I often play board games with my kids. One of them is an absolute board game fan while the other is a sore loser and only wants to play collaborative games. These games are played ‘against the board’ and you win, or lose, together. I myself also still have problems losing games so I do understand this predicament. Genetics…
Rock & Troll is one of those games. It is a chance based game where you collaboratively try to build a path to a treasure before the dragon reaches it. Every player has to flip a tile which is either a part of the path (good) or a dragon (very bad). To increase engagement during play I often add sound effects. I was thinking: this can be improved and automated. For example, by doing this when a dragon tile is flipped:
The idea is to unobtrusively detect game state and add sound effects at critical moments. The sound effect should be playing without too much lag, ideally within about 200ms, so it feels immediate and connected to the game event. To implement this a camera based system with robust, fast object detection seemed like the way to go.
Dragon detection
To detect dragons in a video stream I want to retrain an existing object-detection system. So two things need to happen: first a realistic, labeled dataset needs to be created. Then a system needs to be trained to detect the dragons. We do not want to label a massive dataset so we will use transfer learning to retrain an existing network. This existing network should already have learned basic features like edges, colors, geometries and other basic patterns. With the hope that this would result in robust detection, even with a limited dataset.
To create the dataset I wrote a small script which took a webcam picture every few seconds while I was manipulating the board and tiles. This resulted in about 130 pictures, some with no dragons and some with six, 300 labels in total. For annotating the dataset I used the free roboflow web-app which also hosts the final dragon dataset. After augmentation, the size of the dataset can be tripled. The command to extract images from a webcam looks like this on my system:
After some consideration for alternatives I landed on the YOLOv8 object-detection system: a robust and fast object-detection system. Additionally, it is well-documented, pytorch-based, easy-to-use and it has support for video streams. The annotated roboflow dataset can be downloaded in a YOLOv8 compatible format as well. Transfer learning, was based on the yolov8s.pt weights, which are downloaded automatically. With the system installed correctly and the dataset dowloaded, a local GPU based training command might look like this:
Once the system was trained - download the “model wheights here”:[dragons.pt] - a bit of “glue code”:[rock_n_troll_v8.py] is needed. The python script needs to stream images from a camera, here via open cv, and detect dragons in each image. Every time a new dragon is found, the sound effect is played. Note that the Roboflow website automatically trains a model as well which can be tried out with a webcam.
There are a few ways improve the robustness of the system. During a game there are only more and more dragons: if the script detects less dragons than before it is probably a false negative or there is occlusion. Additionally, the dragon tiles remain in the same location once they are placed on the board. This means that new dragons are expected only in certain regions of the image. Both heuristics can be used to together to improve robustness.
Notes
One of the reasons I bought a M1 mac with unified memory is for exactly these types of AI applications. After installing pytorch 2.0, the GPU acceleration resulted in a 10x training speed improvement. Training on a GeForce 1080 GTX from 2016 was still quite a bit faster, probably thanks to years of performance tuning targeting CUDA. It is clear that the mac GPU acceleration software ecosystem can use more effort, even system tools in macOS are limited: e.g. in the macOS activity monitor, GPU activity is very much an afterthought.
I am and hesitant to use cloud based GPU computing due to lack of control and privacy. I am not willing to send pictures from my kids to e.g. Google Cloud GPUs. The dependency on hardware of others might also limit the longevity of systems.
The ease-of-use, performance and accessibility of these deep-learning systems is great. Only a couple of years ago it would take months of hard work to maybe only approach similar detection performance. Adapting this idea for other board games and more types of tiles or board game events should be very possible.
I recently installed a couple of smart electrical sockets. The sockets only switch on when there is a solar energy surplus: when my rooftop solar panels produce more than the current energy consumption. I use these ‘solar sockets’ to charge the battery of an electric bike, for air conditioning and for charging other smaller devices. This post describes the components needed for such a system with the aim to inspire similar build.
Solar panels and a solar inverter with some form of readout.
A device to measure electrical energy use in a home.
Smart sockets with an easy to use API.
Some software to glue everything together.
1. ☀️ Solar panels and inverter
Most solar inverters have some form of API to readout the current solar panel output. In my case I use a SMA inverter which has two ways to extract this data: via Bluetooth and via wired ethernet. I found the wired ethernet solution to be the most reliable. The SMA inverter does use a somewhat annoying data formatting protocol but luckily there is an open source solution to decode the data: SBFspot
For SMA inverters, and possibly for others as well, there another option: the data is also automatically uploaded to a cloud based platform. This platform has an API which can be used to extract data on solar energy production. I do not like to be dependent on external cloud based software platforms, which might change at any time. Additionally, for real-time data cloud based platforms can be slow.
2. Measuring total electrical energy use
To measure total power use, I use an “Eastron SDM220M” measurement device which communicates with a server over a serial connection. There are adapters to translate serial Modbus to USB. The device is installed in my wiring closet by a professional: it is directly connected to the 60A mains and I would not advise to DIY it.
Alternatively, some places are equipped digital energy meters which might have a way for direct readout or readout via a cloud based API, after a few minutes. This might suffice for a solar socket install.
Energy use measurement might not be strictly needed for the ‘solar sockets’: if energy use is predictable it might be ok to simply switch the sockets on your average peak solar power. Perhaps combined with a local weather API. Finally we need to switch on some sockets.
3. Smart WiFi Socket
There are many smart WiFi sockets on the market. Most come with a smartphone app which allows you to control the socket from anywhere. Behind the scenes the sockets communicates with the vendor’s cloud based system over the internet. Additionally there are some integrations with systems like Apple Home, Amazon Alexa en Google Assistant. For fundamental\
infrastructure like sockets in my home I want to avoid dependencies on a external cloud based systems. Next to the concerns about privacy and ownership there is a very practical concern: the cloud based system might just stop working in a few years. Especially any dependency on a Google service is suspect. Also I am not convinced of Amazon Alexa’s future.
Luckily, there is Tasmota which provides open source firmware targeting many types of ‘smart’ devices including smart sockets. The tagline for Tasmota is ‘Total local control with quick setup and updates’. I bought a couple of Nous A1T Tasmota Smart WiFi sockets which come with Tasmota firmware. Switching the socket on is done by sending an HTTP GET request to an url, which can be scripted easily. There is some
4. Control software
A script glues everything together: it logs energy usage and solar output. It switches on the solar sockets when a surplus is detected and switches again when the surplus is gone. There is some additional logic which ensures that the socket remains on for at least an hour even if there is no solar surplus. This to ensure that batteries are charged to a minimal usable state.
In summary, here we presented a couple of building blocks to build ‘solar sockets’ which are on only when there is a energy surplus. By using simple API’s offered by Tasmota and locally running software, there is no dependency on (in the long term) unreliable cloud based systems which ensures the longevity of the build.
As an additional bonus, the solar sockets also serve as an indicator. A small LED shows when they are on, or, in other words, when there is solar energy surplus and when it is a good idea to switch on other electrical appliances.
This post is an efficient way to determine whether a predefined frequency is present in a signal. If such an algorithm can be found, it can serve as a basis for a modem. With a modem data is modulated and demodulated at the receiving side. The modulation allows data to be send over a transmission channel.
