to identify where to optimize your code. Applying optimizations blindly is a waste of time.
Try to keep optimizations local and testable. Sprinkling your code with small, hard to test performance oriented improvements might not be worthwile.
SIMD generated by ChatGPT can be a very quick way to optimize critical, hot code paths. I would advise to only let ChatGPT generate small, common, easily testable code: e.g. finding the maximum in an array.
I have updated Olaf - the Overly Lightweight Acoustic Fingerprinting system. Olaf is a piece of technology that uses digital signal processing to identify audio files by analyzing unique, robust, and compact audio characteristics - or “fingerprints”. The fingerprints are stored in a database for efficient comparison and matching. The database index allows for fast and accurate audio recognition, even in the presence of distortions, noise, and other variations.
Olaf is unique because it works on traditional computing devices, embedded microprocessors and in the browser. To this end tried to use ANSI C. C is a relatively small programming language but has very little safeguards and is full of exiting footguns. I enjoy the limitations of C: limitations foster creativity. I also made ample use of the many footguns C has to offer: buffer overflows, memory leaks, … However, with the current update I think most serious bugs have been found. Some of the changes to Olaf include:
Fixed a rather nasty array out of bounds bug. The bug remained elusive due to the fact that a segfault was rare on macOS. Linux seems to be more diligent in that regard.
Added a quick way to skip already indexed files. Which improves usability significantly when working with larger datasets.
Improved command line output and fixed incorrectly reported times. The reported start and stop time of a query was wrong and is now fixed.
Olaf now supports caching fingerprints in simple text files. This makes fingerprint extraction much faster since all cores of the system can be used to extract fingerprints and dump them to text files. Writing prints to the database from multiple threads is slow since they need to wait for access to the locked database. There is also a command to store all cashed fingerprints in a single go.
Added support for basic profiling with gprof. The profiler shows where optimizations can have the most impact.
Olaf now includes an algorithm for efficient max-filtering. The min-max filter algorithm by Daniel Lemire is implemented. The profiler showed that most time was spend during max-filtering: replacing the naive max-filter with the Lemire max-filter improved performance drastically.
CI with Github Actions which checks if checked in sources compile and tests some of the basic functionality automatically.
Updated the Zig build script for cross-compilation and updated the pre-build Windows version.
Tested the system with larger databases. The FMA-full datasets, which comprises almost a full year of audio was indexed and queried without problems on a single pc. The limits of Olaf with respect to indexed size is probably a few times larger.
Tested, fixed and improved the ‘memory database’ version. Also added documentation to the readme.
Made a basic web example to call the WASM version of Olaf.
Added an ESP32 example, showing how Olaf can run on this microprocessor. It runs without an external microphone but uses a test audio file. Previously some small changes were needed to Olaf to run on the ESP32, now the exact same code is used.
Anyhow, what originally started as a rather quick and dirty hack has been improved quite a bit. The takeaway message: in the world of software it does seem possible to polish a turd.
Panako is an acoustic fingerprinting system I developed a couple of years ago. With acoustic fingerprinting systems it is possible to find duplicates in digital music archives and compare meta-data or identify unlabelled audio fragments. In the margins of my post-doc project working with large music archives, I have found the time to update Panako significantly. The updates simplify, improve and speed up Panako.
\
Fig. General content based audio search scheme.
The main algorithms are simplified. There is also a reduction of dependencies and a refocus to core functionality. This also simplifies building the software. The retrieval characteristics are improved, mainly thanks to the use of a fine-grained Gabor transform. Also new is the near-exact hashing construct which helps with off-by-one issues when matching time bins. The key-value store used is now LMDB, which speeds up the query performance of Panako significantly. The updates should make Panako stand the test of time somewhat better.
\
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.
- The number of dependencies has been drastically cut by removing support for multiple key-value stores.
- The key-value store has been changed to a faster and simpler system (from [MapDB](https://mapdb.org) to [LMDB](http://www.lmdb.tech/doc)).
- The SyncSink functionality has been moved to another project (with Panako as dependency).
- The main algorithms have been replaced with simpler and better working versions:
- Olaf is a new implementation of the classic Shazam algorithm.
- The algoritm described in the Panako paper was also replaced. The core ideas are still the same. The main change is the use of a [Gabor transform](https://en.wikipedia.org/wiki/Gabor_transform) to go from time domain to the spectral domain (previously a constant-q transform was used). The gabor transform is implemented by [JGaborator](https://github.com/JorenSix/JGaborator) which in turn relies on [The Gaborator](https://gaborator.com/) C library via JNI.
- Folder structure has been simplified.
- The UI which was mainly used for debugging has been removed.
- A new set of helper scripts are added in the `scripts` directory. They help with evaluation, parsing results, checking results, building panako, creating documentation,...
- Changed the default panako location to \~/.panako, so users can install and use panako more easily (without need for sudo rights)
From 11-16 October 2020 the latest instalment of the ISMIR conference series was held. Due to the pandemic, the 21st ISMIR conference was the first virtual one. As usual, participants and presenters from around the world joined the conference. For the first time, however, not all participants synchronised their circadian rhythm. By repeating most events with 12h in between, the organisers managed to put together a schedule befitting nearly all participants.
The virtual format had some clear advantages: travel was not needed, so (environmental) cost was low. Attendance fees were lower than usual since no spaces or catering was needed. This democratised the conference experience and attendance reached a record high.
A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.
The prototype gathered dust for a while but the idea stuck in my head. With my daughters fourth birthday approaching during the lockdown, I decided to turn the prototype into an over-engineered birthday gift and let an ‘Elsa-dress’ react to ‘Let It Go’ from the Frozen soundtrack. With the prototype as a starting point, I ordered an RGB-LED-strip, a beefy Li-Ion Battery, an I2S digital microphone and, of course, an Elsa-dress.
I had an ESP32 microcontroller laying around and used it as the core of the system: it supports I²S, has a floating point unit (FPU), is easy to use together with LED strips and has enough memory. The FPU makes it straightforward to use the same code on traditional computers as on embedded devices: fixed-point math can be avoided.
After soldering the components together and with the help from my better half to sew in the LED strip, it all came together. In the video below, the result of our work can be seen. The video first shows a song that should not and is not recognised. Then, “Let It Go” is played and correctly recognised. After the song is stopped, the lights go on for a while and finally stop: this is by design to allow gaps in recognition. Lastly, the song is continued and again correctly recognised.
With my limited C experience the prototype code was not well organised. During my second attempt this improved enough so that I feel comfortable enough to share the code on GitHub: Olaf - Overly Lightweight Acoustic Fingerprinting.
The code went through several iterations and was expanded beyond the original scope and became a capable general purpose acoustic fingerprinting system with its many applications. Olaf performs quite well thanks to its resource friendly design and the use of PFFT and LMDB. Especially LMDB, a fast, B+-tree backed key value store with low storage overhead enables performant storage and lookups.
The GitHub does not contain an example for the ESP32. That code depends on the microcontroller, digital microphone and pins used and Olaf needs to be hacked to exhibit the requested behaviour. All in all that code is much less reusable (and sharable, testable, maintainable). I have, however, included a platformIO project for “Olaf on ESP32”:[ESP32-Olaf.zip] for reference.
WASM: Olaf in the browser
Olaf, being written in ANSI C, can run in the browser thanks to the Emscripten compiler. According to its website, Emscripten ‘…lets you run C and C on the web at near-native speed without plugins’ Combining the Web Audio API and the WASM version of Olaf makes web-based acoustic fingerprinting applications possible.
Below you can try out Olaf. The exact same code is running on your browser as on the ESP32 demonstrated above. This means that Olaf is listening to recognise ‘Let It Go’ from the Frozen soundtrack. For your convenience the song can be started below on the left. On the right, you can start Olaf by allowing incoming audio to be analysed. The FFT is calculated by Olaf and visualised using Pixi.js. After a few seconds the red fingerprints should become green, indicating a match. Once you stop the song, the fingerprints will eventually turn red again. As with the video above: going from a match to no match takes a couple of seconds to allow gaps in recognition.
1. Start the song and play it aloud. Singing along is encouraged.
2. Start the microphone and check whether recognition succeeds.
Olaf was featured on hackaday. There is also a small discussion about Olaf on Hacker News. A write-up of this project also ended up as a contribution to the Late Breaking Demo track of the first virtual ISMIR conference: Olaf ISMIR 2020 LBD abstract.






