TarsosLSH is a Java library implementing Locality-sensitive Hashing (LSH), a practical nearest neighbour search algorithm for multidimensional vectors that operates in sublinear time. It supports several Locality Sensitive Hashing (LSH) families: the Euclidean hash family (L2), city block hash family (L1) and cosine hash family. The library tries to hit the sweet spot between being capable enough to get real tasks done, and compact enough to serve as a demonstration on how LSH works. It relates to the Tarsos project because it is a practical way to search for and compare musical features.
<code>git clone https://JorenSix@github.com/JorenSix/TarsosLSH.git
cd TarsosLSH/build
ant #Builds the core TarsosLSH library
ant javadoc #build the API documentation
</code>
\
When everything runs correctly you should be able to run the command line application, and have the latest version of the TarsosLSH library for inclusion in your projects. Also, the Javadoc documentation for the API should be available in TarsosLSH/doc. Drop me a line if you use TarsosLSH in your project. Always nice to hear how this software is used.
The fastest way to get something on your screen is executing this on your command line: java - jar TarsosLSH.jar this lets LSH run on a random data set. The full reference of the command line application is included below:
Name
TarsosLSH: finds the nearest neighbours in a data set quickly, using LSH.
Synopsis
java - jar TarsosLSH.jar [options] dataset.txt queries.txt
Description
Tries to find nearest neighbours for each vector in the
query file, using Euclidean (L2) distance by default.
Both dataset.txt and queries.txt have a similar format:
an optional identifier for the vector and a list of N
coordinates (which should be doubles).
[Identifier] coord1 coord2 ... coordN
[Identifier] coord1 coord2 ... coordN
For an example data set with two elements and 4 dimensions:
Hans 12 24 18.5 -45.6
Jane 13 19 -12.0 49.8
Options are:
-f cos|l1|l2
Defines the hash family to use:
l1 City block hash family (L1)
l2 Euclidean hash family(L2)
cos Cosine distance hash family
-r radius
Defines the radius in which near neighbours should
be found. Should be a double. By default a reasonable
radius is determined automatically.
-h n_hashes
An integer that determines the number of hashes to
use. By default 4, 32 for the cosine hash family.
-t n_tables
An integer that determines the number of hash tables,
each with n_hashes, to use. By default 4.
-n n_neighbours
Number of neighbours in the neighbourhood, defaults to 3.
-b
Benchmark the settings.
--help
Prints this helpful message.
Examples
Search for nearest neighbours using the l2 hash family with a radius of 500
and utilizing 5 hash tables, each with 3 hashes.
java - jar TarsosLSH.jar -f l2 -r 500 -h 3 -t 5 dataset.txt queries.txt
Source Code Organization
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
Further Reading
This section includes a links to resources used to implement this library.
The LSH-page maintained by Alexandr Andoni contains pointers to good resources:
Locality-Sensitive Hashing Scheme Based on p-Stable Distributions a chapter by Alexandr Andoni, Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab Mirrokni which appeared in the book Nearest Neighbor Methods in Learning and Vision: Theory and Practice, by T. Darrell and P. Indyk and G. Shakhnarovich (eds.), MIT Press, 2006.
This post documents how to implement a simple music quiz with the meta data provided by Spotify and a big red button.
During my last birthday party, organized at Hackerspace Ghent ,there was an ongoing Spotify music quiz. The concept was rather simple: If music that was playing was created in the same year as I was born, the guests could press a big red button and win a price! If they guessed incorrectly, they were publicly shamed with a sad trombone. Only one guess for each\
song was allowed.
Below you can find a small videograph which shows the whole thing in action. The music quiz is simple: press the button if the song is created in 1984. In the video, at first a wrong answer is given, then a couple of invalid answers follow. Finally a good answer is given, the song “The Killing Moon by Echo & the Bunnymen” is from 1984! Woohoo!
Allright, what did I use to to implement the spotify music quiz:
A big red Arduino button, attatched by USB to a laptop.
A system with Spotify.
A way to access the meta data of the currently playing song in Spotify.
A Ruby script to connect al the parts and checks answers.