With the ability to detect the presence of audible frequencies a modem can transform symbols into a combination of frequencies and send data over sound. This is exactly what happens with DTMF in the sound below. DTMF is also used in the dailup sound.
Audio: dail tone sequence: which numbers are pressed?
Typically, determining the presence of frequencies in a signal is done with an FFT: an FFT divides a signal into e.g. 512 linearly spaced frequency bands and determines the magnitude of each of these frequencies. The annoying thing is that a probe frequency can be right in between two bands: sample rate, FFT size and the frequency to look for need to be carefully chosen to reliably detect a frequency. Also, it is computationally inefficient to calculate the magnitudes for all frequency bands if only one band is actually needed.
Luckily there is an alternative approach which looks like the calculating the FFT but for only one predetermined frequencies. This algorithm is known as the Goertzel algorithm and is used in DTMF dail tone encoding and decoding. With the standard Goertzel algorithm it is still needed to consider sample rate and the frequency of interest.
Recenlty I needed a piece of ANSI c code to detect the magnitude of an arbitrary frequency for a project. The following is a C implementation of this algorithm. It uses the C support for complex numbers in the complex.h header:
Below you can try out the algorithm. You can choose a frequency to detect and a playback frequency. The magnitude of the frequency is reported via the slider. The demo uses a javascript translation of the code above.
Dual-tone Multi-Frequency - DTMF
DTMF in the browser.
On the right you can find a demo of dual tone frequency modulation and demodulation. A combination of frequencies is played and immediately detected.
The green bars show which frequencies have been detected. If for example 1209 Hz is detected together with 770 Hz then this means that we are looking for the symbol in the first column on the second row. Both the first column and the second row are highlighted in green. At that spot we see 4 so we can decode a 4. By using 2 combinations of four frequencies a total number of 16 symbols can be encoded.
Note that this code does not simply highlight the button press directly but encodes the symbol in audio, feeds it into an Web Audio API format and decodes audio, the result of the decoding step highlights the row and column detected.
Both Ghent University’s research output tracking system and Flanders FWO academic profile do not allow to enter software as research output. The focus is still solely on papers, even when custom developed research software has become a fundamental aspect in many research areas. My role is somewhere between that of a ‘pure’ researcher and that of a research software engineer which makes this focus on papers quite relevant to me.
The paper aims to make the recent development on Olaf‘count’. Thanks to the JOSS review process the Olaf software was improved considerably: CI, unit tests, documentation, containerization,… The paper was a good reason to improve on all these areas which are all too easy to neglect. The paper itself is a short, rather general overview of Olaf:
“Olaf stands for Overly Lightweight Acoustic Fingerprinting and solves the problem of finding short audio fragments in large digital audio archives. The content-based audio search algorithm implemented in Olaf can identify a short audio query in a large database of thousands of hours of audio using an acoustic fingerprinting technique.”
The C programming language is deceptively simple. The syntax is straightforward, C has a limited amount of keywords and a small standard library. The first edition of the classic book ‘The C Programming Language’ is only about 200 pages. And yet, when programming in C, it is hard to avoid the many exiting footguns: integer type conversions, unchecked indexes and memory leaks can all cause subtle problems. This is part of the appeal of C: shooting yourself in the foot does make you feel alive. Here I want to focus on ways to check for memory leaks for C programs.
Memory leaks come about when memory is claimed but is never released again. If this is done in a loop or during a long running program, the claimed memory adds up and eventually the system may run out of memory. A memory leak is less a problem if a program forgets to free a small amount of memory it only claims once: after program shut down, the operating system reclaims all memory anyhow. However, it does feels very dirty to not clean up after oneself. And I for one, am not a dirty boy.
Another reason to look for memory use and leaks is when you are programming for embedded devices. For these systems memory is very limited: in that world 500kB RAM is considered a massive amount of memory. I have been busy programming a scalable audio search system called Olaf which targets both traditional computers, embedded systems and browsers (via WebAssembly). It is clear that memory use — and memory leaks — need to be kept in check to pull this of.
Now, these memory leaks might not be easy to spot by inspecting the code. There are tools which help to spot memory management problems. One of these is valgrind which is currently not easy to use on Apple system with ARM processors. Luckily there is an alternative which is probably already installed on macOS via the XCode Command Line Tools a command line tool aptly called leaks. To quote the apple documentation on leaks, leaks reports:
the address of the leaked memory
the size of the leak (in bytes)
the contents of the leaked buffer
The most straightforward use of leaks is to run a program and generate a report after program shutdown. See below to run a memory leak inspection, in this case for the bin/olaf_c program which indexes an audio file in a key-value store. For CI purposes it is practical to know that leaks has an exit status of zero only when no leaks have been found. The exit status can be used in an automated test script to break a build if a leak is detected. The --quiet option can be practical in such setting.
leaks --atExit -- bin/olaf_c store audio.raw audio
In the case of Olaf I made a classic mistake: I had called free() on hash table but I needed to call the hash table destructor: hash_table_destroy() which freed not only the hash table itself but also all memory associated with the hash table entries. After a quick fix the leaks command showed no more leaks!
Output of the `leaks` command which shows where a memory leak can be found.
General takaways
leaks is an easy to use memory leak inspector provided by Apple. It is an alternative for valgrind.
Memory leaks can be checked automatically using the leaks exit status in a CI-script. This makes spotting leaks timely and more straightforward to fix.
Programmers should at least once try to target embedded devices. It makes you conscious of the wealth of resources available when targeting modern computing devices.
This post details how I went about optimizing a C application. This is about an audio search system called Olaf which was made about 10 times faster but contains some generally applicable steps for optimizing C code or even other systems. Note that it is not the aim to provide a detailed how-to: I want to provide the reader with a more high-level understanding and enough keywords to find a good how-to for the specific tool you might want to use. I see a few general optimization steps:
The zeroth step of optimization is to properly **question the need** and balance the potential performance gains against added code complexity and maintainability.
Once ensured of the need, the first step is to **measure the systems performance**. Every optimization needs to be measured and compared with the original state, having automazation helps.
Thirdly, the second step is to **find performance bottle necks**, which should give you an idea where optimizations make sense.
The third step is to **implement and apply** an optimization and measuring its effect.
Lastly, **repeat** steps zero to three until optimization targets are reached.
More specifically, for the Olaf audio search system there is a need for optimization. Olaf indexes and searches through years of audio so a small speedup in indexing really adds up. So going for the next item on the list above: measure the performance. Olaf by default reports how quickly audio is indexed. It is expressed in the audio duration it can process in a single second: so if it reports 156 times realtime, it means that 156 seconds of audio can be indexed in a second.
The next step is to find performance bottlenecks. A profiler is a piece of software to find such bottle necks. There are many options gprof is a command line solution which is generally available. I am developing on macOS and have XCode available which includes the “Instruments - Time Profiler”. Whichever tool used, the result of a profiling session should yield the time it takes to run each functions. For Olaf it is very clear which function needs optimization:
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
The function is a max filter which is ran many, many times. The implementation is using a naive approach to max filtering. There are more efficient algorithms available. In this case looking into the literature and implementing a more efficient algorithm makes sense. A very practical paper by Lemire lists several contenders and the ‘van Herk’ algorithm hits the sweet spot between being easy to implement and needing only a tiny extra amount of memory. The Lemire paper even comes with example c max-filters. With only a slight change, the code fits in Olaf.
