Hi, I'm Joren. Welcome to my website. I'm a research software engineer in the field of Music Informatics and Digital Humanities. Here you can find a record of my research and projects I have been working on. Learn more »
This year the ISMIR 2022 conference is organized from 4 to 9 December 2022 in Bengaluru, India. ISMIR is the main music technology and music information retrieval (MIR) conference. It is a relief to experience a conference in physical form and not through a screen.
I have contributed to the following work which is in the main paper track of ISMIR 2022:
BAF: An Audio Fingerprinting Dataset For Broadcast Monitoring (version of record)\
Guillem Cortès, Alex Ciurana, Emilio Molina, Marius Miron, Owen Meyers, Joren Six, Xavier Serra\
Abstract: Audio Fingerprinting (AFP) is a well-studied problem in music information retrieval for various use-cases e.g. content-based copy detection, DJ-set monitoring, and music excerpt identification. However, AFP for continuous broadcast monitoring (e.g. for TV & Radio), where music is often in the background, has not received much attention despite its importance to the music industry. In this paper (1) we present BAF, the first public dataset for music monitoring in broadcast. It contains 74 hours of production music from Epidemic Sound and 57 hours of TV audio recordings. Furthermore, BAF provides cross-annotations with exact matching timestamps between Epidemic tracks and TV recordings. Approximately, 80% of the total annotated time is background music. (2) We benchmark BAF with public state-of-the-art AFP systems, together with our proposed baseline PeakFP: a simple, non-scalable AFP algorithm based on spectral peak matching. In this benchmark, none of the algorithms obtain a F1-score above 47%, pointing out that further research is needed to reach the AFP performance levels in other studied use cases. The dataset, baseline, and benchmark framework are open and available for research.
I have also presented a first version of DiscStitch, an audio-to-audio alignment algorithm. This contribution is in the ISMIR 2022 late breaking demo session:
DiscStitch: towards audio-to-audio alignment with robustness to playback speed variabilities (version of record)\
Joren Six\
Abstract: Before magnetic tape recording was common, acetate discs were the main audio storage medium for radio broadcasters. Acetate discs only had a capacity to record about ten minutes. Longer material was recorded on overlapping discs using (at least) two recorders. Unfortunately, the recorders used were not reliable in terms of recording speed, resulting in audio of variable speed. To make digitized audio originating from acetate discs fit for reuse, (1) overlapping parts need to be identified, (2) a precise alignment needs to be found and (3) a mixing point suggested. All three steps are challenging due to the audio speed variabilities. This paper introduces the ideas behind DiscStitch: which aims to reassemble audio from overlapping parts, even if variable speed is present. The main contribution is a fast and precise audio alignment strategy based on spectral peaks. The method is evaluated on a synthetic data set.
Next to my own contributions, the ISMIR conference program is the best overview of the state-of-the art of MIR.
This contribution was made possible thanks to travel funds by the FWO travel grant K1D2222N and the Ghent University BOF funded project PaPiOM.
The research output tracking system of Ghent University (biblio) and Flanders FWO’s academic profile are not built to track software as research output. The focus is still solely on papers, even when custom developed research software has become a fundamental aspect in many research areas. My role is somewhere between that of a ‘pure’ researcher and that of a research software engineer which makes this focus on papers quite relevant to me.
The paper aims to make the recent development on Panako‘count’. Thanks to the JOSS review process the Panako software was improved considerably: CI, unit tests, documentation, containerization,… The paper was a good reason to improve on all these areas which are all too easy to neglect. The paper itself is a short, rather general overview of Panako:
“Panako solves the problem of finding short audio fragments in large digital audio archives. The content based audio search algorithm implemented in Panako is able to identify a short audio query in a large database of thousands of hours of audio using an acoustic fingerprinting technique.”
I have been lucky to have been involved in an interdisciplinary research project around the low impact runner: a music based bio-feedback system to reduce tibial shock in over-ground running. In the beginning of October 2022 the PhD defence of Rud Derie takes place so it is a good moment to look back to this collaboration between several branches of Ghent University: IPEM , movement and sports science and IDLab.
The idea behind the project was to first select runners with a high foot-fall impact. Then an intervention would slightly nudge these runner to a running style with lower impact. A lower repetitive impact is expected to reduce the chance on injuries common for runners. A system was invented in which musical bio-feedback was given on the measured impact. The schema to the right shows the concept.
I was involved in development of the first hardware prototypes which measured acceleration on the legs of the runner and the development of software to receive and handle these measurement on a tablet strapped to a backpack the runner was wearing. This software also logged measurements, had real-time visualisation capabilities and allowed remote control and monitoring over the network. Finally measurements were send to a Max/MSP sonification engine. These prototypes of software and hardware were replaced during a valorization project but some parts of the software ended up in the final Android application.
