This post explains how to receive OSC in a MatLab environment. It uses a platform independent Java library which should work on 64 and 32 bit versions of Windows, Unix and Mac OS X. Using Java makes installation relatively easy compared with other solutions.
The most used method to get OSC-messages in Matlab can be found here. This method uses a library called liblo which needs to be configured (compiled) correctly on your system. Especially on Windows this can be problematic. A brave soul documented his quest to get OSC working with Matlab on Windows here. Obviously not for the faint of heart.
An alternative way leverages the Matlab facilities to run Java. Since there is a Java OSC library available (JavaOSC on github) it is relatively easy to bridge the two. To make the connection, I have written some glue code and provide an easy to use Jar-library here. Using the bridge is done as follows:
How to make Matlab receive OSC-messages
Download the “JavaOSCtoMatlab Java library”:[javaosctomatlab.jar] and store it in an easy to remember directory.
Download the “example Matlab OSC client Script”:[osc_java_test.m] and store it in the same directory. The client is included below as well.
Start Matlab, modify the client script to fit your needs. You probably need to change the OSC method to listen to and the OSC port. Also make sure that the cd command points to the directory with the downloaded jar-file.
Run the client script and receive your OSC messages.
Note that there are three ways to receive the payload of a message. They are returned by the Java code as either Object[], double[] or String[]. The last two are automatically understood by Matlab, so they are more easy to work with. Respectively to get the message data you need to call either osc_listener.getMessageArguments(), osc_listener.getMessageArgumentsAsDouble(), osc_listener.getMessageArgumentsAsString().
This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).
Audio latency is an important aspect of a system, especially if it is used for real-time sonification or for musical applications. Audio latency is the, preferably short, delay between audio entering a system and emerging from a system. Audio output latency is the time it takes between a signal (e.g. a button pressed) and when audio emerges. For sonification purposes audio output latency is more interesting than round-trip audio latency.
Android systems are often portable, generally available and relatively cheap. Android offers an attractive platform to develop sonifications or musical applications for. Unfortunately, audio latency on Android has not been a priority in the first versions. With Android 4.1 things started to change but due to hard- and software fragmentation it is still hard to find how much audio latency is expected. Even if the exact model (e.g. Nexus 5) and software version (stock Android 5.0) is known, exact numbers are, so it seems, nowhere to be found. For more information on the internal changes that make low latency audio on Android possible, watch the talk on High Performance Audio from the 2013 Google I/O conference. Also note the lack of exact latency numbers in that talk. It is a very enjoyable talk by two Google engineers going after the culprits of high latency in true Sherlock/dr. Watson style.
Since audio output latency is generally not documented and since it is an important factor to decide if Android is a viable platform for real-time sonification or musical applications it needs to be measured. One way of measuring audio output latency on Android is documented by the people of Google. Unfortunately, the approach is not easily reproducible since it needs a custom circuit board, an oscilloscope and there is no source code available. Below a reproducible way to measure audio output latency for Android is documented.
An Arduino, an Android device, an USB-OTG cable and a butchered mini-jack audio cable are needed together with the software provided here. Optionally, a data acquisition module can be used to visualize the signals. The measurement system works as follows:
An Arduino sends a signal over USB. The time at which the signal is send is stored for later use.
An Android device, connected to the Arduino via an USB-OTG-cable, receives the signal.
The Android device responds as quickly as possible, with the lowest latency as possible, by emitting a sound.
The sound is captured on an analog input port of the Arduino, via the mini-jack cable. The time the sound appears on the Arduino is stored.
By comparing the time when the signal was send with the time when the sound arrived, the audio output latency is measured and reported.
The previous steps are repeated every second to gain insights into the variability of the measurements. To generate microsecond accurate timing interrupts are used on the Arduino. For visualisation, a digital pin is toggled every time the Arduino sends a signal. The Arduino sketch is attached to this post, as is the source code for the Android application. An already compiled APK is also available. With some luck - a recent Android version is needed, your device should support USB-OTG - it might work on your device.