The Red Button
A nice big red button, which main features are that it is red and big, serves as the main input device for the quiz. To be able to connect the salvaged safety button to a computer via USB, an Arduino Nano is used. The Arduino is loaded with the code from the debounce tutorial, basically unchanged. Unfortunately, I could not fit the the FTDI-chip, which provides the USB connection, in the original enclosure. An additional enclosure, the white one seen in the pictures below, was added.
When pressed, the button sends a signal over the serial line. See below how the Ruby Quiz script waits for, and handles such event.
Get Meta Data from the Currently Playing Song in Spotify
Another requirement for the quiz to work is the ability to get information about the song currently playing in Spotify. On Linux this can be done with the dbus interface for Spotify. The script included below returns information about the artist, album and title of the song. It also detects if Spotify is running or not. Find it, fork it, use it, on github
With the individual part in order, we now need Ruby glue to paste it all together. The complete music quiz script can be found on github. The main loop, below, waits for a button press. If it is pressed the “sad trombone”:[sad_trombone.wav], “invalid answer”:[cheater.wav] or “winner”:[winner.wav] sound is played. The sounds are attached to this post.
```ruby\
while true do\
# Wait for a button press\
data = sp.readline\
# Fetch meta data about the currently\
# playing song\
result = `#{now_playing_command}`\
# Parse the meta data\
title,artist,album = parse_result(result)\
#Title is hash key, should be unique within playlist\
key = title\
if responded_to.has_key? key\
puts “Already answered: you cheater”\
play cheater\
elsif correct_answers.has_key? key\
puts “Correct answers: woohoo”\
responded_to[key]=true\
play winner\
else\
puts “Incorrect answer: sad trombone”\
responded_to[key]=true\
play sad_trombone\
end\
end\
```
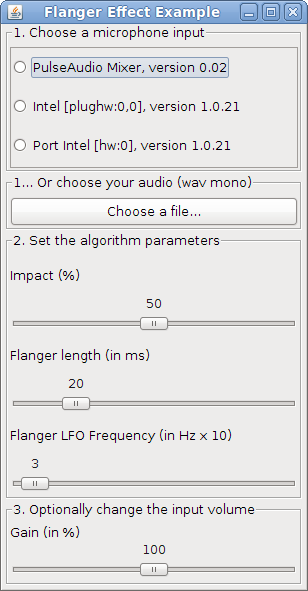
The DSP library for Taros, aptly named TarsosDSP, now includes an example demonstrating the flanging audio effect. Flanging, essentialy mixing the signal with a varying delay of itself, produces an interesting interference pattern.
The flanging example works on wav-files or on input from microphone. Try it yourself, download\
Flanging.jar, the executable jar file. Below you can check what flanging sounds like with various parameters.
The source code of the Java implementation can be found on the TarsosDSP github page.
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize cat sounds. The inspration came from this youtube video
To hear what exactly it does, listen to the following audio example.
There is also a command line interface, the following command does
The DSP library for Taros, aptly named TarsosDSP, now includes an example showing how to synthesize pitch estimations. The goal of the example is to show which errors are made by different pitch detectors.
To test the application, download and execute the Resynthesizer.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To hear what exactly it does, compare the following two audio fragments:
There is also a command line interface, the following command does pitch tracking, and follows the envelope of in.wav and immediately plays it on the default audio device. If you want to save the audio, see the command line options. The “flute example”:[flute.wav] is provided for your convenience.
\
java -jar Resynthesizer-latest.jar in.wav\
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP resynthesizer
----------------------------------------------------
Synopsis:
java -jar CommandLineResynthesizer.jar [--detector DETECTOR] [--output out.wav] [--combined combined.wav] input.wav
----------------------------------------------------
Description:
Extracts pitch and loudnes from audio and resynthesises the audio with that information.
The result is either played back our written in an output file.
There is als an option to combine source and synthezized material
in the left and right channels of a stereo audio file.
input.wav a readable wav file.
--output out.wav a writable file.
--combined combined.wav a writable output file. One channel original, other synthesized.
--detector DETECTOR defaults to FFT_YIN or one of these:
YIN
MPM
FFT_YIN
DYNAMIC_WAVELET
AMDF
The source code of the Java implementation of the synthesizer can be found on the TarsosDSP github page.