After implementing the change two checks need to be done: is the implementation correct and is it faster. Olaf comes with a number of functional and unit checks which provide some assurance of correctness and a built in performance indicator. Olaf improved from processing audio 156 times realtime to 583 times: a couple of times faster.
After running the profiler again, another method came up as the slowest:
//Naive implementationfloat olaf_ep_extractor_max_filter_time(float *array, size_t array_size) {
float max = -10000000;
for (size_t i = 0; i < array_size; i++) {
if (array[i] > max) max = array[i];
}
return max;
}
src: naive implementation of finding the max value of an array.
This is another part of the 2D max filter used in Olaf. Unfortunately here it is not easy to improve the algorithmic complexity: to find the maximum in a list, each value needs to be checked. It is however a good contender for SIMD optimization. With SIMD multiple data elements are processed in a single CPU instruction. With 32bit floats it can be possible to process 4 floats in a single step, potentially leading to a 4x speed increase - without including overhead by data loading.
Olaf targets microcontrollers which run an ARM instruction set. The SIMD version that makes most sense is the ARM Neon set of instructions. Apple Sillicon also provides support for ARM Neon which is a nice bonus. I asked ChatGPT to provide a ARM Neon improved version and it came up with the code below. Note that these type of simple functions are ideal for ChatGPT to generate since it is easily testable and there must be many similar functions in the ChatGPT training set. Also there are less ethical issues with ‘trivial’ functions: more involved code has a higher risk of plagiarization and improper attribution. The new average audio indexing speed is 832 times realtime.
src: a ARM Neon SIMD implementation of a function finding the max value of an array, generated by ChatGPT, licence unknown, informed consent unclear, correct attribution impossible.
Next, I asked ChatGPT for an SSE SIMD version targeting the x86 processors but this resulted in noticable slowdown. This might be related to the time it takes to load small vectors in SIMD registers. I did not pursue the SIMD SSE optimization since it is less relevant to Olaf and the first performance optimization was the most significant.
Finally, I went over the code again to see whether it would be possible exit a loop and simply skip calling olaf_ep_extractor_max_filter_time in most cases. I found a condition which prevents most of the calls without affecting the total results. This proved to be the most significant speedup: almost doubling the speed from about 800 times realtime to around 1500 times realtime. This is actually what I should have done before resorting to SIMD.
In the end Olaf was made about ten times faster with only two local, testable, targeted optimizations.
General takeways
Only think about optimization if there is a need and set a target: otherwise it is infinite.
Try to find a balance between complexity, maintainability and performance.
Changing a naive algorithm to a more intelligent one can have a significant performance increase. Check the literature for inspiration.
Check for conditions to skip hot code paths before trying fancy optimization techniques.
Profilers are crucial to identify where to optimize your code. Applying optimizations blindly is a waste of time.
Try to keep optimizations local and testable. Sprinkling your code with small, hard to test performance oriented improvements might not be worthwile.
SIMD generated by ChatGPT can be a very quick way to optimize critical, hot code paths. I would advise to only let ChatGPT generate small, common, easily testable code: e.g. finding the maximum in an array.
The aptly named emulator Previous allows you to emulate NeXT hardware on modern platforms. It allows you to run NeXTStep and run software made for this environment. I have prepared a downloadable disk image for this emulator to experiment with an early version of MAX, a visual programming environment for music applications.
I am interested in the early days of MAX an influential visual programming environment geared towards music applications. This software originated at IRCAM and an early version was build for the NeXTcube and required a specialized soundcard (ISPW). I have been lucky to have been able to restore a NeXTCube with an ISPW soundcard but this hardware is extremely rare.
A functioning NeXTcube is already a rare collectors item and the ISPW soundcard is even more uncommon. The card was developed at IRCAM and later commercialised by Ariel Inc. which brought it to market right when NeXT announced to phase out hardware production. Overnight, the market for NeXT peripheral hardware collapsed and nobody wanted to buy an expensive soundcard for an obsolete hardware platform. The soundcard was never mass-produced: there are only the prototype boards made at IRCAM and a few batches of the commercial version. The total number ISPW soundcards must have been around a few dozen worldwide, in 1992. Now, over 30 years later, it is virtually impossible to find an ISPW card. Running an early version of MAX on original hardware is nearly impossible.
\
Fig: MAX 0.25 running in the Previous emulator on a modern MacOS system.
To make experiencing an early version of MAX more accessible I have prepared a disk image for the Previous emulator. The emulator emulates several NeXT machines and lets you run NeXT software on modern machines. The disc image uses NeXTStep 3.3 for OS and has MAX 0.25 pre-installed. Several NeXT machines can be emulated by Previous but, crucially for MAX, the ISPW soundcard is not emulated. This puts a severe limitation on MAX: there is no audio or MIDI input or output. However, you can start MAX in simulation mode and experience the patcher and see the original documentation and have a feel for the original supplied patches and follow the logic of patches.
To run MAX, download the disc image with NeXTStep and MAX [about 100MB]. By downloading this material you agree to use it only for academic, educational, historic or documentary use and not for commercial or other purposes. The zip-file also contains some information on how to get started and boot the system. Note that it has only been tested on an M1 mac.
Fig: the NeXTCube with the Ariel ProPort and MIDI input/output interface.
Recently, I was able to restore a NeXTCube and install an early version of MAX - a graphical music programming environment. However, a crucial part of the system was missing: there was no way to do MIDI input/output. MIDI is used to connect controllers, keyboards, synthesizers or other musical instruments to the audio workstation. The NeXTCube itself has a serial port which allows users to connect MIDI devices. Next to the serial port on the mainboard, the NeXTCube I am working with also has a RS-422 serial port on the ISPW ‘soundcard’. The serial port uses RS-422 and mini DIN 8 connectors which provide MIDI input and output. While the MIDI data bytes are transmitted according to spec, the connector and the electrical signals are not compatible with standard MIDI.
Fig: the IRCAM/Ariel ISPW soundcard with mini DIN-8 RS-433 serial port on the right.
For MIDI I/O we need a device which allows to connect the RS-422 MIDI to both legacy MIDI devices and to computers via USB MIDI. If a MIDI event arrives from the NeXTCube’s RS-422 it needs to be passed through to the USB and legacy MIDI ports and the other way around. The Teensy platform is ideal: it supports hardware serial and USB MIDI. In this retro-computing project, it seems wasteful to use the 600MHz Teensy 4.0 only for message passing: the Teensy has much more computing power than NeXTcube but it is cheap, easy to program, available and practical.
The RS-422 serial port uses –6V to 6V logic which needs to be transformed to the 0V to 3.3V logic for the Teensy microcontroller. A PCB provides this capability and is connected to a hardware serial port of the Teensy. The pinout of the RS-422 port was measured via a scope and matched the documentation. The Teensy has an usbMIDI mode and can present itself as a standard MIDI device to a PC. Two opto-isolated legacy MIDI DIN-5 ports were connected to another hardware serial port. The software on the Teensy conducts the “three-way MIDI message passing”:[midi_passthrough.ino].