Results
Using the OpenSL ES native interface on a Nexus 5 with Lollipop installed the USB input to audio output latency is on average about 48 milliseconds. There is some variability but it is usually within 15 milliseconds. For music applications this latency is not great but, depending on the application, acceptable. For expert drummers latency should be in the range of 20ms but for many sonification tasks, 50ms suffices. It is clear that Android will never be able to compete with purpose built hardware running a real time operating system like Axoloti (Audio roundtrip latency 2ms, usb-audio 1.6ms) but for a general purpose device the measured latency is significantly better than what I expected (around 100ms).
The non-native audio interface is a lot slower. I have measured an average latency of about 85ms and a much larger variability (25ms).
With this post I hope others will report the latency for their devices as well, so that buyers that are interested in a low-latency Android devices can make an informed decision.
The latency visualized.
Arduino wiring.
Result on Android.
The DAC used.
Arduino and the DAC
Onsets and audio visualized using a DAC and a Java program.
TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbor search algorithm for high dimensional vectors that operates in sublinear time. The open source software package is authored by me and is available on GitHub: TarsosLSH on GitHub.
With TarsosLSH, Joseph Hwang and Nicholas Kwon from Rice University created an Image Mosaic web application. The application chops an uploaded photo into small blocks. For each block, a color histogram is created and compared with an index of color histograms of reference images. Subsequently each block is replaced with one of the top three nearest neighbors, creating a mosaic. Since high dimensional nearest neighbor search is needed, this is an ideal application for TarsosLSH. The application somewhat proves that TarsosLSH can be used in practical applications, which is comforting.
The Starry Night, by Van Ghogh in Mosaic as created by the mosaic webapplication.
Currently, there is a crowd-funding campaign ongoing about Axoloti . Axoloti is a very cool project by Johannes Taelman. It is a stand alone audio processing unit that can be used as a synthesizer, groovebox, guitar effect pedal, as a part of a sound installation, or for about any other audio application you can think of.
Axeloti is controlled by a patcher environment and once it is programmed it operates as a stand alone unit. For more information, visit the Axoloti Website, watch the video below and and fund Axoloti.
Update: Good news everyone! Axoloti has been funded!
Below some notes on installing and using the drivers for the Avandtech USB-4716 on Linux can be found. Since I was unable to find these instructions elsewhere and it took me some time to figure things out, it is perhaps of use to someone else. A similar approach should work for the following devices as well: pci1715, pci1724, pci1734, pci1752, pci1758, pcigpdc, usb4711a, usb4750, pci1711, pci1716, pci1727, pci1747, pci1753_mic3753_pcm3753i, pci1761_pcm3761i, pcm3810i, usb4716, usb4761, pci1714_pcie1744, pci1721, pci1730_pcm3730i, pci1750, pci1756, pci1762, usb4702_usb4704, usb4718
Download the linux driver for the Avandtech USB-4716 DAQ. If you are on a system that can install either deb or rpm use the driver_package. Unzip the package. The driver is split into two parts. A base driver biokernbase and a driver specific for the USB-4716 device, bio4716. The drivers are Linux kernel modules that need to installed. First the base driver needs to be installed, the order is important. After the base driver install the device specific deb kernel module. After a reboot or perhaps immediately this should be the result of executing lsmod | grep bio:
A library to interface with the hardware is provided as a deb package as well. Install this library on your system.
Next download the the examples for the Avandtech USB-4716 DAQ. With the kernel modules installed the system is ready to test the examples in the provided examples directory. If you are using the Java code, make sure to set the java.library.path correctly.
The 27th of November, 2014 a lecture on audio fingerprinting and its applications for digital musicology will be given at IPEM. The lecture introduces audio fingerprinting, explains an audio fingerprinting technique and then goes on to explain how such algorithm offers opportunities for large scale digital musicological applications. Here you can download the slides about audio fingerprinting and its opportunities for digital musicology.