Video: the left screen shows the indoor positioning system via UWB (ultra-wide-band) and the right screen shows the music feedback system and the real time monitoring of impact of the runner. Video by Pieter Van den Berghe
Over time the first wired sensors were replaced with wireless Bluetooth versions. This made the sensors easy to use and also to visualize sensor values in the browser thanks to the Web Bluetooth API. I have experimented with this and made two demos: a low impact runner visualizer and one with the conceptual schema.
Vid: Visualizing the Bluetooth Low Impact Runner sensor in the browser.
The following three studies shows a part of the trajectory of the project. The first paper is a validation of the measurement system. Secondly a proof-of-concept study is done which finally greenlights a larger scale intervention study.
Van den Berghe, P., Six, J., Gerlo, J., Leman, M., & De Clercq, D. (2019). Validity and reliability of peak tibial accelerations as real-time measure of impact loading during over-ground rearfoot running at different speeds. Journal of Biomechanics, 86, 238-242.
Van den Berghe, P., Lorenzoni, V., Derie, R., Six, J., Gerlo, J., Leman, M., & De Clercq, D. (2021). Music-based biofeedback to reduce tibial shock in over-ground running: A proof-of-concept study. Scientific reports, 11(1), 1-12.
Van den Berghe, P., Derie, R., Bauwens, P., Gerlo, J., Segers, V., Leman, M., & De Clercq, D. (2022). Reducing the peak tibial acceleration of running by music‐based biofeedback: A quasi‐randomized controlled trial. Scandinavian Journal of Medicine & Science in Sports
There are quite a number of other papers but I was less involved in those. The project also resulted in two PhD’s:
Motor retraining by real-time sonic feedback: understanding strategies of low impact running (2021) by Pieter Van den Berghe
Running on good vibes: music induced running-style adaptations for lower impact running (2022) by Rud Derie
I am also recognized as co-inventor on the low impact runner system patent and there are concrete plans for a commercial spin-off. To be continued…
I have created a web application to LTC.wasm decodes SMPTE timecodes from an LTC encoded audio signal.
To synchronize multiple music and video recordings a shared SMPTE timecode signal is often used. For practical purposes the timecode signal is encoded in an audio stream. The timecode can then be recorded in sync with microphone inputs or added to a video recording. The timecode is encoded in audio with LTC, linear timecode. A special decoder is needed to extract SMPTE timecode from the audio. This is exactly what the LTC.wasm application does.
Using the [web based SMTE decoder](https://0110.be/attachment/cors/ltc.wasm/ltc_decoder.html
Try out the SMPTE decoder with your own SMPTE files.
The advantage of the web-based version versus the command line ltc-tools is that it does not need to be installed separately and that ffmpeg decodes audio. This means that almost any multimedia format is supported automatically. The command line version only supports a limited number of audio formats.
I have built a tool for audio-to-audio alignment. It has applications for synchronization of media files. It works in the browser and you can synchronize your media files here with SyncSink.wasm. SyncSink.wasm does the following:
From an incoming media-file audio is extracted, downmixed to mono and and resampled. This is done with ffmpeg.audio.wasm a wasm version of ffmpeg.
For each audio track, fingerprints are extracted. These fingerprints reduce the the search space for alignment drastically.
Each list of fingerprints is aligned with the list of fingerprints from the reference. Resulting in a rough alignment
Cross correlation is done to refine the alignment resulting in sample accurate results.
Fig: media synchronization with audio-to-audio alignment.
It supports small time-scale adjustments of around 5%: audio alignment can still be found if audio speed differs a bit.
Some potential use cases where it might be of use:
To stitch partially overlapping audio recordings together resulting in a single long audio recording.
To synchronize multiple independent video recordings of the same event each with an audio recording of the environment.
To align a high quality microphone recording with video/low-quality audio recording of the same event. The low quality audio recorded with a camera can then be replaced with the high quality microphone audio.
Fig: stable diffusion imagining a networked music performance
This post describes how to send audio over a network using the ffmpeg suite. Ffmpeg is the Swiss army knife for working with audio and video formats. It is a command line tool that supports almost all audio formats known to man and woman. ffmpeg also supports streaming media over networks.
Here, we want to send audio recorded by a microphone, over a network to a single receiver on the other end. We are not aiming for low latency. Also the audio is going only in a single direction. This can be of interest for, for example, a networked music performance. Note that ffmpeg needs to be installed on your system.