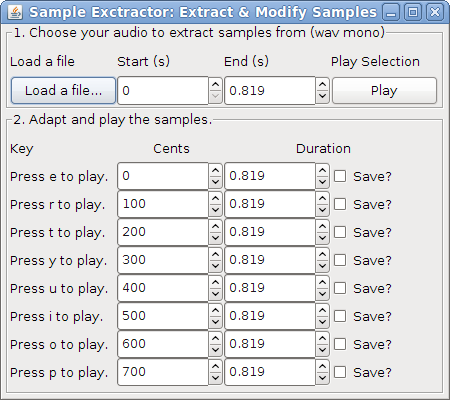
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4) and a time stretching algorithm. Combined, the two can be used for something like phase vocoding. With a phase vocoder you can load an audio snippet, change the pitch and duration and e.g. create a library of snippets. E.g. by recording one piano key stroke, it is possible to generate two octaves of samples of different lengths, and use those in stead of synthesized samples. The following example application shows exactly that, implemented in the java programming language.
The example application below shows how to pitch shift and time stretch a sample to create a sample library with the TarsosDSP library.
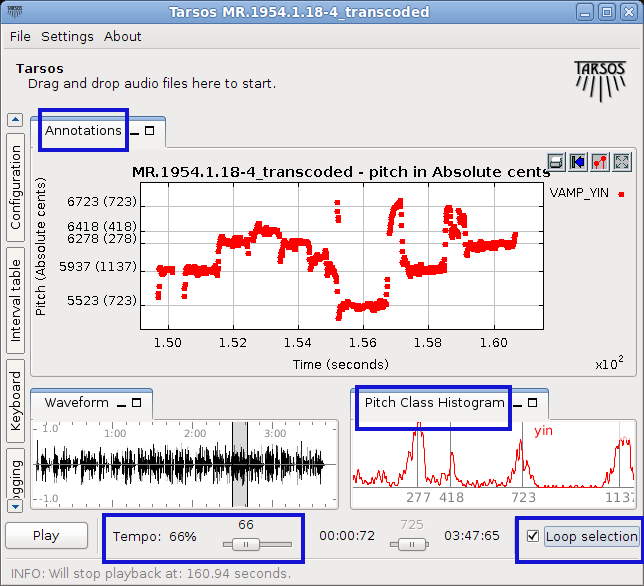
Today marks the reslease of Tarsos 1.0 . The new Tarsos release contains practical transcription features. As can be seen in the screenshot below, a time stretching feature makes it easy to loop a certain audio fragment while it is playing in a slow tempo. The next loop can be played with by pressing the n key, the one before by pressing b.
Since the pitch classes can be found in a song, and there is a feature that lets you play a MIDI keyboard in the tone scale of the song under analysis, transcription of ethnic music is made a lot easier.
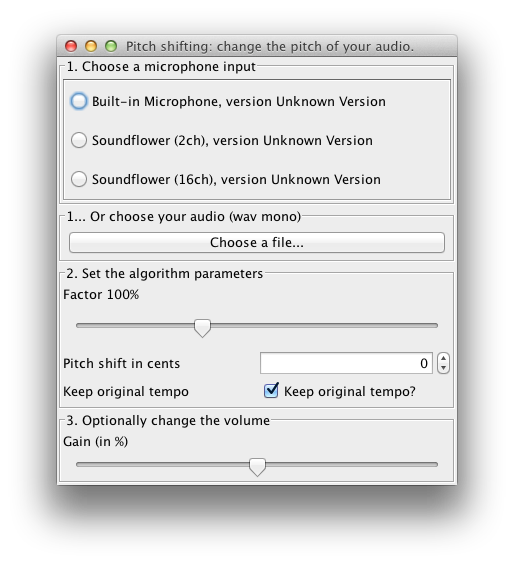
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of a pitch shifting algorithm (as of version 1.4). The goal of pitch shifting is to change the pitch of a piece of audio without affecting the duration. The algorithm implemented is a combination of resampling and time stretching. Resampling changes the pitch of the audio, but affects the total duration. Consecutively, the duration of the audio is stretched to the original (without affecting pitch) with time stretching. The result is very similar to phase vocoding.
The example application below shows how to pitch shift input from the microphone in real-time, or pitch shift a recorded track with the TarsosDSP library.