Vid: Max/FTS FM synth reacting to USB MIDI input.
The electronics were fixed into a reused metal enclosure. The front panel of the enclosure was replaced by a custom 3D printed panel. The front contains the RS-422 port, two MIDI DIN 5 ports and a micro usb port either for power alone or MIDI messages and power. Feel free to check out the “OpenSCAD design with a level MINI DIN8 hole”:[midi_box.scad].
With a working MIDI interface for the NeXTcube allows interfacing with MIDI keyboards and controllers. It can also be used to measure roundtrip latency. MIDI to sound latency determines how long it takes between pressing a MIDI key and hearing sound. MIDI to MIDI roundtrip latency determines how long it takes to process, parse and return a MIDI message. For a responsive, reliable system both types of latencies should be constant and preferably in the range of 10ms or below.
Fig: Measured MIDI roundtrip latency on the ISPW board for the NeXTCube.
Measuring the MIDI roundtrip latency shows that the system is able to respond in 3.6+–0.4 ms (N=300). A combination of a MAX patch and “Teensy firmware”:[next_midi_roundtrip_latency.ino] was used to measure this automatically. The MIDI-to-audio latency was measured a few times manually and always was around 13ms. These figures show that the system is ideal for low-latency real-time music making in its default configuration. In MAX the audio buffer sizes could be reduced to achieve an even lower latency but with the risk of running into buffer underruns and audio glitches.
The NeXTcube is an influential machine in computing history. The NeXTcube, with an additional soundcard, was also one of the first off-the-shelf devices for high-quality, real-time music applications. I have restored a NeXTcube to run an early version of MAX, an environment for interactive music applications.
The NeXTcube context and the IRCAM Musical Workstation
In 1990 NeXT started selling the NeXTcube, a high-end workstation. It introduced or brought together many concepts (objective-c, the Mach kernel, postscript, an app store) which are still in use today. The NeXTcube’s influence is especially felt in the Apple ecosystem with Mac OS X, iPhones and iPads being direct decedents of NeXT’s line of computers.
Due to its high price, the NeXTcube was not a commercial success. It mainly ended up at companies or in the hands of researchers. Two of those researchers, Tim Berners-Lee and Robert Cailliau created the first http server and web browser at CERN on a NeXTcube. Coincidently, the http software was publicly released exactly 30 years ago today. Famously, the cube was also used to develop games like the original Doom and Quake. So yes, the NeXTcube runs Doom.
Fig: the NeXTcube's design stood out compared to the contemporary beige box PCs.
Less well known is the fact that the NeXTcube is also one of the first computing devices capable enough for real-time, high-quality interactive music applications. In the mid 1980s this was still a dream at IRCAM, a French research institute with the aim to ‘contribute to the renewal of musical expression through science and technology’. The bespoke hardware and software systems for music applications from the mid 80s were further developed and commercialised in the early 90s. Together these developments resulted in a commercially available version of the “IRCAM Musical Workstation (IMW)”, an early, if not the first, off-the-shelf computer for interactive music applications.
The IRCAM Musical Workstation (IMW), sometimes called the IRCAM Signal Processing Workstation (ISPW), consisted of several hard and software modules working together to enable interactive music applications. An important component was a ‘soundcard’ which had two beefy 40MHz i860 intel CPUs for DSP. When installed in the NeXTcube, the soundcard had more computing power than the rest of the computer. This is similar to modern computers where some graphics cards have more raw computing power than the main CPU. The soundcard was developed at IRCAM and commercialized by Ariel inc. under the name “Ariel ProPort”.
The IRCAM Ariel DSP coprocessor, soundcard.
A few software environments were developed at IRCAM which made use of the new hardware. One was Animal, another, was the much more influential MAX. MAX provides a graphical programming environment specific for music applications. Descendants of MAX are still used today, see Ableton Max for Live and Pure Data. I consider the introduction of MAX as a pivotal point in electronic music history. Up until the introduction of MAX, creating a new electronic music instrument meant bespoke hardware development. With MAX, this is done purely in software. This made electronic sound or instrument design not only faster but also accessible to a much wider audience of composers, artists and thinkerers.
The NeXTcube at IPEM
IPEM was an early electronic music production studio embedded at Ghent University, Belgium. Now it is active as a internationally acclaimed research center for interdisciplinary music research. In the early 90s IPEM acquired a NeXTcube Turbo with an internal diskette drive, SCSI hard disk, NextDimension color graphics card and an Ariel ProPort DSP/ISPW module. The cube was preserved well and came with many of the original software, books and manuals. I have been trying to get this machine working and configure it as an “IRCAM Musical Workstation”.
IPEM's NeXTcube with IRCAM Ariel ProPort.
There were a few practical issues: the mouse was broken, the hard drive unreliable and the main system fan loud and full of dust. The mouse had a broken cable which was fixed, the hard drive was replaced by a SCSI2SD setup and the fan was replaced with a new one. On the software side of things, the Internet Archive hosts NeXTStep 3.3 which, after many attempts, was installed on the cube. Unfortunately there seemed to be a compatibility issue. The Ariel ProPort kernel module did not work. I started over installed NeXTStep 3.1, with the same result. Finally, I installed NeXTStep 3.0 which was compatible with the kernel module and MAX/FTS!
Vid: Max/FTS with a commercial Ariel soundcard running on a NeXTcube Turbo.
The restoration of the IRCAM Signal Processing Workstation instruments fits in a university project on living heritage The idea is to get key historic electronic music instruments into the hands of researchers and artists to pull the fading knowledge on these devices back into a living culture of interaction. This idea already resulted in an album: DEEWEE Sessions vol. 01. Currently the collection includes a 1960s reverb plate, an EMS Synti 100 analog synthesizer from the 70s, a Yamaha DX7 (80s) and finally the NeXTCube/ISPW represents the early 90s and the departure of physical instruments to immaterial software based systems.
Acknowledgements & Further reading
This project was made possible with the support of the Belgian Music Instrument Museum and IPEM, Ghent University. I was fortunate to get assistance by Ivan Schepers and Marc Leman at IPEM but also by the main developers of MAX: Miller Puckette. I would also like to thank Anthony Agnello formerly at Ariel Corp for additional image material and info. I also found the WinWorld and NeXTComputers communities and resources extremely helpful. Below a picture from the CERN public archives and Ghent University Archive is included. Thanks a lot!
Vid: the trigger box set in recording mode via a button or a MIDI key press.
A while back I have build a trigger box. Such device can be used for various synchronisation tasks. It can be used to synchronise camera’s, capture devices and sensors. All compatible devices have a 5V TTL input, often a BNC connector. For a camera, TTL input could control the shutter time. For a sensor a TTL clock could determine the sample time or simply be registered along side an other data stream. The trigger box allows to either pass-through (or block) an incoming TTL clock. It also outputs a recording level.