 \
\
 Fig: Some AI imagining audio search.
Fig: Some AI imagining audio search.



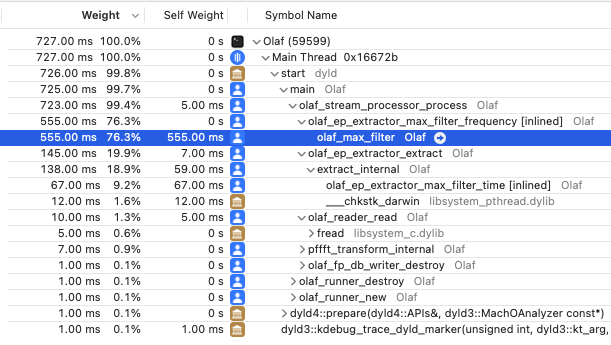 \
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.



 \
Fig. General content based audio search scheme.
\
Fig. General content based audio search scheme.
 \
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.
\
Fig. The top one true positive rate for 20s query fragments. The audio playback is speed modified from 84 to 116% with respect to the indexed reference audio. The original query length is 20s, if it is slowed down by 10% it takes, evidently, 22s. Note the improvement of the 2021 version of Panako (blue) vs the 2014 version (light-gray). As a baseline the standard algorithm (wang 2003) is included as well. For the 2021 Panako algorithm, audio recognition performance suffers (below 80) when playback speed is changed more than 10.

 A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.
A good year ago I was asked to develop audio recognition technology for an e-costume. The idea was that lights in the costume would follow a sequence synchronised to a certain song. Only a single song should trigger the lights, all other music should be ignored. Recognition of music and synchronisation is typically done using audio fingerprinting techniques. The challenge was that the recognition needed to run on a cheap, battery-powered microcontroller with limited CPU and memory. I delivered a prototype but eventually a cheap, battle-tested, off-the-shelf, IP-cleared, alternative was found.