Hi, I'm Joren. Welcome to my website. I'm a research software engineer in the field of Music Informatics and Digital Humanities. Here you can find a record of my research and projects I have been working on. Learn more »
Thursday the 3th of May I gave a guest lecture titled ‘Ethnic Music Analysis: Challenges & Opportunities’ it featured Tarsos as a Case Study. The goal was to identify the difficulties when dealing with ethnic music and to show a possible approach, the approach implemented by Tarsos.
The invitation to give the guest lecture came from Michael Cuthbert who is one of the driving forces behind music21. The audience was a small group of double majors in both musicology and computer science: the ideal profile to gather useful feedback.
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
The Dan Ellis implementation is nicely documented here: Robust Landmark-Based Audio Fingerprinting . To download, get info about and decode mp3’s some external binaries are needed:
```bash\
#install octave if needed\
sudo apt-get install octave3.2\
#Install the required dependencies for the script\
sudo apt-get install mp3info curl
mpg123 is not present as a package, install from source:\
wget http://www.mpg123.de/download/mpg123-1.13.5.tar.bz2\
tar xvvf mpg123-1.13.5.tar.bz2\
cd mpg123-1.13.5/\
./configure\
make\
sudo make install\
```
In mp3read.m the following code was changed (line 111 and 112):
```matlab\
mpg123 = ‘mpg123’; % was fullfile(path,[‘mpg123.’,ext]);\
mp3info = ‘mp3info’; % was fullfile(path,[‘mp3info.’,ext]);\
```
Then, the demo program runs flawlessly when executing octave -q demo_fingerprint.m.
Running the demo with the original code with GNU Octave, version 3.2.3 takes 152 seconds on a PC with a Q9650 @ 3GHz processor. A small tweak can make it run almost 8 times faster. When working with larger data sets (10k audio files) this makes a big difference. I do not know why but storing a hash in the large hash table was really slow (0.5s per hash, with 900 hashes per song…). Caching the hashes and adding them all at once makes it faster (at least in Octave, YMMV). The optimized version of “record_hashes.m”:[record_hashes.m.txt] can be found attached. With this alteration the same demo ran in 20s. When caching the data locally the difference is 11.5s to 141s or 12 times faster. The code with all the changes can be found here: “Robust Landmark-Based Audio Fingerprinting - optimized for Octave 3.2”:[fingerprint_fast.zip]. Please note again that the implementation is done by Dan Ellis (2009) ( available on Robust Landmark-Based Audio Fingerprinting) and I did only some small tweaks.
The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was Harmony and variation in music information retrieval.
During the talk by Xavier Serra rasikas.org was mentioned a forum with discussions about Carnatic Music. Since I could find a couple of discussions about pitch use on that forum I plugged Tarsos there to see if I could gather some feedback.
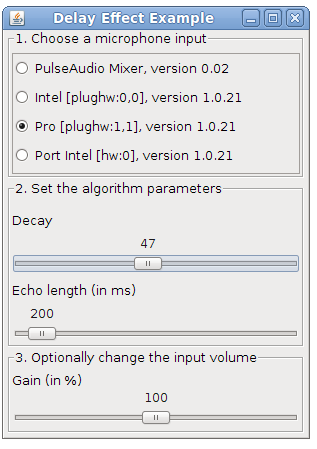
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of an audio echo effect. An echo effect is very simple to implement digitally and can serve as a good example of a DSP operation.
"":\[Delay.jar\]
The implementation of the effect can be seen below. As can be seen, to achieve an echo one simply needs to mix the current sample i with a delayed sample present in echoBuffer with a certain decay factor. The length of the buffer and the decay are the defining parameters for the sound of the echo. To fill the echo buffer the current sample is stored (line 4). Looping through the echo buffer is done by incrementing the position pointer and resetting it at the correct time (lines 6-9).