There are two ways to use the trigger box. The first is by operating a manual switch to start (and later stop) a recording. When recording, the recording level output is set to 5V and the clock at the CLOCK IN is passed through to the CLOCK OUT port. The second way to set the recording state is by MIDI over USB. While a MIDI key is pressed, the recording state is high, when the key is released the state is low. The MIDI key input makes it compatible and controllable from any DAW. Both ways are shown in the video.
For practical reasons there are two microcontrollers in the device, a Teensy 3.2 and an Arduino. The Arduino is there for its 5V capabilities and is essentially a rather beefy level-shifter. The Teensy is there for the USBMIDI compatibility and controls everything.
For aesthetic reasons the trigger box has been build into a 1950s ‘Sieger portable explosive gas detector’. I did not feel too bad about gutting the original electronics since a battery leak had destroyed most of it. Also, the late WII era knobs are still unmatched for durability and tactile satisfaction.
Today I have released Gabber a bit of code to transform audio from the time domain to a constant-Q frequency domain in the browser. To be more precise it does a constant-Q non-stationary Gabor transform. The heavy-lifting is done by ‘the gaborator’, a C library by Andreas Gustafsson.
I have compiled the Gaborator library to WebAssembly, added some glue code to bridge the Javascript and WASM worlds, implemented a Web Audio AudioWorkletProcessor to transform audio in the background and and finally visualized the results via WebGL2.
There is a Gabber live demo below. If you press start and grant microphone access, incoming audio is transformed and plotted onto a canvas. Thanks to WebAssembly and WebGL2 this should run relatively smoothly even on less powerful devices. Please do play around with the perspective slider.
While Gabber is currently a proof of concept, with some attention the library could be used as a front end for browser based music information retrieval applications. My main goal with Gabber is to use it in educational settings to explain the properties of sound, and more concretely pitch, via spectrograms and interactive demos. Also I plan to use it in a browser based tool to extract pitch patterns from music.
I have presented DiscStitch at the MIR (Music Information Retrieval) get together at the Deezer headquarters in Paris.
DiscStitch is a solution to identify, align and mix digitized audio originating from (overlapping) laquer discs. The main contribution lays in the novel audio to audio alignment algorithm which is robust against some speed differences and variabilities.
I have updated Olaf - the Overly Lightweight Acoustic Fingerprinting system. Olaf is a piece of technology that uses digital signal processing to identify audio files by analyzing unique, robust, and compact audio characteristics - or “fingerprints”. The fingerprints are stored in a database for efficient comparison and matching. The database index allows for fast and accurate audio recognition, even in the presence of distortions, noise, and other variations.
Olaf is unique because it works on traditional computing devices, embedded microprocessors and in the browser. To this end tried to use ANSI C. C is a relatively small programming language but has very little safeguards and is full of exiting footguns. I enjoy the limitations of C: limitations foster creativity. I also made ample use of the many footguns C has to offer: buffer overflows, memory leaks, … However, with the current update I think most serious bugs have been found. Some of the changes to Olaf include:
Fixed a rather nasty array out of bounds bug. The bug remained elusive due to the fact that a segfault was rare on macOS. Linux seems to be more diligent in that regard.
Added a quick way to skip already indexed files. Which improves usability significantly when working with larger datasets.
Improved command line output and fixed incorrectly reported times. The reported start and stop time of a query was wrong and is now fixed.
Olaf now supports caching fingerprints in simple text files. This makes fingerprint extraction much faster since all cores of the system can be used to extract fingerprints and dump them to text files. Writing prints to the database from multiple threads is slow since they need to wait for access to the locked database. There is also a command to store all cashed fingerprints in a single go.
Added support for basic profiling with gprof. The profiler shows where optimizations can have the most impact.
Olaf now includes an algorithm for efficient max-filtering. The min-max filter algorithm by Daniel Lemire is implemented. The profiler showed that most time was spend during max-filtering: replacing the naive max-filter with the Lemire max-filter improved performance drastically.
CI with Github Actions which checks if checked in sources compile and tests some of the basic functionality automatically.
Updated the Zig build script for cross-compilation and updated the pre-build Windows version.
Tested the system with larger databases. The FMA-full datasets, which comprises almost a full year of audio was indexed and queried without problems on a single pc. The limits of Olaf with respect to indexed size is probably a few times larger.
Tested, fixed and improved the ‘memory database’ version. Also added documentation to the readme.
Made a basic web example to call the WASM version of Olaf.
Added an ESP32 example, showing how Olaf can run on this microprocessor. It runs without an external microphone but uses a test audio file. Previously some small changes were needed to Olaf to run on the ESP32, now the exact same code is used.
Anyhow, what originally started as a rather quick and dirty hack has been improved quite a bit. The takeaway message: in the world of software it does seem possible to polish a turd.
As a way to get to know the Rust programming language I have developed a couple of practical tools for OSC and MIDI debugging. OSC and MIDI are protocols which are almost always used for applications dealing with music. In these applications latency should be kept in check. Languages with garbage collection (Java, Go) and scripting languages (Ruby, Python, …) are hard to tune for low-latency applications and do not really have real-time guarantees. Rust, as a modern alternative for C/C, is a better fit for cross platform CLI low-latency applications.
This opens a couple of possibilities which are discussed below.
Sending UDP messages from the browser
One of the ways to send OSC messages from a browser to a local network is by using the MIDI out capability of browsers and - using mot - translating MIDI to OSC an example can be seen below.
Fig: sending an UDP message to a network from a Browser using a the mot MIDI to OSC bridge, click the image for a better readable version.
Measuring UDP message latency
Both MIDI and OSC can be seen as rather general data encapsulation protocols with wide support in terms of libraries and cross platform support. Their value goes beyond mere musical applications. The same holds for mot. In this example we are using mot to measure UDP message latency between two hosts.
On the first host we send MIDI messages from MIDI device 0 over OSC to another host with e.g. mot midi_to_osc 192.168.1.12:3000 /m 0. At the other host we receive the OSC messages and send them to a virtual device: mot osc_to_midi 192.168.1.12:3000 /m 6666.
At the second host we return messages from the virtual device to the first host: mot midi_to_osc 192.168.1.4:5000 /m 1. Perhaps you first need to do mot midi_to_osc -l to find the index of the virtual device. As a final step the messages can be received at the first host and returned to the original midi device. On the first host: mot osc_to_midi 192.168.1.4:5000 /m 0.
If the original MIDI device is a Teensy running the “roundtrip patch” then finally the roundtrip time is accurately measured and shown in the serial console. I am sure the previous text is cromulent, totally not contrived and not confusing. Anyway, to make it more confusing: this is what happens when you use a single host to do midi to osc to midi to osc to midi and use the loopback networking device:
Fig: MIDI to OSC to MIDI to OSC to MIDI roundtrip latency.