With the explained audio fingerprinting technique a specific form of very reliable musical structure analysis can be done. Below, in the figure section, an example of repetitive structure in the song Ribs Out is shown. Another example is comparing edits or versions of songs. Below, also in the figure section, the radio edit of Daft Punk’s Get Lucky is compared with the original version. Audio synchronization using fingerprinting is another application that is actively used in the field of digital musicology to align audio with extracted features.
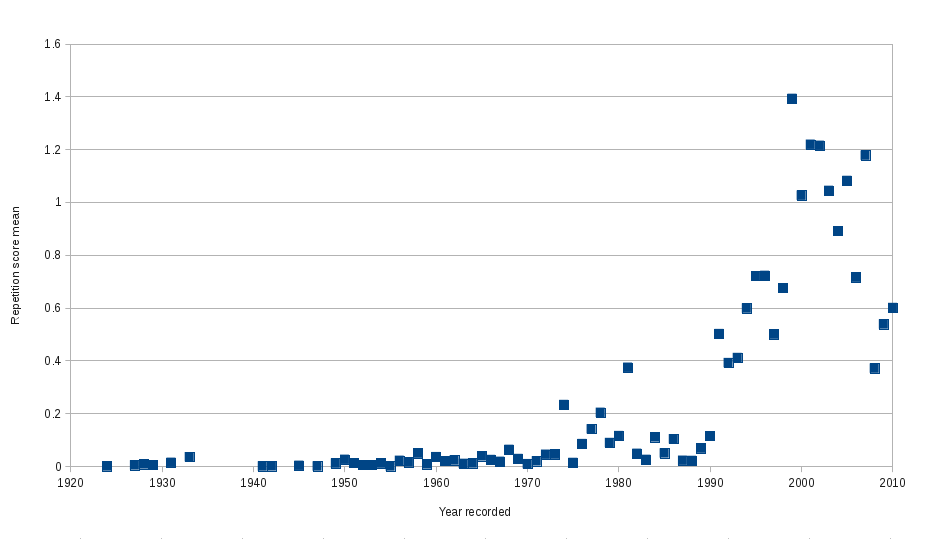
Since acoustic fingerprinting makes structure analysis very efficiently it can be applied on a large scale (20k songs). The figure below shows that identical repetition is something that has been used more and more since the mid 1970’s. The trend probably aligns with the amount of technical knowledge needed to ‘copy and paste’ a snippet of music.
\
Fig: How much identical repetition is used in music, over the years.
At ISMIR 2014 i will present a paper on a fingerprinting system. ISMIR is the annual conference of the International Society for Music Information Retrieval is the world’s leading interdisciplinary forum on accessing, analyzing, and organizing digital music of all sorts. This years instalment takes place in Taipei, Taiwan. My contribution is a paper titled Panako - A Scalable Acoustic Fingerprinting System Handling Time-Scale and Pitch Modification, it will be presented during a poster session the 27th of October.
This paper presents a scalable granular acoustic fingerprinting system. An acoustic fingerprinting system uses condensed representation of audio signals, acoustic fingerprints, to identify short audio fragments in large audio databases. A robust fingerprinting system generates similar fingerprints for perceptually similar audio signals. The system presented here is designed to handle time-scale and pitch modifications. The open source implementation of the system is called Panako and is evaluated on commodity hardware using a freely available reference database with fingerprints of over 30,000 songs. The results show that the system responds quickly and reliably on queries, while handling time-scale and pitch modifications of up to ten percent.
The system is also shown to handle GSM-compression, several audio effects and band-pass filtering. After a query, the system returns the start time in the reference audio and how much the query has been pitch-shifted or time-stretched with respect to the reference audio. The design of the system that offers this combination of features is the main contribution of this paper.