The receiver - Alice
For the receiver we use ffplay, which is part of the ffmpeg tools. The command instructs the receiver to listen to TCP connections on a randomly chosen port 12345. The \?listen is important since this keeps the program waiting for new connections. For streaming media over a network the stateless UDP protocol is often used. When UDP packets go missing they are simply dropped. If only a few packets are dropped this does not cause much harm for the audio quality. For TCP missing packets are resent which can cause delays and stuttering of audio. However, TCP is much more easy to tunnel and the stuttering can be compensated with a buffer. Using TCP it is also immediately clear if a connection can be made. With UDP packets are happily sent straight to the void and you need to resort to wiresniffing to know whether packets actually arrive.
In this example we use MPEGTS over a plain TCP socket connection. Alteratively RTMP could be used (which also works over TCP). RTP , however is usually delivered over UDP.
The shorthand address 0.0.0.0 is used to bind the port to all available interfaces. Make sure that you are listening to the correct interface if you change the IP address.
The sender - Björn
Björn, aka Bob, sends the audio. First we need to know from which microphone to use. To that end there is a way to list audio devices. In this example the macOS avfoundation system is used. For other operating systems there are similar provisions.
ffmpeg -f avfoundation -list_devices true -i ""
Once the index of the device is determined the command below sends incoming audio to the receiver (which should already be listening on the other end). The audio format used here is MP3 which can be safely encapsulated into mpegts.
Note that the IP address 192.168.x.x needs to be changed to the address of the receiver. Now if both devices are on the same network the incoming audio from Bob should arrive at the side of Alice.
The tunnel
If sender and receiver are not on the same network it might be needed to do Network Addres Translation (NAT) and port forwarding. Alternatively an ssh tunnel can be used to forward local tcp connections to a remote location. So on the sender the following command would send the incoming audio to a local port:
The connection to the receiver can be made using a local port forwarding tunnel. With ssh the TCP traffic on port 12345 is forwarded to the remote receiver via an intermediary (remote) host using the following command:
LMDB is a fast key value store, ideal to store and query sorted data with small keys and values. LMDB is a pure C library but often used from other programming languages via some type of bindings. These bindings are ‘bridges’ between languages and are automatically present on supported platform. On new or unsupported platforms, however, you need to build a this bridge yourself.
This blog post is about getting java-lmdb working on such unsupported platform: arm64. The arm64 platform is much more popular since the introduction of the Apple silicon - M1 platform. On Apple M1 the default architecture of Docker images is also aarch64.
Next you need to build the lmdb library for your platform and copy it to a location where Java looks for it. This only works when compilers are already available on your system. In macOS you might need to install the XCode command line tools:
#xcode-select --install
git clone --depth 1 https://git.openldap.org/openldap/openldap.git
cd openldap/libraries/liblmdb
make -e SOEXT=.dylib
cp liblmdb.dylib ~/Library/Java/Extensions
On Debian aarch64 the procedure is similar but a different extension is used (.so):
#apt install build-essential
git clone --depth 1 https://git.openldap.org/openldap/openldap.git
cd openldap/libraries/liblmdb
make
mv liblmdb.so /lib
Finally, to use the library in a JAR-file is might be needed to allow lmdbjava to access some parts of the JRE:
I have been lucky to be part of a fruitful interdisciplinary scientific collaboration around AMPEL: ‘The Augmented Movement Platform For Embodied Learning’. The recent publication of an article is an ideal occasion to give a glimpse behind the scenes.
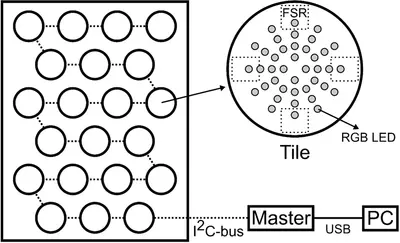
Fig: Schematic representation of AMPEL, a floor with interactive tiles.
Around 2016 the idea arose to search for new potential rehabilitation approaches for persons with multiple sclerosis. Multiple sclerosis causes problems, in varying degrees, with both motor and cognitive function. Common rehabilitation approaches either work on motor or cognitive function. The idea (by Lousin Moumdjian, Marc Leman, Peter Feys) was to combine both motor and cognitive rehabilitation in a single combined ‘embodied learning’ paradigm.
After some discussion we wanted to perform a combined short-term memory and walking task. First the participants would be presented with a target trajectory which would then be performed by walking. During walking we would modulate feedback types (melodic, sounds or visual). To this end, an ‘intelligent floor’ device was needed that was able to present a target trajectory, register a performed trajectory and provide several types of feedback. After a search for off-the-shelf solutions it became clear that a custom hard-and-software platform was required.