To test the application, download and execute the PitchShift.jar file and load an audio file. For the moment only 44.1kHz mono wav is allowed. To get started you can try “this piece of audio”:[08._Ladrang_Kandamanyura_10s-20s.wav].
There is also a command line interface, the following command lowers the pitch of in.wav by two semitones.
java -jar in.wav out.wav -200
----------------------------------------------------
_______ _____ _____ _____
|__ __| | __ \ / ____| __ \
| | __ _ _ __ ___ ___ ___| | | | (___ | |__) |
| |/ _` | '__/ __|/ _ \/ __| | | |\___ \| ___/
| | (_| | | \__ \ (_) \__ \ |__| |____) | |
|_|\__,_|_| |___/\___/|___/_____/|_____/|_|
----------------------------------------------------
Name:
TarsosDSP Pitch shifting utility.
----------------------------------------------------
Synopsis:
java -jar PitchShift.jar source.wav target.wav cents
----------------------------------------------------
Description:
Change the play back speed of audio without changing the pitch.
source.wav A readable, mono wav file.
target.wav Target location for the pitch shifted file.
cents Pitch shifting in cents: 100 means one semitone up,
-100 one down, 0 is no change. 1200 is one octave up.
The resampling feature was implemented with libresample4j by Laszlo Systems. libresample4j is a Java port of Dominic Mazzoni’s libresample 0.1.3, which is in turn based on Julius Smith’s Resample 1.7 library.
The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The ISMIR 2012 is described as follows:
The annual Conference of the International Society for Music Information Retrieval (ISMIR) is the world’s leading research forum on processing, searching, organizing and accessing music-related data. The revolution in music distribution and storage brought about by digital technology has fueled tremendous research activities and interests in academia as well as in industry. The ISMIR Conference reflects this rapid development by providing a meeting place for the discussion of MIR-related research, developments, methods, tools and experimental results. Its main goal is to foster multidisciplinary exchange by bringing together researchers and developers, educators and librarians, as well as students and professional users.
Tutorials
I saw an interesting tutorial on Jazz music and a tutorial on source separation. After an introduction, which detailed the experimental basis of the system, a source separator was introduced. The REPET source separator is a relatively simple system that yields reasonable results to split accompaniment from foreground melody.
The ongoing work by Ceril Bohak and Matija Marolt on segmentation of folk music could be very useful to apply on Afican musics. The paper is called Finding Repeating Stanzas in Folk Songs.
At this years ICMC Conference, ICMC 2012 we presented a paper describing a way to experiment with tone scales and how to use Tarsos as a compositional tool. What follows are some pointers to the presentation, paper and to other interesting talks that were presented there.
ICMC 2012 was organized in Ljubljana from the 9 to 14 septembre and had a very dense program of talks, posters, presentations, demos and concerts.
Since 1974 the International Computer Music Conference has been the major international forum for the presentation of the full range of outcomes from technical and musical research, both musical and theoretical, related to the use of computers in music. This annual conference regularly travels the globe, with recent conferences in the Americas, Europe and Asia. This year we welcome the conference to Slovenia for the first time.
### Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition
Our contribution to the conference was a paper titled “Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition”:[icmc2012_submission_45.pdf].
If you want to cite our work, this BibTeX entry is included for your convenience:
```ruby\
\@inproceedings{cornelis2012sound_to_scale,\
author = {Olmo Cornelis and Joren Six},\
title = {{Sound to Scale to Sound, a Setup for Microtonal Exploration and Composition}},\
booktitle = {{Proceedings of the 2012 International Computer Music Conference,\
(ICMC 2012)}},\
year = {2012},\
publisher = {The International Computer Music Association}\
}\
```
Program highlights
What follows are a number of pointers to my personal program highlights.
Verena Thomas presented two very well polished software tools. One to detect patterns in scores, called motifviewer and a tool to search in score databases in a multi-modal way. The Probado tool does score-to-audio alignment and much more.
Gibber is an impressive live-coding environment with an easy syntax. Since it is all done with javascript you can start playing with it immediately. Overtone Another live-coding environment, presented at the conference by Sam Aaron, was equally impressive. It is programmed using the Closure language.