It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the pdj~ object, which should be compatible with the Max/MSP implementation. This post demonstrates a patch that connects an oscillator with a pitch tracking algorithm implemented in TarsosDSP.
To the left you can see the finished patch. When it is working an audio stream is generated using an oscillator. The frequency of the oscillator can be controlled. Subsequently the stream is send to the Java environment with the pdj bridge. The Java environment receives an array of floats, representing the audio. A pitch estimation algorithm tries to find the pitch of the audio represented by the buffer. The detected pitch is returned to the pd environment by means of outlet. In pd, the detected pitch is shown and used for auditory feedback.
PitchDetectionResult result = yin.getPitch(audioBuffer);
pitch = result.getPitch();
outlet(0, Atom.newAtom(pitch));
Please note that the pitch detection algorithm can handle any audio stream, not only pure sines. The example here demonstrates the most straightforward case. Using this method all algorithms implemented in TarsosDSP can be used in Pure Data. These range from onset detection to filtering, from audio effects to wavelet compression. For a list of features, please see the TarsosDSP github page. Here, the source for this patch implementing pitch tracking in pd can be downloaded. To run it, extract it to a directory and simply run the pitch.pd patch. Pure Data should load pdj~ automatically together with the classes present in the classes directory.
This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies.
Since version 2.0 there are no more references to javax.sound.* in the TarsosDSP core codebase. This makes it easy to run TarsosDSP on Android. Audio Input/Output operations that depend on either the JVM or Dalvik runtime have been abstracted and removed from the core. For each runtime target a Jar file is provided in the TarsosDSP release directory.
The following example connects an AudioDispatcher to the microphone of an Android device. Subsequently, a real-time pitch detection algorithm is added to the processing chain. The detected pitch in Hertz is printed on a TextView element, if no pitch is present in the incoming sound, –1 is printed. To test the application download and install the /files/attachments/420/TarsosDSPAndroid.apk(/files/attachments/420/TarsosDSPAndroid.apk) application on your Android device. The source code is available as well.
The TarsosDSP Java library for audio processing now contains an implementation of the Haar Wavelet Transform. A discrete wavelet transform based on the Haar wavelet (depicted at the right). This reversible transform has some interesting properties and is practical in signal compression and for analyzing sudden transitions in a file. It can e.g. be used to detect edges in an image.
As an example use case of the Haar transform, a simple lossy audio compression algorithm is implemented in TarsosDSP. It compresses audio by dividing audio into bloks of 32 samples, transforming them using the Haar wavelet Transform and subsequently removing samples with the least difference between them. The last step is to reverse the transform and play the audio. The amount of compressed samples can be chosen between 0 (no compression) and 31 (no signal left). This crude lossy audio compression technique can save at least a tenth of samples without any noticeable effect. A way to store the audio and read it from disk is included as well.
The algorithm works in real time and an example application has been implemented which operates on an mp3 stream. To make this work immediately, the avconv tool needs to be on your system’s path. Also implemented is a bit depth compressor, which shows the effect of (extreme) bit depth compression.
The TarsosDSP Java library for audio processing now contains a module for spectral peak extraction. It calculates a short time Fourier transform and subsequently finds the frequency bins with most energy present using a median filter. The frequency estimation for each identified bin is significantly improved by taking phase information into account. A method described in “Sethares et al. 2009 - Spectral Tools for Dynamic Tonality and Audio Morphing”.
The noise floor, determined by the median filter, the spectral information itself and the estimated peak locations are returned for each FFT-frame. Below a visualization of a flute can be found. As expected, the peaks are harmonically spread over the complete spectrum up until the Nyquist frequency.
Spectral peaks of a flute. The first 10 harmonic are detected up until the Nyquist frequency.
Give students an intensive course in the most advanced and current topics in the research fields of systematic musicology and sound and music computing. Give students the opportunity to discuss their research proposals/project with an international staff of teachers representing a variety of expertise in different domains of systematic musicology and sound and music computing. Teach students the most recent knowledge and basic skills needed to start a PhD. Give students the opportunity to join the research communities on systematic musicology, on sound and music computing.