After a great deal of cardboard prototyping we settled on a design consisting of interactive tiles. Thomas Vervust of UGhent NamiFab designed a PCB with force sensitive resistors (FSR) on the bottom and RGB LED’s on top. Ivan Schepers provided practical insights during prototyping and developed the hardware around the interactive tiles. I was responsible for programming the system. Custom software was developed for the tiles, a controller to drive the tiles and to run and record experiments. Finally the system was moved to a hospital where the experiments took place. To know more about the exact experiments, please read the following three publications on AMPEL:
[Motor sequence learning in a goal-directed stepping task in persons with multiple sclerosis: a pilot study\
2022](https://nyaspubs.onlinelibrary.wiley.com/doi/10.1111/nyas.14702) Veldkamp, R., Moumdjian, L., van Dun, K., Six, J., Vanbeylen, A., Kos, D. and Feys, P. For this study AMPEL was slightly modified for a reaction time task, showing its flexibility. The participants were asked to step on a tile as quickly as possible after it lit up. They were either knowledgable of the tile trajectory or not. This work was also published in the Annals of the New York Academy of Sciences.
Basic media info: gives information about the streams and encodings used in a media file.
Fig: [audio transcodinging in the browser](/attachment/cors/ffmpeg.audio.wasm/transcode.html). A `wav` file is converted to an `mp3`.
A bit more about the rationale behind this effort: Browsers have become practical platforms for audio processing applications thanks to the combination of Web Audio API , performant Javascript environment and WebAssembly. Have a look, for example, at essentia.JS.
However, browsers only support a small subset of audio formats and container formats. Dealing with many (legacy) audio formats is often a rather painful experience since there are so many media container formats which can contain a surprising variation of audio (and video) encodings. In short, decoding audio for in-browser analysis or playback is often problematic.
Luckily there is FFmpeg which claims to be ‘a complete, cross-platform solution to record, convert and stream audio and video’. It is, indeed, capable to decode almost any audio encoding known to man from about any container. Additionally, it also contains tools to filter, manipulate, resample, stretch, … audio. FFmpeg is a must-have when working with audio. It would be ideal to have FFmpeg running in a browser…
Thanks to WebAssembly ffmpeg can be compiled for use in the browser. There have been effortstoget ffmpeg working in the browser. These efforts have been focusing on the complete ffmpeg suite. Now I have prepared an audio focused ffmpeg build for the web based on these efforts. I have selected only audio parts which makes the resulting .wasm binary four to five times smaller (from \~20MB to \~5MB). I also provided a simplified Javascript wrapper. The project brings audio decoding to the browser but also audio filtering, transcoding, pitch-shifting, sample rate conversions, audio channel manipulation, and so forth. It is also capable to extract audio streams from video container formats.
Next to the pure functionality of ffmpeg there are general advantages to run audio analysis software in the browser at client-side:
Ease-of-use: no software needs to be installed. The runtime comes with a compatible browser.
Privacy: Since media files are not transferred it is impossible for the system running the service to make unauthorised copies of these files. There is no need to trust the service since all processing happens locally, in the browser.
Speed: Downloading and especially uploading large media files takes a while. When files are kept locally, processing can start immediately and no time is wasted sending bytes over the internet. This results in a snappy user experience.
Computational load: the computational load of transcoding is distributed over the clients and not centralised on a (single) server. The server does not do any computing and only serves static files, so it can handle as many concurrent clients as its bandwidth allows.
PFFFT is a small, pretty fast FFT library programmed in C with a BSD-like license. I have taken it upon myself to compile a WebAssembly version of PFFFT to make it available for browsers and node.js environments. It is called pffft.wasm and available on GitHub.
The pffft.wasm library comes in two flavours. One is compiled with SIMD instructions while the other comes without these instructions. SIMD stands for ‘single instruction, multiple data’ and does what it advertises: in a single step it processes multiple datapoints. The aim of SIMD is to make calculations several times faster. Especially for workloads where the same calculations are repeated over and over again on similar data, SIMD optimisation is relevant. FFT calculation is such a workload.
Evidently the SIMD version is much faster but there is no need to take my word for it. Below you can benchmark the SIMD version of pffft.wasm and compare it with the non-SIMD version on your machine. A pure Javascript FFT library called FFT.js serves as a baseline.
When running the same benchmark on Firefox and on Chrome it becomes clear that FFT.js on Chrome is about twice as fast thanks to its superior Javascript engine for this workload. The performance of the WebAssembly versions in Chrome and Firefox is nearly identical. Safari unfortunately does not (yet) support SIMD WebAssembly binaries and fails to complete the benchmark.

 Fig: DALL.E 2 imagining a fight between papers and software.
Fig: DALL.E 2 imagining a fight between papers and software.



 Fig: stable diffusion imagining a networked music performance
Fig: stable diffusion imagining a networked music performance