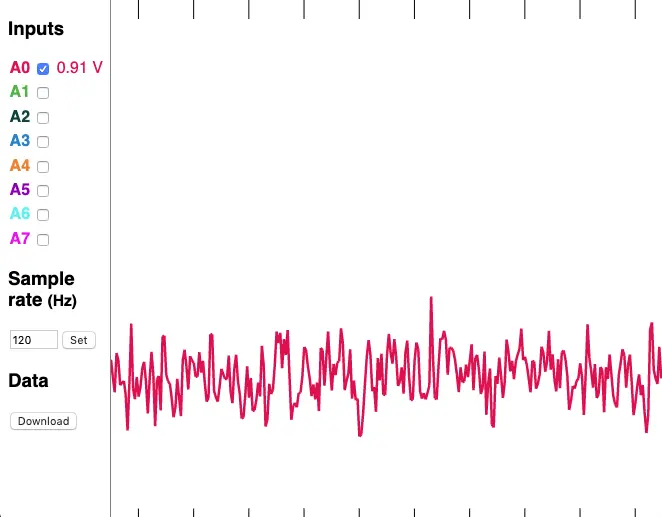
Visualizing sensor data in the browser
Fig: Sensor data as MIDI.
When capturing sensor data on microcontrollers, data can be encoded into MIDI. This makes almost any sensor practically useful in Ableton Live or similar environments. It also makes it compatible with all other MIDI supporting devices. With mot it becomes trivial to send MIDI encoded sensor data over OSC e.g. to a central place to log that data.
Another use case is to visualize the incoming data in real-time. A single web page which reads and visualizes incoming MIDI-sensor data becomes much more useful if streams from other devices can be visualized as well with the mot midi_to_osc and mot osc_to_midi commands.
Cross-platform support
With the Rust compiler it is relatively easy to cross-compile for different targets. There is however an important limitation in mot. Windows has no support for virtual MIDI ports which limits the usefulness of mot on that platform.
Fig: Advances in Speech and Music Technology book cover.
I have recently published an chapter in an academic book published by Springer. The topic of the book is of interest to me but can be perceived as rather dry: Advances in Speech and Music Technology.
The chapter I co-authored presented two case studies on detecting duplicates in music archives. The fist case study deals with segmentation reuse in an archive of early electronic music. The second with meta-data reuse in an archive of a public broadcaster containing digitized commercial shellac disc recordings with many duplicates.
Duplicate detection being the main topic, I decided to title the article Duplicate Detection for for Digital Audio Archive Management. It is easy to miss, and not much is lost if you do, but there is a duplicate‘for’ in the title. If you did detect the duplicate you have detected the duplicate in the duplicate detection article. Since I have fathered two kids I see it as an hard earned right to make dad-jokes like that. Even in academic writing.
It was surprisingly difficult to get the title published as-is. At every step of the academic publishing process (review, editorial, typesetting, lay-outing) I was asked about it and had to send an email like the one below. Every email and every explanation made my second-guess my sense of humor but I do stand by it.
From: Joren \
To: Editors ASMT \
\
Dear Editors, \
\
I have updated my submission on easychair in...\
\
I would like to keep the title however as is an attempt at word-play. These things tend to have less impact when explained but the article is about duplicate detection and is titled 'Duplicate detection for for digital audio archive management'. The reviewer, attentively, detected the duplicate 'for' but unfortunately failed to see my attempt at humor. To me, it is a rather harmless witticism.
Regards
Joren
</pre>
Anyway, I do think that humor can serve as a gateway to direct attention to rather dry, academic material. Also the message and the form of the message should not be confused. John Oliver, for example, made his whole career on delivering serious sometimes dry messages with heaps of humor: which does not make the topics less serious. I think there are a couple of things to be learned there. Anyway, now that I have your attention, please do read the author version of Duplicate Detection for for Digital Audio Archive Management: Two Case Studies.
TarsosDSP is a Java library for audio processing I have started working on more than 10 years ago. The aim of TarsosDSP is to provide an easy-to-use interface to practical music processing algorithms. Obviously, I have been using it myself over the years as my go-to library for audio-processing in Java. However, a number of gradual changes in the java ecosystem made TarsosDSP more and more difficult to use.
Since I have apparently not been the only one using it, there was a need to give it some attention. During the last couple of weeks I have found the time to give it this much needed attention. This resulted in a number of updates, some of the changes include:
Change of the build system from Apache Ant to Gradle
Make use of Java Modules to make TarsosDSP compatible with the ModulePath introduced in Java 9.
Packaged the software into a maven compatible format, which makes it easy to use as a dependency.
CI with GitHub actions to automatically build and test the software.
Updated some examples shipped with the TarsosDSP. I have still still some examples to verify.
Improved handling of errors on reading audio via ffmpeg
\
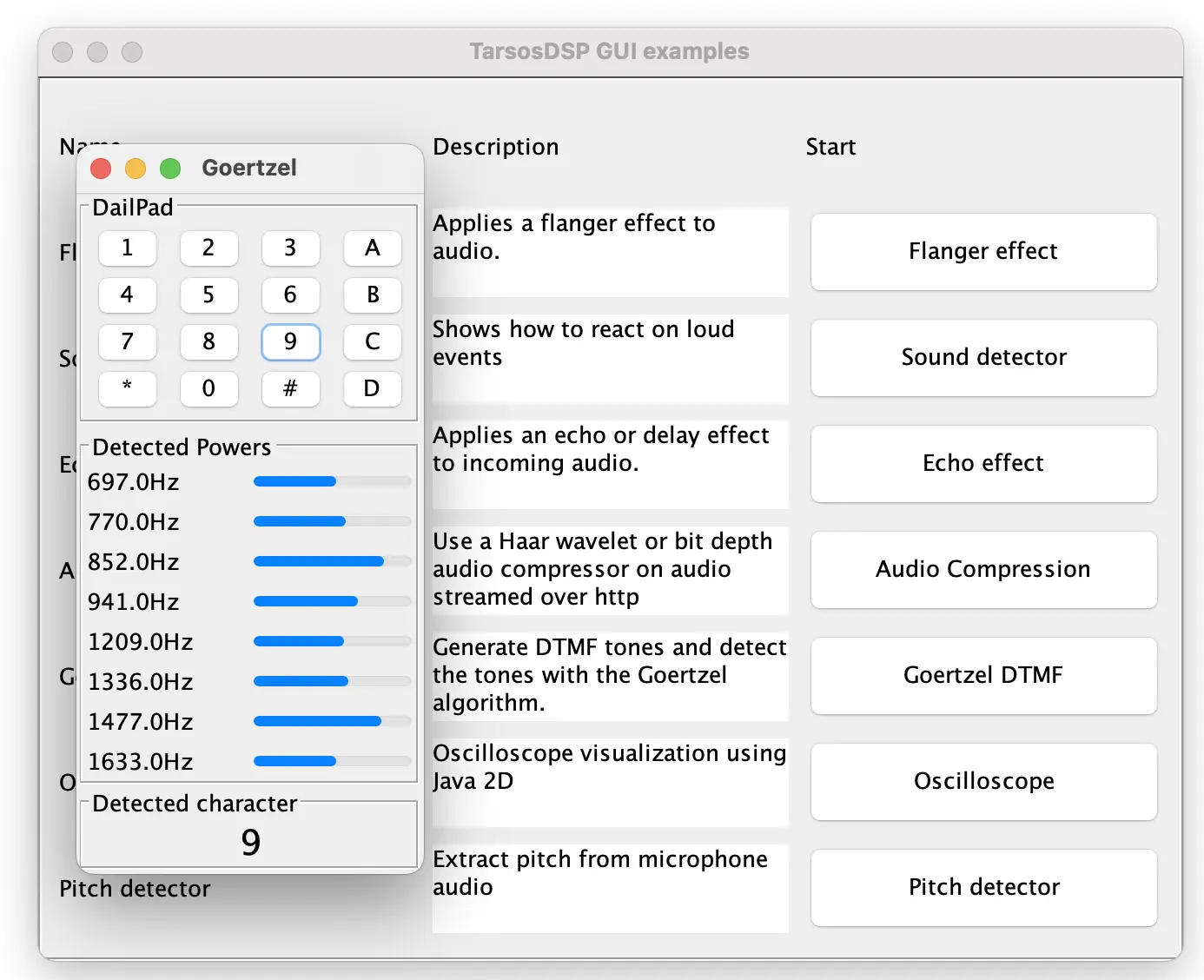
Fig: The updated TarsosDSP release contains many CLI and GUI example applications.