Next to the lectures, the informal meetings with the professors was very interesting. I got to add some things to my ‘to read’ list:
Rolf Bader, Calculation of Helmholtz frequency of a Renaissance vihuela string instrument with five tone hole
Schneider, A. & Frieler, K. (2009) __Perception of harmonic and inharmonic sounds: Results from\
ear models. In S. Ystad, R. Kronland-Martinet & K. Jensen (Eds.), Computer music modeling and retrieval. Genesis of meaning in sound and music (pp. 18–44). Berlin: Springer.
This post contains some info on how do some basic home automation: it shows how cheap remote controlled power sockets can be managed using a computer. The aim is to power on or power off lights, a stereo or other devices remotely from a command shell.
The solution here uses an Arduino connected to a 433.33MHz transmitter. Via a Ruby script installed on the computer a command is send over serial to the Arduino. Subsequently the Arduino sends the command over the air to the power socket(s). If all goes well the power socket reacts by switching the connecting device on or off.
In the video below the process is shown. The command line interface controls the light via the Arduino. It should show the general idea.
The following Ruby script simply sends the binary control codes to the Arduino. For this type of power socket the code consist of a five bit group code and five bit device code. The Arduino is connected to /dev/tty.usbmodem411.
The code below is the complete Arduino sketch. It uses the RCSwich library, which makes the implementation very simple. Essentially it waits for a complete command and transmits it through the connected transmitter. The transmitter connected is a tx433n
```ruby\
#include <RCSwitch.h>
RCSwitch mySwitch = RCSwitch();
char command[12];//2x5 for device and group + command\
int index = 0;\
char currentChar = –1;
//the led pin in use\
int ledPin = 12;
void setup() {\
//start the serial communication\
Serial.begin(9600);\
// 433MHZ Transmitter is connected to Arduino Pin #10\
mySwitch.enableTransmit(10);\
//Led connected to led pin\
pinMode(ledPin, OUTPUT);\
Serial.println(“Started the power command center! Mwoehahaha!”);\
}
void readCommand(){\
//read a command\
while (Serial.available() > 0){\
if(index < 11){\
currentChar = Serial.read(); // Read a character\
command[index] = currentChar; // Store it\
index; // Increment where to write next\
command[index] = ‘\0’; // append termination char\
}\
}\
}
void loop() {\
//read a command\
readCommand();\
//if a command is complete\
if(index == 11){\
Serial.print(“Recieved command: “);\
Serial.println(command);\
char operation = command[0];\
char* group = &command[1];\
//group is 5 bits, as is device\
char* device = &command[6];
//execute the operation\
doSwitch(operation,group,device);\
//reset the index to read a new command\
index=0;\
}\
}
TarsosDSP will be presented at the AES 53rd International conference on Semantic Audio in London . During the conference both a presentation and demonstration of the paper “TarsosDSP, a Real-Time Audio Processing Framework in Java”:[aes53_tarsos_dsp.pdf], by Joren Six, Olmo Cornelis and Marc Leman, in Proceedings of the 53rd AES Conference (AES 53rd), 2014. From their website:
Semantic Audio is concerned with content-based management of digital audio recordings. The rapid evolution of digital audio technologies, e.g. audio data compression and streaming, the availability of large audio libraries online and offline, and recent developments in content-based audio retrieval have significantly changed the way digital audio is created, processed, and consumed. New audio content can be produced at lower cost, while also large audio archives at libraries or record labels are opening to the public. Thus the sheer amount of available audio data grows more and more each day. Semantic analysis of audio resulting in high-level metadata descriptors such as musical chords and tempo, or the identification of speakers facilitate content-based management of audio recordings. Aside from audio retrieval and recommendation technologies, the semantics of audio signals are also becoming increasingly important, for instance, in object-based audio coding, as well as intelligent audio editing, and processing. Recent product releases already demonstrate this to a great extent, however, more innovative functionalities relying on semantic audio analysis and management are imminent. These functionalities may utilise, for instance, (informed) audio source separation, speaker segmentation and identification, structural music segmentation, or social and Semantic Web technologies, including ontologies and linked open data.