```java\
//output is the input added with the decayed echo\
audioFloatBuffer[i] = audioFloatBuffer[i] + echoBuffer[position] * decay;\
//store the sample in the buffer;\
echoBuffer[position] = audioFloatBuffer[i];\
//increment the echo buffer position\
position;\
//loop in the echo buffer\
if(position == echoBuffer.length)\
position = 0;\
```
To test the application, download and execute the “Delay.jar”:[Delay.jar] file and start singing in a microphone.
The source code of the Java implementation can be found on the TarsosDSP github page.
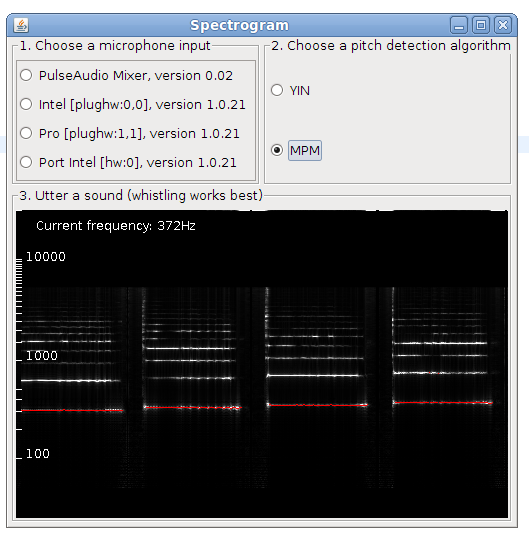
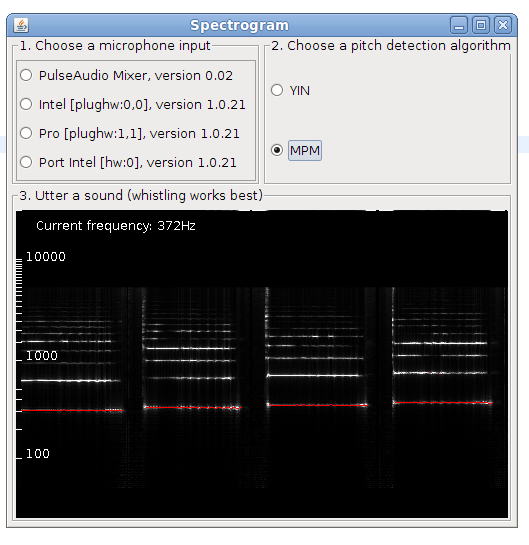
This is post presents a better version of the spectrogram implementation. Now it is included as an example in TarsosDSP, a small java audio processing library. The application show a live spectrogram, calculated using an FFT and the detected fundamental frequency (in red).
To test the application, download and execute the “Spectrogram.jar”:[Spectrogram.jar] file and start singing in a microphone.
There is also a command line interface, the following command shows the spectrum for in.wav:
\
java -jar Spectrogram.jar in.wav\
The source code of the Java implementation can be found on the TarsosDSP github page.
To test the application, download and execute the “WSOLA jar”:[TimeStretch.jar] file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command doubles the speed of in.wav:
\
java -jar TimeStretch.jar in.wav out.wav 2.0\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Time stretch utility.
----------------------------------------------------
Synopsis:
java -jar TimeStretch.jar source.wav target.wav factor
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the time stretched file.
factor Time stretching factor: 2.0 means double the length, 0.5 half. 1.0 is no change.
The source code of the Java implementation of WSOLA can be found on the TarsosDSP github page.
Tarsos contains a couple of useful command line applications. They can be used to execute common tasks on lots of files. Dowload Tarsos and call the applications using the following format:
The first part java -jar tarsos.jar tells the Java Runtime to start the correct application. The first argument for Tarsos defines the command line application to execute. Depending on the command, required arguments and options can follow.
To get a list of available commands, type java -jar tarsos.jar -h. If you want more information about a command type java -jar tarsos.jar command -h
Detect Pitch
Detects pitch for one or more input audio files using a pitch detector. If a directory is given it traverses the directory recursively. It writes CSV data to standard out with five columns. The first is the start of the analyzed window (seconds), the second the estimated pitch, the third the saillence of the pitch. The name of the algorithm follows and the last column shows the original filename.
 The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was
The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was