At ICMC there were a number of tools to assist in composition. One of those is The Bach Project, by Andrea Agostini. Togheter with CatART by Diemo Swartz it forms a very expressive platform to work with sound, which was demonstrated by Aaron Einbond and Christopher Trapani in their paper titled Precise Pitch Control In Real Time Corpus-Based Concatenative Synthesis. Diemo Swartz presented work on Audio Mosaicing, it can be seen as a follow-up to AuidioGuild by Ben Hackbarth.
I also got to know the work by Thomas Grill, on his website a nice piece of software can be found a Python implementation of the Non Stationary Gabor Transform (NSGT). Another software system I got to know is the functional signal processing programming language FAUST
My personal highlights of the concert programme include the works by Johannes Kreidler, Aura Pon, Daniel Mayer, Alexander Schubert and the remarkable performance by Dexter Ford. The concept behind Soundlog by Johannes Kretz was also interesting.
What follows is about the Conference on Interdisciplinary Musicology (CIM2012) and the 15th international Conference of the Gesellschaft fur Musikfoschung. First this text will give information about our contribution to CIM2012: Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means and then a number of highlights of the conference follow. The joint conference took place from the 4th to the 8th of september 2012.
In 2012, CIM will tackle the subject of History. Hosted by the University of Göttingen, whose one time music director Johann Nikolaus Forkel is widely regarded as one of the founders of modern music historiography, CIM12 aims to promote collaborations that provoke and explore new methods and methodologies for establishing, evaluating, preserving and communicating knowledge of music and musical practices of past societies and the factors implicated in both the preservation and transformation of such practices over time.
### Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means
Our contribution ton CIM 2012 is titled “Revealing and Listening to Scales From the Past; Tone Scale Analysis of Archived Central-African Music Using Computational Means”:[CIM12_Submission.pdf]. The aim was to show how tone scales of the past, e.g. organ tuning, can be extracted and sonified. During the demo special attention was given to historic Central African tuning systems. The presentation I gave is included below and or available for “download”:[2012.09.05-Revealing_and_listening_to_scales_from_the_past__tone_scale_analysis_of_archived_Central-African_music_using_computational_means..ppt]
The work presented by Rytis Ambrazevicius et al. Modal changes in traditional Lithuanian singing: Diachronic aspect has a lot in common with our research, it was interesting to see their approach. Another highlight of the conference was the whole session organized by Klaus-Peter Brenner around Mbira music.
Rainer Polak gave a talk titled ‘Swing, Groove and Metre. Asymmetric Feels, Metric Ambiguity and Metric Transformation in African Musics’. He showed how research about rhythm in jazz research, music theory and empirical musicology ( amongst others) could be bridged and applied to ethnic music.
The overview Eleanore Selfridge-Field gave during her talk Between an Analogue Past and a Digital Future: The Evolving Digital Present was refreshing. She had a really clear view on all the different ways musicology and digital media can benifit from each-other.
From the concert programme I found two especially interesting: the lecture-performance by Margarete Maierhofer-Lischka and Frauke Aulbert of Lotofagos, a piece by Beat Furrer and Burdocks composed and performed by Christian Wolff and a bunch of enthusiastic students.
At the 2012 AAWM (Analytical Approaches To World Music) conference we presented a way to explore tone scales in the music of Central Africa. Since the audience consisted of (ethno)musicologists, the main focus of the presentation was on the applicication part, the technical aspects were only briefly mentioned.
Today a new version of the TarsosDSP library was released. TarsosDSP is a small library to do audio processing in Java. It features two new pitch detectors. An AMDF (Average Magnitude Difference Function) pitch detector, contributed by Eder Souza of Brazil and a faster implementation of YIN kindly provided by Matthias Mauch of Queen Mary University, London.
[](/releases/TarsosDSP/TarsosDSP-1.2/TarsosDSP-1.2-Examples/PitchDetector-1.2.jar)
Thursday the 3th of May I gave a guest lecture titled ‘Ethnic Music Analysis: Challenges & Opportunities’ it featured Tarsos as a Case Study. The goal was to identify the difficulties when dealing with ethnic music and to show a possible approach, the approach implemented by Tarsos.
The invitation to give the guest lecture came from Michael Cuthbert who is one of the driving forces behind music21. The audience was a small group of double majors in both musicology and computer science: the ideal profile to gather useful feedback.