This conference will give a broad overview of the state of the art and address many of the new scientific disciplines involved in this still-emerging field. Our purpose is to continue fostering this line of interdisciplinary research. This is reflected by the wide variety of invited speakers presenting at the conference.
The paper presents TarsosDSP, a framework for real-time audio analysis and processing. Most libraries and frameworks offer either audio analysis and feature extraction or audio synthesis and processing. TarsosDSP is one of a only a few frameworks that offers both analysis, processing and feature extraction in real-time, a unique feature in the Java ecosystem. The framework contains practical audio processing algorithms, it can be extended easily, and has no external dependencies. Each algorithm is implemented as simple as possible thanks to a straightforward processing pipeline. TarsosDSP’s features include a resampling algorithm, onset detectors, a number of pitch estimation algorithms, a time stretch algorithm, a pitch shifting algorithm, and an algorithm to calculate the Constant-Q. The framework also allows simple audio synthesis, some audio effects, and several filters. The Open Source framework is a valuable contribution to the MIR-Community and ideal fit for interactive MIR-applications on Android. The full paper can be downloaded “TarsosDSP, a Real-Time Audio Processing Framework in Java”:[aes53_tarsos_dsp.pdf]
A BibTeX entry for the paper can be found below.
```ruby\
\@inproceedings{six2014tarsosdsp,\
author = {Joren Six and Olmo Cornelis and Marc Leman},\
title = {{TarsosDSP, a Real-Time Audio Processing Framework in Java}},\
booktitle = {{Proceedings of the 53rd AES Conference (AES 53rd)}},\
year = 2014\
}\
```
Woensdag 18 december 2013 organiseerde Olmo Cornelis een concert in het kader van zijn doctoraat. De dag erna volgde zijn verdediging. Nogmaals proficiat Olmo met het mooie eeh mbirapunt. Hieronder staat kort wat uitleg over het project en het concert.
bq.. In zijn onderzoeksproject ‘Exploring the symbiosis of Western and non-Western Music’ stelde Olmo Cornelis de beschrijving van Centraal-Afrikaanse muziek centraal. Deze werd verkend via computationele technieken die de klank als signaal\
benaderden. De verkregen informatie zorgde voor beïnvloeding van het artistieke oeuvre waarin steeds een mengeling van impliciete en expliciete etnische invloeden spelen.
In het kader van de afronding van dit doctoraal onderzoek spelen het HERMESensemble, het Nadar Ensemble, Maja Jantar en Françoise Vanhecke op 18 december werk van Olmo Cornelis dat tijdens dit project geschreven werd. Het onderzoeksproject Exploring the symbiosis of Western and non-Western Music werd in 2008 geïnitieerd aan het Conservatorium / School of Arts van de HoGent en werd gefinancierd door het onderzoeksfonds Hogeschool Gent.
Beeld: Noel Cornelis, Reality of Possibilities, 2012
Yesterday, December 4th 2013, the RTBF (Radio Télévision Belge Francophone) was at IPEM (Institute for Psychoacoustics and Electronic Music) to do a small feature on research currently going on at the institue. The RTBF is the public broadcasting organization of the French Community of Belgium, the southern, French-speaking part of Belgium. The clip shows the D-Jogger in action, with me using it. The fragment is available on the RTBF website and is embedded below.
The journal paper Evaluation and Recommendation of Pulse and Tempo Annotation in Ethnic Music - In Journal Of New Music Research by Cornelis, Six, Holzapfel and Leman was published in a special issue about Computational Ethnomusicology of the Journal of New Music Research (JNMR) on the 20th of august 2013. Below you can find the abstract for the article, and the full text author version of the article itself.