Notably the code of TarsosDSP has not changed much apart from some cosmetic changes. This backwards compatibility is one of the strong points of Java. With this update I am quite confident that TarsosDSP will also be usable during the next decade as well.
This blog has been running on Caddy for the last couple of months. Caddy is a http server with support for reverse proxies and automatic https. The automatic https feature takes care of requesting, installing and updating SSL certificates which means that you need much less configuration settings or maintenance compared with e.g. lighttpd or Nginx. The underlying certmagic ACME client is responsible for requesting these certificates.
Before, it was using lighttpd but the during the last decade the development of lighttpd has stalled. lighttpd version 2 has been in development for 7 years and the bump from 1.4 to 1.5 has been taking even longer. lighttpd started showing its age with limited or no support for modern features like websockets, http/3 and finicky configuration for e.g. https with virtual domains.
Caddy with Ruby on Rails
I really like Caddy’s sensible defaults and the limited lines of configuration needed to get things working. Below you can find e.g. a reusable https enabled configuration for a Ruby on Rails application. This configuration does file caching, compression, http to https redirection and load balancing for two local application servers. It also serves static files directly and only passes non-file requests to the application servers.
If you are self-hosting I think Caddy is a great match in all but the most exotic or demanding setups. I definitely am kicking myself for not checking out caddy sooner: it could have saved me countless hours installing and maintaining https certs or configuring lighttpd in general.
JNI is a way to use C or C code from Java and allows developers to reuse and integrate C/C in Java software. In contrast to the Java code, C/C code is platform dependent and needs to be compiled for each platform/architecture. Also it is generally not a good idea to make users compile a C/C library: it is best provide precompiled libraries. As a developer it is, however, a pain to provide binaries for each platform.
With the dominance of x86 processors receding the problem of having to compile software for many platforms is becoming more pressing. It is not unthinkable to want to support, for example, intel and M1 macOS, ARM and x86_64 Linux and Windows. To support these platforms you would either need access to such a machine with a compiler or configure a cross-compiler for each system: both are unpractical. Typically setting up a cross-compiler can be time consuming and finicky and virtual machines can be tough to setup. There is however an alternative.
Zig is a programming language but, thanks to its support for C/C, it also ships with an easy-to-use cross-compiler which is of interest here even if you have no intention to write a single line of Zig code. The built-in cross-compiler allows to target many platforms easily.
Cross compilation of C code is possible by simply replacing the gcc command with zig cc and adding a target argument, e.g. for targeting a Windows. There is more general information on zig as a cross-compiler here.
Cross-compiling a JNI library is not different to compiling other libraries. To make things concrete we will cross-compile a library from a typical JNI project: JGaborator packs the C/C library gaborator. In this case the C/C code does a computationally intensive spectral transformation of time domain data. The commands below create an x86_64 Windows DLL from a macOS with zig installed:
{style="overflow-x:scroll"}
<code>
bash
#wget https://aka.ms/download-jdk/microsoft-jdk-17.0.5-windows-x64.zip#unzip microsoft-jdk-17.0.5-windows-x64.zip#export JAVA_HOME=`pwd`/jdk-17.0.5+8/
git clone --depth 1https://github.com/JorenSix/JGaborator
cd JGaborator/gaborator
echo $JAVA_HOMEJNI_INCLUDES=-I"$JAVA_HOME/include"\ -I"$JAVA_HOME/include/win32"
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC pffft/pffft.c -o pffft/pffft.o
zig cc -target x86_64-windows-gnu -c -O3 -ffast-math -fPIC -DFFTPACK_DOUBLE_PRECISION pffft/fftpack.c -o pffft/fftpack.o
zig c++ -target x86_64-windows-gnu -I"pffft" -I"gaborator-1.7"$JNI_INCLUDES -O3\
-ffast-math -DGABORATOR_USE_PFFFT -o jgaborator.dll jgaborator.cc pffft/pffft.o pffft/fftpack.o
file jgaborator.dll
# jgaborator.dll: PE32+ executable (console) x86-64, for MS Windows
</code>
Note that, when cross-compiling from macOS, to target Windows a Windows JDK is needed. The windows JDK has other header files like jni.h. Some commands to download and use the JDK are commented out in the example above. Also note that targeting Linux from macOS seems to work with the standard macOS JDK. This is probably due to shared conventions regarding compilation of libraries.
To target other platforms, e.g. ARM Linux, there are only two things that need to be changed: the -target switch should be changed to aarch64-linux-gnu and the name of the output library should be (by Linux convention) changed to libjgaborator.so. During the build step of JGaborator a list of target platforms it iterated and a total of 9 builds are packaged into a single Jar file. There is also a bit of supporting code to load the correct version of the library.
Using a GitHub action or similar CI tools this cross compilation with zig can be automated to run on a software release. For Github the Setup Zig action is practical.
Loading the correct library
In a first attempt I tried to detect the operating system and architecture of the environment to then load the library but eventually decided against this approach. Mainly because you then need to keep an exhaustive list of supporting platforms and this is difficult, error prone and decidedly not future-proof.
In my second attempt I simply try to load each precompiled library limited to the sensible ones - only dll’s on windows - until a matching one is loaded. The rationale here is that the system itself knows best which library works and failing to load a library is computationally cheap. There is some code to iterate all precompiled libraries in a JAR-file so supporting an additional platform amounts to adding a precompiled library in the JAR folder: there is no need to be explicit in the Java code about architectures or OSes.
Trying multiple libraries has an additional advantage: this allows to ship multiple versions targeting the same architecture: e.g. one with additional acceleration libraries enabled and one without. By sorting the libraries alphabetically the first, then, should be the one with acceleration and the fallback without. In the case of JGaborator for mac aarch64 there is one compiled with -framework Accelerate and one compiled by the Zig cross-compiler without.
Takehome messages
If you find yourself cross-compiling C or C for many platforms, consider the Zig cross-compiler. Even when you have no intention to write a single line of Zig code.
For JNI and Java the JGaborator source code might offer some inspiration to pre-compile and load libraries for many platforms with little effort.
CI tools can help to verify builds and automate Zig cross-compilation.