After about a year of development and several revisions TarsosDSP has enough features and is stable enough to slap the 1.0 tag onto it. A ‘read me’, manual, API documentation, source and binaries can be found on the TarsosDSP release directory. The source is present in the\
What follows below is the information that can be found in the read me file:
TarsosDSP is a collection of classes to do simple audio processing. It features an implementation of a percussion onset detector and two pitch detection algorithms: Yin and the Mcleod Pitch method. Also included is a Goertzel DTMF decoding algorithm and a time stretch algorithm (WSOLA).
Its aim is to provide a simple interface to some audio (signal) processing algorithms implemented in pure JAVA. Some TarsosDSP example applications are available.
The following example filters a band of frequencies of an input file testFile. It keeps the frequencies form startFrequency to stopFrequency.
Head over to the TarsosDSP release repository and download the latest TarsosDSP library. To get up to speed quickly, check the TarsosDSP Example applications for inspiration and consult the API documentation. If you, for some reason, want to build from source, you need Apache Ant and git installed on your system. The following commands fetch the source and build the library and example jars: git clone https://JorenSix@github.com/JorenSix/TarsosDSP.git
cd TarsosDSP/build
ant tarsos_dsp_library #Builds the core TarsosDSP library
ant build_examples #Builds all the TarsosDSP examples
ant javadoc #Creates the documentation in TarsosDSP/doc
\
When everything runs correctly you should be able to run all example applications and have the latest version of the TarsosDSP library for inclusion in your projects. Also the Javadoc documentation for the API should be available in TarsosDSP/doc. Drop me a line if you use TarsosDSP in your project. Always nice to hear how this software is used.
Source Code Organization and Examples of TarsosDSP
The source tree is divided in three directories:
src contains the source files of the core DSP libraries.
test contains unit tests for some of the DSP functionality.
build contains ANT build files. Either to build Java documentation or runnable JAR-files for the example applications.
examples contains a couple of example applications with a Java Swing user interface:
SoundDetector show how you loudness calculations can be done. When input sound is over a defined limit an event is fired.
PitchDetector this demo application shows real-time pitch detection. When pitch is detected the hertz value is printed together with a probability.
PercussionDetector show the percussion (onset) dectection. Clapping your hands causes an event. This demo application also shows the influence of the two parameters on the algorithm.
UtterAsterisk a game with the goal to sing as close to a melody a possible. Technically it shows real-time pitch detection with YIN or MPM.
Spectrogram in Java shows a spectrogram and detected pitch, either live or from an audio file. It is interesting to see which frequencies are picked as fundamentals.
Goertzel DTMF decoding an implementation of the Goertzel Algorithm. A fancy user interface shows what goes on under the hood.
Audio Time Stretching -- Implementation in Pure Java Using WSOLA an implementation of a time stretching algorithm. WSOLA makes it possible to change the play back speed of audio without changing the pitch. The play back speed can be changed at any moment, even when there is audio playing.
The Amsterdam Music Hack Day is a full weekend of hacking in which participants will conceptualize, create and present their projects. Music + software + mobile + hardware + art + the web. Anything goes as long as it’s music related
The hackathon was organized at the NiMK(Nederlands instituut voor Media Kunst) the 25th and 24th of May. My hack tries to let a phone start a conversation on its own. It does this by speaking a text and listening to the spoken text with speech recognition. The speech recognition introduces all kinds of interesting permutations of the original text. The recognized text is spoken again and so a dreamlike, unique nonsensical discussion starts. It lets you hear what goes on in the mind of the phone.
The idea is based on Alvin Lucier’s I am Sitting in a Room form 1969 which is embedded below. He used analogue tapes to generate a similar recursive loop. It is a better implementation of something I did a couple of years ago.
The implementation is done with Android and its API’s. Both speech recognition and text to speech are available on android. Those API’s are used and a user interface shows the recognized text. An example of a session can be found below:
To install the application you can download “Tryalogue.apk”:[Tryalogue.apk] of use the QR-code below. You need Android 2.3 with Voice Recognition and TTS installed. Also needed is an internet connection. “The source”:[Tryalogue.zip] is also up for grabs.