Abstract: Large digital archives of ethnic music require automatic tools to provide musical content descriptions. While various automatic approaches are available, they are to a wide extent developed for Western popular music. This paper aims to analyze how automated tempo estimation approaches perform in the context of Central-African music. To this end we collect human beat annotations for a set of musical fragments, and compare them with automatic beat tracking sequences. We first analyze the tempo estimations derived from annotations and beat tracking results. Then we examine an approach, based on mutual agreement between automatic and human annotations, to automate such analysis, which can serve to detect musical fragments with high tempo ambiguity.
Below the BibTex entry for the article is embedded.
```ruby\
\@article{cornelis2013tempo_jnmr,\
author = {Olmo Cornelis, Joren Six, Andre Holzapfel, and Marc Leman},\
title = {{Evaluation and Recommendation of Pulse ant Tempo Annotation in Ethnic Music}},\
journal = {{Journal of New Music Research}},\
volume = {42},\
number = {2},\
pages = {131-149},\
year = {2013},\
doi = {10.1080/09298215.2013.812123}\
}\
```
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a Constant-Q Transform (as of version 1.6). The Constant-Q transform does essentially the same thing as an FFT, but has the advantage that each octave has the same amount of bins. This makes the Constant-Q transform practical for applications processing music. If, for example, 12 bins per octave are chosen, these can correspond with the western musical scale.
Also included in the newest release (version 1.7) is a way to visualize the transform, or other musical features. The visualization implementation is done together with Thomas Stubbe.
The example application below shows the Constant-Q transform with an overlay of pitch estimations. The corresponding waveform is also shown.
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of the Journal of New Music Research (JNMR) on the 20th of august 2013. Below you can find the abstract for the article, and pointers to audio examples, the Tarsos software, and the author version of the article itself.
Abstract: This paper presents Tarsos, a modular software platform used to extract and analyze pitch organization in music. With Tarsos pitch estimations are generated from an audio signal and those estimations are processed in order to form musicologically meaningful representations. Tarsos aims to offer a flexible system for pitch analysis through the combination of an interactive user interface, several pitch estimation algorithms, filtering options, immediate auditory feedback and data output modalities for every step. To study the most frequently used pitches, a fine-grained histogram that allows up to 1200 values per octave is constructed. This allows Tarsos to analyze deviations in Western music, or to analyze specific tone scales that differ from the 12 tone equal temperament, common in many non-Western musics. Tarsos has a graphical user interface or can be launched using an API - as a batch script. Therefore, it is fit for both the analysis of individual songs and the analysis of large music corpora. The interface allows several visual representations, and can indicate the scale of the piece under analysis. The extracted scale can be used immediately to tune a MIDI keyboard that can be played in the discovered scale. These features make Tarsos an interesting tool that can be used for musicological analysis, teaching and even artistic productions.
Ladrang Kandamanyura (slendro pathet manyura), is the name of the piece used in the article throughout section 2. The album on which the piece can be found is available at wergo. Below a thirty second fragment is embedded. You can also “download”:[08._Ladrang_Kandamanyura_10s-20s_up.wav] the thirty second fragment to analyse it yourself.
Below the BibTex entry for the article is embedded.
```ruby\
\@article{six2013tarsos_jnmr,\
author = {Six, Joren and Cornelis, Olmo and Leman, Marc},\
title = {Tarsos, a Modular Platform for Precise Pitch Analysis\
of Western and Non-Western Music},\
journal = {Journal of New Music Research},\
volume = {42},\
number = {2},\
pages = {113-129},\
year = {2013},\
doi = {10.1080/09298215.2013.797999},\
URL = {http://www.tandfonline.com/doi/abs/10.1080/09298215.2013.797999}\
}\
```
In the extended abstract, also titled “Computer Assisted Transcription of Ethnic Music”:[FMA_2013.computer_assisted_transcription.pdf], it is described how the Tarsos software program now has features aiding transcription. Tarsos is especially practical for ethnic music of which the tone scale is not known beforehand. The proceedings of FMA 2013 are available as well.