If you build for Windows make sure to include windows header-files even when there are no compilation errors using UNIX-header files.
\
\
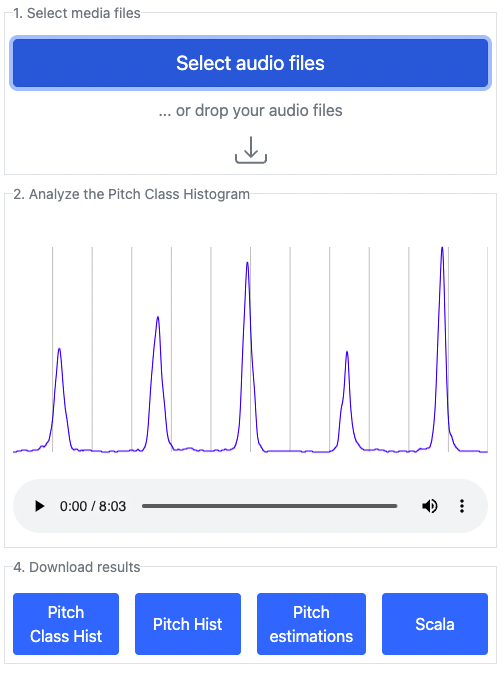
Fig: Screenshot of *Emotopa*: a browser based tool to extract pitch organization from audio.
A couple of days ago I participated in the Music Hack Day - India. The event was organized the 10th and 11th of December in Bangaluru, India. During the event a representative of Smule suggested a task to evaluate the performance of karaoke-singers in terms of intonation. The idea was to employ pitch histogram like features to estimate pitch use of singers.
I offered to build a browser based application to extract pitch histograms from audio. At the end of the hack day I presented the first release of Emotopa with some limited functionality:
Next, a pitch detector runs on the audio and returns a list of pitch estimates.
Finally a histogram (technically a kernel density estimate) is constructed using the pitch estimates.
The user can export the pitch histogram, the pitch class histogram and the pitch annotations. These features successfully show the intonation quality of singers but the applications are much broader. Some potential applications have been described in (amongst others) the Tarsos article.
The Emotopa name alludes to the Apotome browser based app where, starting from a scale you can make music. With Emotopa you do the reverse. Also very much of interest are Leimma and the rationale behind both Apotome and Leimma








 Fig: Some AI imagining audio search.
Fig: Some AI imagining audio search.



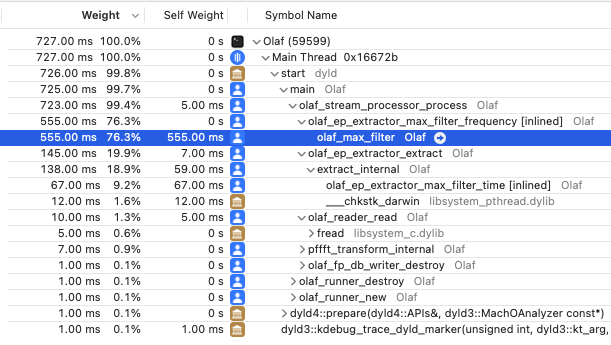 \
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.
\
Fig: The results of profiling Olaf in XCode's time profiler. Almost all time is spend in a single function which is the prime target for optimization.


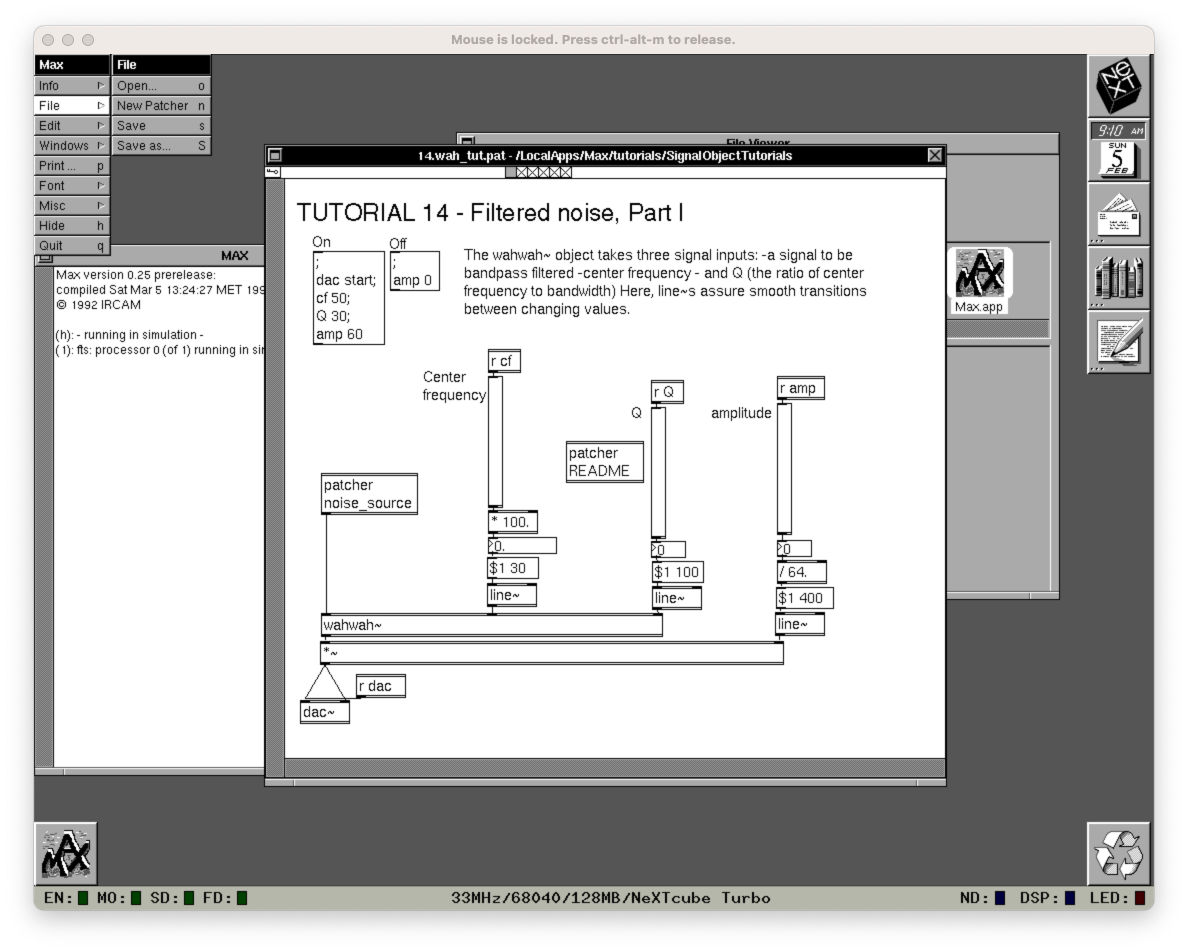 \
Fig: MAX 0.25 running in the Previous emulator on a modern MacOS system.
\
Fig: MAX 0.25 running in the Previous emulator on a modern MacOS system.


































 \
\