The Dan Ellis implementation is nicely documented here: Robust Landmark-Based Audio Fingerprinting . To download, get info about and decode mp3’s some external binaries are needed:
```bash\
#install octave if needed\
sudo apt-get install octave3.2\
#Install the required dependencies for the script\
sudo apt-get install mp3info curl
mpg123 is not present as a package, install from source:\
wget http://www.mpg123.de/download/mpg123-1.13.5.tar.bz2\
tar xvvf mpg123-1.13.5.tar.bz2\
cd mpg123-1.13.5/\
./configure\
make\
sudo make install\
```
In mp3read.m the following code was changed (line 111 and 112):
```matlab\
mpg123 = ‘mpg123’; % was fullfile(path,[‘mpg123.’,ext]);\
mp3info = ‘mp3info’; % was fullfile(path,[‘mp3info.’,ext]);\
```
Then, the demo program runs flawlessly when executing octave -q demo_fingerprint.m.
Running the demo with the original code with GNU Octave, version 3.2.3 takes 152 seconds on a PC with a Q9650 @ 3GHz processor. A small tweak can make it run almost 8 times faster. When working with larger data sets (10k audio files) this makes a big difference. I do not know why but storing a hash in the large hash table was really slow (0.5s per hash, with 900 hashes per song…). Caching the hashes and adding them all at once makes it faster (at least in Octave, YMMV). The optimized version of “record_hashes.m”:[record_hashes.m.txt] can be found attached. With this alteration the same demo ran in 20s. When caching the data locally the difference is 11.5s to 141s or 12 times faster. The code with all the changes can be found here: “Robust Landmark-Based Audio Fingerprinting - optimized for Octave 3.2”:[fingerprint_fast.zip]. Please note again that the implementation is done by Dan Ellis (2009) ( available on Robust Landmark-Based Audio Fingerprinting) and I did only some small tweaks.
The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was Harmony and variation in music information retrieval.
During the talk by Xavier Serra rasikas.org was mentioned a forum with discussions about Carnatic Music. Since I could find a couple of discussions about pitch use on that forum I plugged Tarsos there to see if I could gather some feedback.
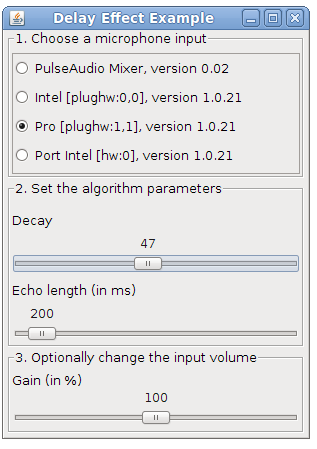
The DSP library for Taros, aptly named TarsosDSP, now includes an implementation of an audio echo effect. An echo effect is very simple to implement digitally and can serve as a good example of a DSP operation.
"":\[Delay.jar\]
The implementation of the effect can be seen below. As can be seen, to achieve an echo one simply needs to mix the current sample i with a delayed sample present in echoBuffer with a certain decay factor. The length of the buffer and the decay are the defining parameters for the sound of the echo. To fill the echo buffer the current sample is stored (line 4). Looping through the echo buffer is done by incrementing the position pointer and resetting it at the correct time (lines 6-9).
```java\
//output is the input added with the decayed echo\
audioFloatBuffer[i] = audioFloatBuffer[i] + echoBuffer[position] * decay;\
//store the sample in the buffer;\
echoBuffer[position] = audioFloatBuffer[i];\
//increment the echo buffer position\
position;\
//loop in the echo buffer\
if(position == echoBuffer.length)\
position = 0;\
```
To test the application, download and execute the “Delay.jar”:[Delay.jar] file and start singing in a microphone.
The source code of the Java implementation can be found on the TarsosDSP github page.





 </a>
</a>
 \
\
 The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The
The 13th International Society for Music Information Retrieval Conference took place in Porto, Portugal, October 8th-12th, 2012. This text contains links to some papers, toolkits, software presented there which are interesting for my research. Basically it contains my personal highlights of the conference. The  What follows is about the
What follows is about the  This post is about a hack I did for the 2012
This post is about a hack I did for the 2012 


 The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was
The 29th of February 2012 there was a symposium on Music Information Retreival in Utrecht. It was organized on the occasion of Bas de Haas’ PhD defense. The title of the study day was