"":\[A0-Poster.jpg\]
During the conference there also was an interesting panel on transcription. The following people participated: John Ashley Burgoyne, moderator (University of Amsterdam), Kofi Agawu (Princeton University), Dániel P. Biró (University of Victoria), Olmo Cornelis (University College Ghent, Belgium), Emilia Gómez (Universitat Pompeu Fabra, Barcelona), and Barbara Titus (Utrecht University). Some pictures can be found below.
 This post explains how to receive OSC in a MatLab environment. It uses a platform independent Java library which should work on 64 and 32 bit versions of Windows, Unix and Mac OS X. Using Java makes installation relatively easy compared with other solutions.
This post explains how to receive OSC in a MatLab environment. It uses a platform independent Java library which should work on 64 and 32 bit versions of Windows, Unix and Mac OS X. Using Java makes installation relatively easy compared with other solutions. This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).
This post explains how to measure audio output latency on Android devices. To measure audio latency USB-OTG(On The Go) and an Arduino is used. In the process it documents audio output latency on an LG Nexus 5 device running the most recent version of Android, which currently is Lollipop (5.0).











 \
\













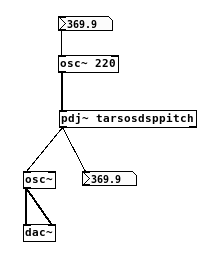 It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the
It makes sense to connect TarsosDSP, a real-time audio processing library written in Java, with patcher environments such as Pure Data and Max/MSP. Both Pure Data and Max/MSP offer the capability to code object, or externals using Java. In Pure Data this is done using the  This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies.
This post explains how to get TarsosDSP running on Android. TarsosDSP is a Java library for audio processing. Its aim is to provide an easy-to-use interface to practical music processing algorithms implemented, as simply as possible, in pure Java and without any other external dependencies. The TarsosDSP Java library for audio processing now contains an implementation of the
The TarsosDSP Java library for audio processing now contains an implementation of the 












 The journal paper Evaluation and Recommendation of Pulse and Tempo Annotation in Ethnic Music - In Journal Of New Music Research by Cornelis, Six, Holzapfel and Leman was published in a special issue about Computational Ethnomusicology of
The journal paper Evaluation and Recommendation of Pulse and Tempo Annotation in Ethnic Music - In Journal Of New Music Research by Cornelis, Six, Holzapfel and Leman was published in a special issue about Computational Ethnomusicology of 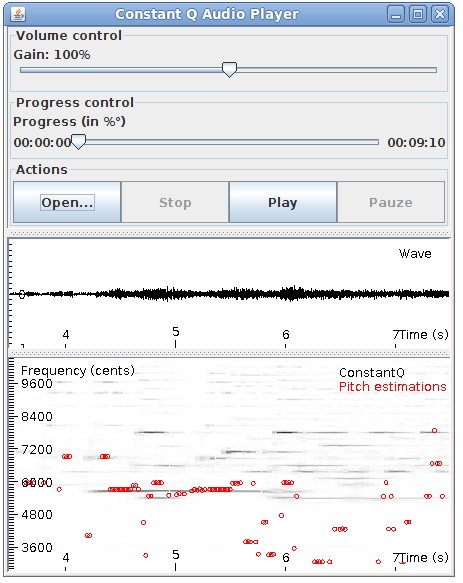
 The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of
The journal paper Tarsos, a Modular Platform for Precise Pitch Analysis of Western and Non-Western Music by Six, Cornelis, and Leman was published in a special issue about Computational Ethnomusicology of  ":\[A0-Poster.jpg\]
":\[A0-Poster.jpg\]

